Virtual Program Counter (VPC) Prediction: Very Low Cost Indirect Branch Prediction Using Conditional Branch Prediction Hardware 通俗讲解¶
0. 整体创新点通俗解读¶
痛点直击 (The "Why")
- 以前的处理器处理 间接分支 (indirect branch) 非常难受,尤其是在 Java、C++ 这类面向对象语言里,因为它们到处都是 虚函数调用 (virtual function calls)。
- 传统的 BTB (Branch Target Buffer) 预测器只能记住“上次跳到哪”,但一个虚函数可能根据对象类型跳到几十个不同的地方,这种“上次有效”的假设完全失效,导致 预测准确率极低。
- 虽然学术界提出了很多更聪明的间接分支预测器(比如 TTC, Cascaded Predictor),但它们都需要 额外的、巨大的硬件存储 来存目标地址。这在芯片设计上是笔大开销,既 贵 又 耗电,所以工业界基本不用,宁愿忍受性能损失。
通俗比方 (The Analogy)
- 想象你是个图书管理员(处理器),负责给读者(CPU)快速找到书(下一条指令)。有个读者总问:“把《动物图鉴》给我。” 但这其实是个“间接请求”——他真正想要的是《动物图鉴》里的某一页,比如“老虎”、“大象”或“蚂蚁”页。
- 传统 BTB 的做法是:记住他上次要了“老虎”页,下次就直接给他“老虎”页。但如果他这次要“蚂蚁”,你就错了,还得重新找,浪费时间。
- 其他高级预测器的做法是:专门为这个读者建一个巨大的新索引柜(额外硬件),把所有他可能要的页面都记下来。效果好,但成本太高,图书馆(芯片)放不下那么多柜子。
- VPC 的巧妙之处在于:它不建新柜子,而是 复用 图书馆里已有的、为普通读者(条件分支)服务的那套高效索引系统。它把“给我《动物图鉴》”这个请求,在内部 动态地、虚拟地 拆解成一系列普通问题:“是不是要老虎?(不是)...是不是要大象?(不是)...是不是要蚂蚁?(是!)”。它用这套成熟的问答机制,来解决原本需要特殊处理的复杂请求。
关键一招 (The "How")
- 作者没有去设计一个新的、复杂的间接分支预测硬件,而是 巧妙地“欺骗”了现有的条件分支预测器。
- 核心逻辑转换:对于每一个间接分支,硬件不再把它看作一个单一的、需要预测N个目标的难题,而是 在预测阶段将其动态展开为一串虚拟的条件分支 (Virtual Branches)。
- 具体来说:
- 第一个虚拟分支的 虚拟程序计数器 (VPC) 就是原间接分支的 PC。预测器问:“跳到目标A吗?” 如果预测为 taken,就用 BTB 里 VPC 对应的目标;如果预测为 not-taken,就进入下一个虚拟分支。
- 下一个虚拟分支的 VPC 是通过 哈希(原PC, 迭代次数) 生成的一个新地址。预测器再问:“那跳到目标B吗?” 如此循环。
- 这个过程利用了现有 BTB 和方向预测器的所有能力,而目标地址就自然地分散存储在 BTB 的不同(虚拟)位置里。
- 这样一来,间接分支预测的难题就被转化成了一个序列化的条件分支预测问题,完美复用了芯片上已经存在的、高度优化的条件分支预测硬件,几乎 零成本 地获得了高性能。
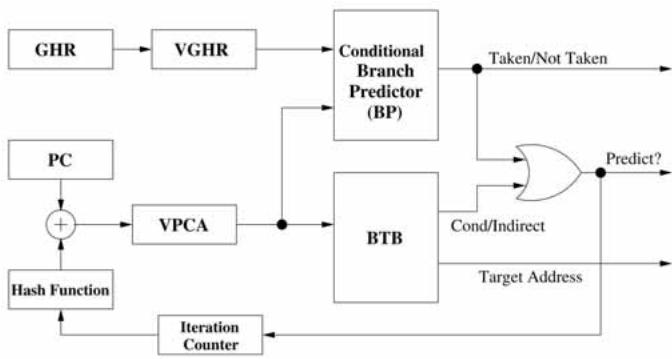 Fig. 3. High-level conceptual overview of the VPC predictor.
Fig. 3. High-level conceptual overview of the VPC predictor.
1. Virtual Program Counter (VPC) Prediction¶
痛点直击
- 传统处理器处理间接分支(indirect branch)非常难受。它不像条件分支只有“跳”或“不跳”两种选择,而是要从N个可能的目标地址里猜一个,这本质上是个高难度的多分类问题。
- 过去的解决方案要么太简陋(比如BTB只记上一次跳哪,遇到多态调用就歇菜),要么太昂贵(比如Tagged Target Cache需要额外的、巨大的专用硬件来存目标地址)。对于芯片设计来说,面积和功耗就是钱,没人愿意为一个预测器搭个新“车库”。
- 更扎心的是,现代Java/C++ 程序因为大量使用虚函数(virtual functions)和动态分派,间接分支又多又难搞,成了性能瓶颈,但硬件却没跟上。
通俗比方
- 想象你面前有一扇神秘的门(间接分支),门后有好几条路(目标地址)。你不知道该走哪条。
- 老办法是:只记住上次走的那条路(BTB),或者干脆给每条路都建个专属的岗亭和哨兵(专用预测器),成本太高。
- VPC Prediction的聪明之处在于:它不建新岗亭,而是把这扇神秘的门,在你的“大脑”(即现有的条件分支预测器)里,幻化成一排普通的、带开关的门(虚拟条件分支)。
- 你依次去推这些“虚拟门”:
- 第一扇门(虚拟PC1)问:“是去A吗?” 预测器说“否”,那就去下一扇。
- 第二扇门(虚拟PC2)问:“是去B吗?” 预测器说“是!”,好,那就走B这条路。
- 这样,你用处理简单“是/否”问题的成熟工具(条件分支预测器),巧妙地解决了复杂的“选哪个”的问题。
关键一招
- 作者并没有引入任何新的存储结构,而是对现有硬件的使用方式做了一个精妙的逻辑扭转。
- 核心转换在于:当处理器取指单元发现一条间接分支指令时,它不再把它当作一个孤立事件,而是启动一个迭代查询过程。
- 在这个过程中,硬件会为同一个间接分支动态生成多个唯一的“虚拟PC”(Virtual PC Address, VPCA)。生成方式很简单,比如
VPCA = Hash(原始PC, 迭代次数)。 - 然后,它拿着这些不同的VPCA,像查询普通条件分支一样,去访问现有的BTB和方向预测器。
- 如果预测器对某个VPCA返回“taken”,就用BTB里对应这个VPCA的地址作为预测目标。
- 如果返回“not-taken”,就用下一个VPCA继续查。
- 这个过程将一个N选1的难题,拆解成了最多MAX_ITER次的二元决策(是/否)序列。论文数据显示,81% 的正确预测在前三次迭代内就完成了,效率非常高。
- Fig. 3. High-level conceptual overview of the VPC predictor.
 Fig. 4. VPC prediction example: source, assembly, and the corresponding virtual branches.
Fig. 4. VPC prediction example: source, assembly, and the corresponding virtual branches.
2. Virtual Branch and Virtual PC (VPCA)¶
痛点直击
- 传统处理器处理 indirect branch(间接跳转)非常头疼。它不像条件分支只需猜“跳 or 不跳”,而是要猜“跳到哪”,这是一个多选题。
- 之前的做法要么是用 BTB (Branch Target Buffer) 简单地记住上次跳到哪,但这在目标频繁切换时(比如调用不同子类的虚函数)准确率极低。
- 要么就是设计一套全新的、复杂的 indirect branch predictor(如 Tagged Target Cache),但这套新硬件需要巨大的存储开销和设计复杂度,芯片厂商觉得不划算,所以大多数CPU干脆不用。
通俗比方
- 想象你是个图书管理员(处理器),负责给读者(指令流)快速找到下一本书(下一条指令)。有个读者总问:“把‘那本’书给我”,但他每次说的“那本”都指不同的书。
- 老办法1(BTB):你只记住他上一次要的是《三体》,下次他再问“那本”,你就直接给他《三体》。但如果他这次想要《流浪地球》,你就错了。
- 老办法2(专用预测器):你专门为这个爱说“那本”的读者建一个巨大的个人档案柜,记录他所有可能要的书和上下文。这很准,但太占地方,成本太高。
- VPC的妙招:你不建新档案柜,而是假装这个读者问了多个问题:“是不是要《三体》?是不是要《流浪地球》?是不是要《球状闪电》?” 这些问题在现实中不存在(所以叫 Virtual Branch),但你可以用你现有的、已经很成熟的“是/否”问题处理系统(即条件分支预测器)来挨个回答。你给每个假想的问题分配一个唯一的虚拟门牌号(VPCA),这样你的“是/否”系统就能区分它们,并为每个问题记住独立的答案和对应的书(目标地址)。
关键一招
- 作者没有去造一个昂贵的新“多选题答题机”,而是巧妙地把一个“多选题”(indirect branch)动态地、在硬件层面拆解成一系列“是/否”题(Virtual Branches)。
- 核心在于如何为这些虚构的“是/否”题生成唯一的、可区分的身份ID(VPCA),以便复用现有的条件分支预测硬件。
- 具体做法是:
- 第一个虚拟分支的VPCA就是原始的 PC(程序计数器)。
- 如果第一个被预测为“否”(not-taken),就立刻生成第二个虚拟分支,其VPCA通过对原始PC和一个预设的、与迭代次数相关的随机常量进行哈希运算得到(
VPCA = Hash(PC, iter))。 - 这个哈希操作保证了不同迭代(即不同的虚拟分支)会映射到预测结构(BTB和方向预测器)中完全不同的位置,从而可以存储和学习各自独立的目标地址和预测历史。
- 这个过程就像在一条流水线上,对同一个模糊请求,快速生成并验证多个具体的候选答案,直到有一个被预测为“是”(taken),就采用它作为最终的跳转目标。整个过程完全复用了现有硬件,几乎没有增加额外的存储成本。 Fig. 3. High-level conceptual overview of the VPC predictor.
3. Iterative Prediction and Training Algorithms¶
痛点直击
- 传统的间接分支预测器(如 BTB)假设一个间接跳转总是去同一个地方,这在现代 object-oriented 程序里完全行不通。想想一个
Shape对象的draw()方法,它可能是Circle::draw、Rectangle::draw或Triangle::draw,具体调哪个取决于运行时对象的实际类型。 - 之前更聪明的办法是搞个专门的 indirect branch predictor(比如 Tagged Target Cache),用历史信息来区分不同目标。但这玩意儿需要额外的、巨大的硬件存储来存目标地址,成本太高,功耗太大,大多数 CPU 厂商根本不愿意加。
通俗比方
- 想象你是个图书管理员(CPU),负责给读者(fetch engine)快速找到他们要的书(下一条指令)。有个读者总问:“把‘那个作者’的新书给我”,但他从不直接说作者名字(间接分支)。
- 老办法(BTB):你只记得他上次要的是《三体》,所以每次都给他《三体》。结果他这次想要《流浪地球》,你就错了。
- 新办法(专用预测器):你专门为他建一个“心愿单”小本子,记下他每次要的不同作者。但这需要额外纸张和管理精力(硬件开销)。
- VPC 的绝妙主意:你不建新本子!你利用自己已有的、超大的“热门图书借阅趋势预测表”(conditional branch predictor + BTB)。你心里把他的一次模糊请求,拆成一系列具体的、虚拟的问题:“是不是要刘慈欣的书?(虚拟分支1)”、“是不是要阿西莫夫的书?(虚拟分支2)”……
- 你按顺序问他(预测器)这些问题。只要他对任何一个问题回答“是”(taken),你就把对应的书(目标地址)给他。这个过程完全是在你脑子里完成的,读者(程序)根本不知道你问了这么多问题,他只提了一次模糊请求。
关键一招
- 作者没有为间接分支设计任何新的存储结构,而是巧妙地复用了现有的 conditional branch prediction 硬件。其核心在于 “动态虚拟化” 和 “迭代查询”。
- 预测时的关键扭转:
- 当遇到一个间接分支时,硬件并不慌,而是启动一个迭代循环。
- 在第
i次迭代中,它会生成一个虚拟的 PC 地址 (VPCA)。这个 VPCA 是通过对原始 PC 进行哈希(加上一个与迭代次数相关的随机数)得到的,确保每次迭代访问预测器的不同位置。 - 它用这个 VPCA 去查 BTB(看有没有存目标)和 方向预测器(看这个虚拟分支是不是 taken)。
- 如果方向预测器说 not-taken,就说明“不是这个目标”,于是进入下一次迭代,尝试下一个虚拟分支。
- 一旦方向预测器说 taken,就立刻用 BTB 里对应 VPCA 的地址作为预测目标,结束循环。
- Fig. 4. VPC prediction example: source, assembly, and the corresponding virtual branches.
- 训练时的关键扭转:
- 当间接分支最终执行完毕,真相大白(知道正确目标了),训练逻辑就开始工作。
- 如果预测对了:那么,在预测循环中所有被判断为 not-taken 的虚拟分支,都要被训练成 not-taken;而那个最终被选中的(taken)虚拟分支,则要被强化为 taken,并且它在 BTB 里的条目也要更新(比如提升其 LRU/LFU 优先级)。
- 如果预测错了(Wrong-target):说明正确的目标其实在 BTB 里,但对应的那个虚拟分支被错误地预测为 not-taken。训练逻辑会遍历所有虚拟分支,找到存有正确目标的那个,把它训练成 taken。
- 如果预测错了(No-target):说明正确目标压根不在 BTB 里。这时,训练逻辑会选择一个“牺牲品”——通常是某个虚拟分支对应的 BTB 条目(比如 LFU 最低的),用正确的目标地址替换掉它,并把这个新条目对应的虚拟分支训练成 taken。
- 这个训练过程保证了预测器能动态适应程序行为的变化,比如新出现了某个类的对象,也能很快学会预测。
4. Dynamic Devirtualization without Compiler Support¶
痛点直击
- 传统的 devirtualization(去虚拟化)是编译器干的活,它需要在编译时就“猜”出一个虚函数调用最可能指向哪几个具体的实现。这要求要么做复杂的whole-program analysis(全程序分析),要么依赖profiling(剖析)数据。
- 这个方法在现代软件里“很难受”,原因有三:
- 不适应变化:程序运行时的行为可能和编译时看到的完全不同,特别是对于Java这类支持dynamic class loading(动态类加载)的语言,新类可以在运行时凭空出现,编译器根本没法预测。
- 成本太高:对大型商业软件做全程序分析或精确剖析,开销巨大,很多编译器干脆就不做了,或者只处理最简单的单态(monomorphic)情况。
- 可能帮倒忙:即使猜对了,把一个间接跳转变成好几个带guard(守卫)的条件分支,虽然可能提高预测准确率,但会膨胀代码体积,甚至可能把一个错预测变成多个错预测,得不偿失。
通俗比方
- 想象一下,你(处理器)面前有一扇神秘的门(间接分支),门后有无数条路(目标地址)。以前的做法是:
- 编译器(一个事前规划师):在你出发前,根据地图(源代码)和过往经验(剖析数据),给你一张小抄,上面写着“这扇门后面90%可能是A路,10%是B路”。然后他直接在你面前放了两个岔路口(guard branches),让你选。但如果路上突然出现了C路(动态加载的新类),这张小抄就废了。
- VPC Prediction 的做法完全不同:
- 它没有事前规划师,而是给了你一个万能钥匙串(利用现有的conditional branch predictor硬件)。
- 当你走到这扇神秘门前,你并不知道后面是什么。于是你开始试钥匙:第一把钥匙(Virtual PC 1)对应A路,你问你的直觉(分支预测器):“走A路吗?” 如果直觉说“不”,你就立刻换第二把钥匙(Virtual PC 2)试试B路,如此往复。
- 这个“试钥匙”的过程完全是在你脑子里(硬件内部)完成的,外面的世界(程序代码)根本不知道你试了多少次。一旦某把钥匙打开了门(预测器说“走这条路”),你就冲进去。
- 最关键的是,每次你实际走过这扇门后,你都会更新你的直觉和钥匙串。如果这次走的是新出现的C路,你就会把C路的信息也加到你的钥匙串里,下次就能更快地找到它。这就是dynamic devirtualization without compiler support——一种完全在硬件层面、自适应的、动态的“去虚拟化”。
关键一招
- 作者并没有为间接分支设计一套全新的、昂贵的预测硬件(比如Tagged Target Cache),而是巧妙地复用了处理器里已经存在的、非常成熟的conditional branch prediction机制。
- 具体来说,他们做了一个精妙的逻辑转换:
- 将一个N-ary(多路)的间接分支目标预测问题,动态地、按需地转换成一系列binary(二元)的条件分支预测问题。
- 实现这个转换的核心是Virtual Program Counter (VPC)。对于同一个物理的间接分支指令(PC地址固定),硬件在预测时会生成多个fake PC(即VPC)。每个VPC在分支预测器眼里就是一个独立的、普通的条件分支。
- 第一个VPC就是原始PC。如果预测器对第一个VPC的预测结果是not-taken,就意味着“第一个猜测的目标不对”,于是硬件立即用一个哈希函数(
PC XOR HASHVAL[iter])生成第二个VPC,并再次查询预测器。这个过程迭代进行,直到某个VPC被预测为taken,此时与该VPC关联的BTB(Branch Target Buffer)中的目标地址就被当作最终预测结果。
- 这个设计的绝妙之处在于,目标地址的存储(在BTB里)和预测逻辑(在条件分支预测器里)都被现有的硬件结构自然地承担了,几乎没有增加额外的存储开销,只是增加了一点点控制逻辑来管理VPC的迭代。这就实现了用极低的成本,获得了接近专用复杂预测器的性能。 Fig. 3. High-level conceptual overview of the VPC predictor.
5. Low-Cost Hardware Implementation¶
痛点直击
- 传统的间接分支预测器(如 Tagged Target Cache, Cascaded Predictor)为了记住一个间接跳转可能去的多个目标地址,必须配备专用的、庞大的存储结构。这在硬件上是笔巨大的开销。
- 这种开销不仅是面积成本(Die Area),更是功耗和设计复杂度的成本。处理器前端(Fetch Unit)本就时序紧张,再塞进一个复杂的预测器,会让设计雪上加霜。
- 结果就是,很多商用处理器干脆不用这些高级预测器,而是用最简单的 BTB (Branch Target Buffer) 来对付间接分支——它只记最后一次跳转的目标。这种方法对有多目标的间接分支(比如虚函数调用)准确率极低,成了性能瓶颈。
通俗比方
- 想象你是个图书管理员(处理器),负责给读者(指令流)快速找到他们要的书(下一条指令)。有个读者总问:“把上次那本《XXX》系列的下一册给我。” 但这个系列有几十本,他每次要的都不一样。
- 老派做法(专用预测器):你专门为这个读者建一个私人书架,把他可能要的所有书都摆上去,并贴上标签。这很准,但占地方、费钱。
- BTB的做法:你太懒了,只记得他上一次拿的是哪本,每次都给他同一本。结果他经常不满意,白跑一趟。
- VPC的做法:你很聪明,没有建新书架。你利用图书馆里已有的、给其他读者用的“热门推荐”系统(Conditional Branch Predictor + BTB)。你把这个读者的问题,巧妙地转化成一系列“他要不要《A》?”、“他要不要《B》?”……的二选一问题,挨个去问那个“热门推荐”系统。一旦系统说“要!”,你就把对应的书给他。你只是复用了现有设施,没花什么额外成本。
关键一招
- 作者的核心洞察是:间接分支的多个目标,其实可以被看作是一系列互斥的“虚拟”条件分支。每个虚拟分支对应一个可能的目标地址。
- 为了解决“低成本”这个痛点,作者没有引入任何新的存储单元来存这些目标地址,而是做了以下精妙的逻辑转换:
- 复用 BTB 存储:每个“虚拟分支”都被分配一个伪造的程序计数器(Virtual PC, VPC)。这个VPC不是真实的代码地址,而是一个由原始间接分支PC和一个迭代常数哈希生成的唯一ID。这个VPC被用来在现有的BTB里索引,从而将目标地址自然地存储在BTB中。
- 复用方向预测器:预测过程变成了一个迭代查询。处理器用VPC去查BTB拿到一个目标,同时用VPC和一个虚拟的历史寄存器(VGHR)去查现有的条件分支方向预测器。如果预测器说“taken”,就采用这个目标;如果说“not-taken”,就生成下一个VPC,继续查。
- 极简硬件开销:整个机制只需要增加极少的硬件:几个寄存器(存迭代次数、当前VPC/VGHR)、一个小型硬编码的随机哈希表(用于生成不同的VPC),以及一些简单的组合逻辑。所有繁重的存储和预测工作,都交给了已经存在的、为条件分支服务的硬件。
Fig. 3. High-level conceptual overview of the VPC predictor.
这种设计的绝妙之处在于,它把一个N选1的复杂问题(预测N个可能的目标),通过迭代的方式,转化成了多次2选1的简单问题(taken or not-taken),从而完美嫁接到了成熟、高效的条件分支预测硬件上,实现了零专用存储的低成本高性能预测。