Tolerate It if You Cannot Reduce It: Handling Latency in Tiered Memory 论文解析¶
0. 论文基本信息¶
作者 (Authors): Musa Unal, Vishal Gupta, Yueyang Pan, et al.
发表期刊/会议 (Journal/Conference): HOTOS
发表年份 (Publication Year): 2025
研究机构 (Affiliations): EPFL
1. 摘要¶
目的
- 解决当前 tiered memory(分层内存)系统过度依赖 latency reduction(延迟降低,如数据迁移)而忽视 latency tolerance(延迟容忍)策略的问题。
- 论证在 CXL 等新兴异构内存架构中,prefetching(预取)作为一种延迟容忍技术的有效性与必要性,并提出一个融合两种策略的协同框架。
方法
- 提出 Linden 系统,该系统由 compiler(编译器)和 runtime(运行时)两部分组成,协同实现延迟降低与容忍。
- Compiler 负责静态分析,识别程序中的 prefetchable regions(可预取区域),并生成带有检测逻辑的插桩二进制文件。
- Runtime 负责动态决策,其核心机制包括:
- Metric monitoring: 收集 page hotness(页面热度)、编译器提供的 prefetchability hints(可预取性提示)以及硬件性能计数器(如带宽、延迟、预取效率)。
- Policy enforcement: 基于监控数据,执行三大类策略:
- Page migration: 在 DRAM 和 CXL 之间迁移页面以优化局部性。
- Hardware adaptation: 通过 MSR 寄存器动态启用/禁用特定核心的 hardware prefetchers(硬件预取器)。
- Software adaptation: 动态调整 software prefetch instructions(软件预取指令)的 prefetch distance(预取距离)或通过 JIT compilation 注入新的预取指令。
- 定义了 prefetchable region 的关键属性,包括内存区域、prefetchability ratio(可预取比率)、访问模式类型、预取目标和新鲜度。
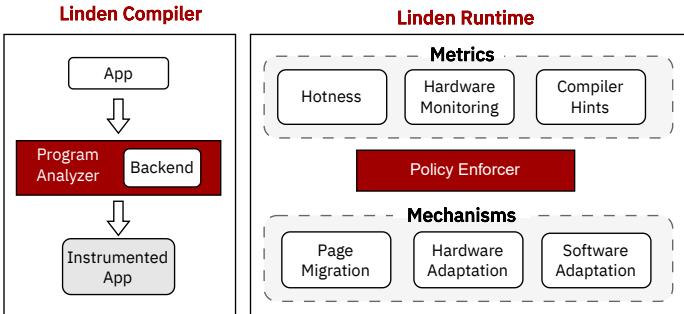
Figure 5: Linden consists of a compiler and runtime. Compiler takes a program and finds the prefetchable regions in the program. Runtime is responsible for detecting hotness, hardware monitoring, and compiler hints to enforce different policies. Runtime able to migrate pages between the tiers, enable/disable hardware prefetchers and change the software behavior in terms prefetchability.
结果
- 硬件预取的局限性:在 CXL 内存上,由于其 带宽远低于 DRAM(46 GB/s vs. 271 GB/s),激进的硬件预取会导致严重的 bandwidth contention(带宽争用),在高负载下使延迟飙升至 1,500 ns,性能反而下降 19%。
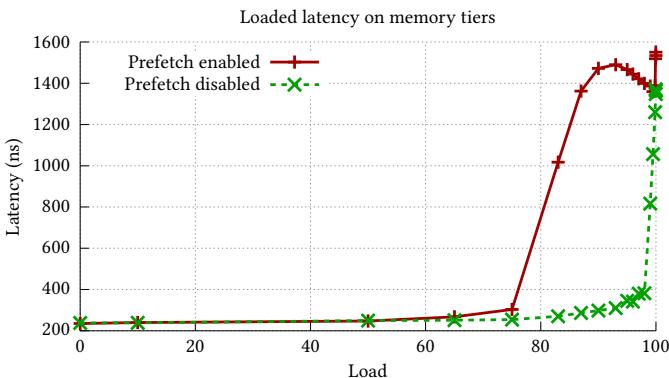
Figure 3: Under high load, prefetching causes latency to increase dramatically at lower loads compared to when prefetching is disabled, resulting in up to 6.3× higher latency.
- 软件预取的关键参数:DRAM 和 CXL 因延迟不同(112 ns vs. 237 ns),需要不同的最优 prefetch distance。实验表明,对于扫描操作,DRAM 最优距离为 4,而 CXL 需要更长的 7。
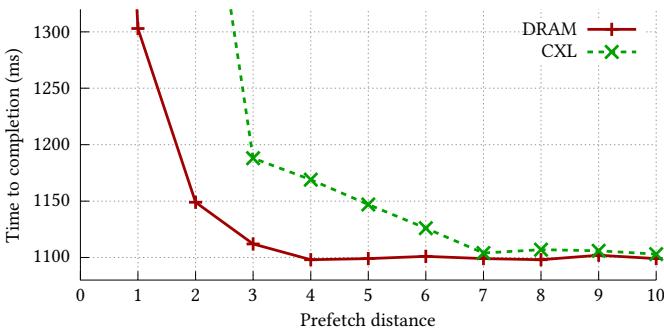
Figure 4: DRAM and CXL have different optimal prefetch distances. For example, in the scan microbenchmark, DRAM performs best with a prefetch distance of 4, while CXL requires a longer distance of 7 due to its higher latency.
- Linden 策略的有效性:提出的“tolerate if you cannot reduce”(若无法降低则容忍)策略,在特定微基准测试中,将热点且可预取的数据主动迁移到慢速 CXL 层,利用预取隐藏延迟,反而获得了 7% 的性能提升。
结论
- 一个高效的分层内存系统必须同时采用 latency reduction 和 latency tolerance 两种策略,而非仅依赖数据迁移。
- 传统的、为同构 DRAM 设计的预取技术(尤其是硬件预取)在 CXL 等带宽受限的异构内存上可能失效甚至有害。
- Linden 通过编译器-运行时协同设计,能够动态、智能地管理预取行为(如调整距离、选择性开关),从而有效利用预取来容忍 CXL 的高延迟,为未来高性能分层内存系统提供了新的设计范式。
2. 背景知识与核心贡献¶
研究背景
- 现代数据中心中,内存已成为关键瓶颈,**CXL (Compute Express Link) 等互连技术催生了由本地 DRAM **(低延迟、高带宽) 和 **CXL-attached memory (高延迟、低带宽) 构成的tiered memory **(分层内存) 系统。
- 当前的分层内存系统主要通过**page migration (页面迁移) 策略来reduce latency **(降低延迟),即根据数据访问热度(hotness)在快慢存储层之间动态迁移页面,以提升数据局部性。
- 传统的**latency tolerance (延迟容忍) 技术,如prefetching **(预取),在同构内存(如纯DRAM)中已被证明有效,但直接应用于异构的分层内存系统时面临新挑战。
研究动机
- 现有系统过度依赖“降低延迟”策略,忽视了“容忍延迟”的潜力。一个高效的系统应同时集成 latency reduction 和 latency tolerance。
- 实验发现,将传统预取器直接用于 CXL 内存会导致性能问题:
- 硬件预取器在多核高负载下会因 CXL 的有限带宽(仅为 DRAM 的 ~1/6)引发严重**contention **(争用),导致延迟飙升。
Figure 3: Under high load, prefetching causes latency to increase dramatically at lower loads compared to when prefetching is disabled, resulting in up to 6.3× higher latency.
显示,在高线程数下,硬件预取甚至会使 CXL 性能下降 19%。 - 软件预取器的**prefetch distance **(预取距离) 需要针对不同内存层级进行调整。
Figure 4: DRAM and CXL have different optimal prefetch distances. For example, in the scan microbenchmark, DRAM performs best with a prefetch distance of 4, while CXL requires a longer distance of 7 due to its higher latency.
表明,CXL 因其更高延迟,需要比 DRAM 更长的预取距离(例如 7 vs 4)才能有效隐藏延迟。
- 因此,亟需一种能协同管理“降低”与“容忍”策略的新型系统。
核心贡献
- 提出 Linden 系统,一个协同编译器与运行时的框架,旨在通过**Reduce **(迁移) 和 **Tolerate **(预取) 双管齐下来优化分层内存性能。
Figure 5: Linden consists of a compiler and runtime. Compiler takes a program and finds the prefetchable regions in the program. Runtime is responsible for detecting hotness, hardware monitoring, and compiler hints to enforce different policies. Runtime able to migrate pages between the tiers, enable/disable hardware prefetchers and change the software behavior in terms prefetchability.
- Linden Compiler: 负责静态分析程序,识别并标记**prefetchable regions **(可预取区域),这些区域具有可预测的访问模式(如 stride、sequential)。
- Linden Runtime: 动态监控系统状态(如页面热度、硬件争用),并基于编译器提供的信息执行精细化策略:
- Reduce: 执行传统的页面迁移以提升局部性。
- Tolerate: 动态调整预取行为,包括:
- 根据内存层级动态修改软件预取距离。
- 在 CXL 层出现带宽争用时,选择性地关闭特定核心的硬件预取器,而非全局关闭。
- 提出创新策略,例如对于hot and prefetchable的数据,可以将其主动迁移到慢速的 CXL 层,因为预取器足以隐藏其访问延迟,从而为真正无法容忍延迟的热点数据腾出宝贵的 DRAM 空间。
3. 核心技术和实现细节¶
0. 技术架构概览¶
整体技术架构
本文提出的 Linden 系统是一个协同的软硬件架构,旨在通过结合 latency reduction(延迟降低)和 latency tolerance(延迟容忍)两种策略来优化 tiered memory(分层内存)系统的性能。其核心架构由一个 compiler(编译器)和一个 runtime(运行时)系统组成。
Figure 5: Linden consists of a compiler and runtime. Compiler takes a program and finds the prefetchable regions in the program. Runtime is responsible for detecting hotness, hardware monitoring, and compiler hints to enforce different policies. Runtime able to migrate pages between the tiers, enable/disable hardware prefetchers and change the software behavior in terms prefetchability.
-
Compiler (编译器)
- 负责在编译期静态分析应用程序源代码,识别出 prefetchable regions(可预取区域)。
- 通过插入特定的 helper functions 对程序进行 instrumentation(插桩),以便在运行时向 runtime 传递关键信息。
- 传递的信息包括:访问线程 ID、内存区域标识符 (region)、检测到的访问模式类型 (pattern) 等,用于构建 prefetchability table(可预取性表)。
- 支持多种后端分析技术,例如专门的 compiler passes 或 machine learning 方法。
-
Runtime (运行时)
- 是整个架构的决策和执行中心,负责动态监控系统状态并执行相应的优化策略。
- 其工作流程分为两个主要部分:metric monitoring(指标监控)和 policy enforcement(策略执行)。
- Metric Monitoring (指标监控)
- Hotness: 使用 Intel PEBS 或 page table scanning 等技术追踪页面的访问热度。
- Compiler Hints: 接收来自编译器插桩代码的信息,构建和维护 prefetchability table。
- Metric Monitoring (指标监控)
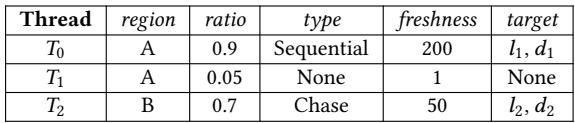
Table 1: An example of a prefetchability table.
- Hardware Monitoring: 通过硬件性能计数器采样,监控三类关键指标:
- 预取器相关计数器(如 L2_RQSTS.ALL_HWPF, L2_LINES_OUT.USELESS_HWPF)。
- 各内存层级的 bandwidth 和 latency。
- 各层级的 congestion indicators(拥塞指标)。
- Policy Enforcement (策略执行)
- 基于监控到的指标,通过三种核心机制来执行 Reduce(减少延迟)和 Tolerate(容忍延迟)两类策略:
- Page Migration: 在 DRAM 和 CXL 等内存层级之间迁移页面,以提升数据局部性。
- Hardware Adaptation: 通过 MSR registers 动态地为特定核心 enable/disable 硬件预取器(如 stream, stride),以避免在 CXL 上因带宽争用导致的性能下降。
- Software Adaptation: 动态调整软件预取行为,包括:
- 修改 prefetch distance(预取距离)以适应不同内存层级的延迟特性(例如,DRAM 最优距离为 4,而 CXL 为 7)。
- 基于监控到的指标,通过三种核心机制来执行 Reduce(减少延迟)和 Tolerate(容忍延迟)两类策略:
Figure 4: DRAM and CXL have different optimal prefetch distances. For example, in the scan microbenchmark, DRAM performs best with a prefetch distance of 4, while CXL requires a longer distance of 7 due to its higher latency.
核心设计原则
- 协同优化: Linden 的核心思想是将传统的 page migration(页面迁移)策略与 data prefetching(数据预取)策略紧密结合,而非孤立看待。
- 动态适应: 系统能够根据实时的硬件状态(如 contention)和数据访问模式,动态调整其行为。例如,在高争用时,对 CXL 访问保守化或关闭硬件预取,同时保持对 DRAM 的预取。
- Tier-Awareness: 所有决策(尤其是预取)都是 tier-aware(层级感知)的,能够根据数据当前所在的内存层级(DRAM 或 CXL)调整其参数和策略。
1. Prefetchable Regions¶
Prefetchable Regions 的定义与核心属性
- Prefetchable Region 被定义为一组(可能非连续的)memory pages,这些页面被特定线程以相似且可预测的访问模式进行访问。
- 其核心目标是通过发出准确 (accurate) 且及时 (timely) 的预取请求,来隐藏该区域内所有内存加载 (loads) 的访问延迟。
- 每个 Prefetchable Region 由以下关键属性刻画:
- Memory region (region): 共享相似访问模式的页面列表。其大小是可配置的,需要在instrumentation 开销和预测准确性之间做权衡。
- Prefetchability ratio (ratio): 一个介于 0 到 1 之间的量化指标,用于衡量该区域内有多少比例的加载延迟可以通过有效的预取被隐藏。可预测性越强的访问模式(如顺序扫描),该比率越高。
- Type of access pattern (pattern): 描述区域内的具体访问行为。简单的模式(如 next line, stride)可由硬件或软件预取器处理;而复杂的不规则 (irregular) 或时间局部性 (temporal) 模式则通常需要software prefetch instructions。
- Target (target): 明确指定预取指令的目标,包括预取地址和最关键的prefetch distance。这个信息使得系统能在内存延迟变化时(如页面迁移后)动态调整预取时机。
- Freshness (freshness): 一个时效性指标,记录自上次更新该区域信息后经过的时间。当它超过用户定义的阈值时,该区域的信息可能被视为过期,从而触发重新评估或不同的调度策略。
Table 1: An example of a prefetchability table.
检测机制:编译时与运行时协同
- Prefetchable Regions 的检测依赖于 Linden compiler 和 Linden runtime 的协同工作。
- Compiler Support (源码可用时):
- 编译器作为前端,利用可插拔的后端(如专用编译器 Pass 或 machine learning 模型)静态分析程序,识别潜在的可预取区域(例如,循环中的规律性访问)。
- 编译器会对程序进行instrumentation,插入辅助函数。这些函数在运行时被调用,向 Runtime 传递关键信息:thread ID, region ID, 和 pattern type。
- 这些信息是构建和维护 prefetchability table(如上图所示)的基础。
- Hardware Sampling (源码不可用时):
- 当无法进行编译时插桩时,Runtime 会退化到使用hardware performance counters(如 Intel PEBS)进行采样。
- 通过监控硬件预取器的有效性(例如,有用 vs. 无用的预取请求数),Runtime 可以动态推断出哪些内存页区域是“可预取的”。
- 此外,just-in-time (JIT) compilation 技术也可用于在运行时动态注入软件预取指令。
在 Linden 系统中的作用与输入输出关系
- 输入:
- 来自编译器的 instrumentation hints(包含 region, pattern, thread 等信息)。
- 来自硬件监控单元的 hotness metrics(页面热度)和 contention metrics(如带宽利用率、无用预取计数)。
- 处理:
- Runtime 将上述输入整合,为每个 Prefetchable Region 计算并维护其完整的属性集(ratio, target, freshness 等),形成 prefetchability table。
- 这个表格是 Policy Enforcer 做出决策的核心依据。
- 输出/作用:
- 指导 Page Migration: 对于高热度且高 prefetchability ratio 的区域,系统甚至可以考虑将其主动迁移到慢速 tier(如 CXL),因为预取器足以隐藏其延迟,从而为真正无法容忍延迟的热数据腾出快速 tier(DRAM)空间。
- 动态调整预取策略:
- 根据 pattern 类型,决定启用硬件预取还是依赖软件预取。
- 根据 target 中的 prefetch distance 和当前页面所在的 tier,动态修正软件预取指令的距离。例如,当页面从 DRAM 迁移到 CXL 时,预取距离需从 4 增加到 7 以匹配更高的延迟。
- 在高带宽争用时,利用 region-to-core 的映射关系,选择性地为访问慢速 tier 的核心关闭硬件预取器,避免全局性能下降。
- 实现 “Tolerate if You Cannot Reduce It” 的核心理念: Prefetchable Regions 的概念将“延迟容忍”从一个被动的、全局的硬件特性,转变为一个主动的、细粒度的、可被系统策略精确管理的资源。
2. Linden Compiler¶
Linden Compiler 的核心职责与实现原理
- Linden Compiler 的主要任务是静态分析应用程序的源代码,以识别出其中具有可预测访问模式的内存区域,并将其标记为 prefetchable regions(可预取区域)。
- 其核心思想是将编译时的静态分析能力与运行时的动态决策能力相结合,为 Linden Runtime 提供精准的预取指导信息。
算法流程与关键组件
- 输入: 应用程序的源代码。
- 处理流程:
- 采用 pluggable backends(可插拔后端)架构进行数据访问模式分析。这些后端可以是:
- 传统的编译器优化 Pass:例如,专门用于检测循环内步长 (stride) 访问或顺序扫描 (sequential scan) 的分析模块,类似于文献 [4, 28] 中的技术。
- 基于机器学习 (ML) 的方法:利用 ML 模型来识别更复杂的、非规则的但依然可预测的访问模式,以期获得更高的 prefetchability ratio(预取率),尽管这会增加编译时间开销。
- 一旦检测到一个潜在的 prefetchable region,编译器不会直接插入固定的预取指令,而是进行二进制插桩 (instrumentation)。
- 插桩的具体操作是在程序的关键位置(如循环入口、函数调用点)插入特定的 helper functions(辅助函数)。
- 采用 pluggable backends(可插拔后端)架构进行数据访问模式分析。这些后端可以是:
- 输出: 一个经过插桩修改的二进制文件。该二进制文件在运行时能够主动向 Linden Runtime 报告以下关键信息:
- 执行线程的 thread ID。
- 被访问内存区域的唯一标识符 region。
- 检测到的访问模式类型 (pattern),例如 "next line", "stride", 或 "irregular"。
参数设置与设计权衡
- Region Size (区域大小): 这是一个可配置的参数。区域划分过小会导致插桩开销过大和 prefetchability table 条目过多;区域过大则可能包含多种访问模式,降低 prefetchability ratio 的准确性。
- Backend Selection (后端选择): 在 coverage(覆盖率/识别能力)和 compilation time(编译时间)之间存在权衡。简单的 stride 分析速度快但覆盖有限,而 ML 方法覆盖广但耗时长。
在 Linden 整体架构中的作用
- Linden Compiler 是整个系统实现 “Tolerate It if You Cannot Reduce It” 理念的第一步。它负责提供高质量的、应用语义层面的预取可行性洞察。
- 它生成的插桩代码是 Compiler-Runtime 协同的桥梁。Runtime 依赖这些信息来构建和维护 prefetchability table(如 Table 1 所示),这是后续所有动态策略(如调整预取距离、选择性启用硬件预取器)的基础。
- 通过将复杂的模式识别工作放在编译时完成,Runtime 可以避免昂贵的在线分析,从而专注于根据实时硬件状态(如带宽争用、页面热度)做出快速、高效的调度决策。
Table 1: An example of a prefetchability table.
备选方案:无源码场景
- 当应用程序源代码不可用时,Linden Compiler 无法工作。此时,系统会退化到由 Linden Runtime 通过 hardware sampling(硬件采样)来动态推断预取区域,但这通常不如编译时分析精准。
3. Linden Runtime¶
Linden Runtime 的核心架构与输入
Linden Runtime 是一个动态决策引擎,其目标是协同运用 latency reduction(通过数据迁移)和 latency tolerance(通过预取)两种策略来优化分层内存性能。它的决策依据来自三个关键输入源:
- Compiler hints: 来自 Linden 编译器的指令,用于构建 prefetchability table(如 Table 1 所示),其中包含内存区域的 region, ratio, pattern, target, 和 freshness 等属性。
- Page hotness metrics: 通过 Intel PEBS 或 page table scanning 等技术收集的页面访问热度信息,用于传统的数据迁移决策。
- Hardware monitoring statistics: 实时采样的硬件性能计数器,主要包括三类:
- Prefetcher 相关计数器(如
L2_RQSTS.ALL_HWPF,L2_LINES_OUT.USELESS_HWPF)。 - 各内存层级(DRAM/CXL)的 bandwidth 和 latency 测量值。
- 针对不同层级的 congestion indicators(拥塞指标)。
- Prefetcher 相关计数器(如
Figure 5: Linden consists of a compiler and runtime. Compiler takes a program and finds the prefetchable regions in the program. Runtime is responsible for detecting hotness, hardware monitoring, and compiler hints to enforce different policies. Runtime able to migrate pages between the tiers, enable/disable hardware prefetchers and change the software behavior in terms prefetchability.
核心执行机制
基于上述输入,Runtime 通过三大执行机制来实施其策略:
- Page migration: 在后台异步地提升(promote)或降级(demote)页面,以优化数据局部性。此机制复用现有方案(如 Memtis)以避免性能抖动。
- Hardware adaptation: 通过写入 MSR registers 来对特定 CPU 核心精细地启用或禁用硬件预取器(如 stream, stride prefetchers),防止在带宽受限的 CXL 上因过度预取而引发拥塞。
- Software adaptation: 动态调整由编译器插入的软件预取指令,具体方式有两种:
- 修改 prefetch distance: 根据数据所在内存层级的延迟特性,将预取指令在指令流中前移或后移。
- 注入新预取指令: 利用 JIT compilation 技术,在运行时动态生成新的预取指令。
动态策略执行流程
Runtime 的策略执行逻辑体现在其 Policy Enforcer 中,其核心算法如 Listing 1 所示,主要遵循“先尝试减少延迟,若无法有效减少则尝试容忍”的原则,并根据硬件状态动态调整。
-
Improve performance (tolerate if you cannot reduce):
- 传统系统会将 hot 数据保留在快速 tier(DRAM)。
- Linden 的创新在于,对于同时满足 hot 和 prefetchable 的区域,即使将其迁移到慢速 tier(CXL),也可以通过有效的预取来隐藏延迟。
- 微基准测试表明,此策略在特定场景下可带来 7% 的性能提升。
-
Control throttling (do not tolerate every time):
- 当检测到内存子系统(特别是 CXL tier)出现高拥塞时,Runtime 不会全局关闭预取。
- 它利用 prefetchability table 中记录的线程与内存区域的映射关系,选择性地仅为访问慢速 tier 的核心禁用硬件预取器。
- 同时,对软件预取采取更保守的策略,以缓解 bandwidth contention。
-
Control timeliness (tolerate when there is some time):
- 该策略解决了分层内存中 prefetch distance 动态变化的核心挑战。
- 当一个包含软件预取指令的页面被迁移至不同 tier 时,Runtime 会响应式地(reactively)更新其预取距离。
- 例如,当数据从 DRAM 迁移到 CXL 时,预取距离会从 4 调整为 7,以匹配 CXL 更高的延迟(如 Figure 4 所示)。
- 此操作可通过 JIT 技术实现,确保预取的 timeliness。
Figure 4: DRAM and CXL have different optimal prefetch distances. For example, in the scan microbenchmark, DRAM performs best with a prefetch distance of 4, while CXL requires a longer distance of 7 due to its higher latency.
在整体系统中的作用
Linden Runtime 是连接静态编译分析与动态系统状态的桥梁。它将编译器提供的、关于程序行为的前瞻性知识(prefetchability)与运行时收集的实时系统状态(hotness, congestion)相结合,打破了传统内存分层系统仅依赖数据迁移的局限。通过动态控制预取行为,Runtime 能够主动 tolerate 无法通过迁移消除的延迟,从而在 CXL 等高延迟、低带宽的内存 tier 上实现更优的性能表现。其最终输出是一系列对底层硬件和操作系统机制(迁移、MSR、JIT)的精确调用,以实现端到端的延迟优化。
4. Tier-Aware Prefetch Distance Adaptation¶
核心机制与实现原理
- Linden 的 Tier-Aware Prefetch Distance Adaptation 机制旨在解决因 page migration 导致的 prefetch timeliness 失效问题。当一个包含软件预取指令的数据页在 DRAM 和 CXL 之间迁移时,其访问延迟发生显著变化(从 112 ns 变为 237 ns),原有的固定预取距离不再适用。
- 该机制的核心是将 prefetch distance 与数据当前所在的 memory tier 动态绑定,确保预取请求有足够的时间在数据被实际使用前完成加载,从而有效 hide latency。
算法流程与触发条件
- 该机制由 Linden runtime 驱动,其工作流程如下:
- 监控阶段: Runtime 持续监控 page migration events。当一个被标记为 prefetchable 的页面发生迁移(例如,从 DRAM demote 到 CXL)时,会触发回调。
- 查询与决策阶段: Runtime 根据迁移事件,查询内部维护的 prefetchability table (见 Table 1),获取与该页面关联的 software prefetch instruction(s) 及其当前的 prefetch distance。
- 动态调整阶段: Runtime 根据目标 tier 的特性,计算并应用新的、最优的 prefetch distance。
- 若数据迁移到 CXL,则将距离增大(例如,从 4 增至 7)。
- 若数据迁回到 DRAM,则将距离减小(例如,从 7 减至 4)。
- 执行阶段: 通过 JIT (Just-In-Time) compilation 技术,在运行时直接修改程序指令流中的预取指令参数,实现距离的即时更新。
Figure 4: DRAM and CXL have different optimal prefetch distances. For example, in the scan microbenchmark, DRAM performs best with a prefetch distance of 4, while CXL requires a longer distance of 7 due to its higher latency.
关键参数与配置
- 最优 prefetch distance 是通过微基准测试(microbenchmark)预先确定的,并作为系统配置的一部分。文档中给出的具体数值如下:
| Memory Tier | Idle Latency | Optimal Prefetch Distance |
|---|---|---|
| DRAM | 112 ns | 4 |
| CXL | 237 ns | 7 |
- 这些参数并非绝对固定,未来可通过更精细的在线学习或硬件性能计数器反馈进行自适应调整。
输入输出关系及系统作用
- 输入:
- Page migration events: 来自内存管理子系统的信号,指示特定页面已迁移至新 tier。
- Prefetchability table: 由 Linden compiler 在编译期生成,并由 runtime 维护,包含每个可预取区域的元数据(如 region, target, pattern)。
- Tier-specific latency profile: 系统对各内存 tier 延迟特性的预设或动态测量值。
- 输出:
- Modified software prefetch instructions: 通过 JIT 修改后的、带有新 prefetch distance 的指令,直接作用于 CPU 执行流。
- 在 Linden 整体架构中的作用:
- 该机制是 “Tolerate” 策略的关键组成部分,与 “Reduce” 策略(即 page migration)形成闭环协同。
- 它确保了即使在数据被主动迁移到慢速 tier 以优化全局资源利用的情况下,对于具有高 prefetchability ratio 的区域,其访问性能依然能通过精准的预取得到保障,从而实现了论文核心思想 “Tolerate It if You Cannot Reduce It”。
5. Selective Hardware Prefetcher Control¶
核心观点
Linden 的 Selective Hardware Prefetcher Control 机制旨在解决传统全局开关硬件预取器(Hardware Prefetcher)策略在 Tiered Memory 系统中的不足。其核心思想是,不因慢速内存(如 CXL)的带宽瓶颈而牺牲快速内存(如 DRAM)上运行线程的性能,而是进行精细化、按核(per-core)的动态控制。
- 问题根源: 如 §2.1 所述,CXL 的带宽(46 GB/s)远低于 DRAM(271 GB/s)。当多个核心并发访问 CXL 时,激进的硬件预取会产生大量冗余请求,导致 CXL link contention,使延迟飙升至 1,500 ns(见 Figure 3),反而损害性能。
- 传统方案缺陷: 现有系统(如论文中提到的 Limoncello)通常采用全局策略,在检测到高内存负载时,直接禁用所有核心的硬件预取器。这会导致访问 DRAM 的线程也无法受益于预取,造成 suboptimal performance。
- Linden 的创新: Linden 通过将 硬件监控、编译器提示 和 运行时元数据 相结合,实现了对不同核心的差异化管理。
实现原理与算法流程
该机制的实现依赖于 Linden Runtime 的 Metric Monitoring 和 Policy Enforcer 模块协同工作。
-
输入数据:
- 硬件监控指标: 通过 Performance Monitoring Units (PMUs) 采集以下关键计数器:
L2_RQSTS.ALL_HWPF: L2 缓存接收到的所有硬件预取请求数。L2_LINES_OUT.USELESS_HWPF: 被认为无用的硬件预取行数(即在被使用前就被驱逐)。- 各内存层级(DRAM, CXL)的 带宽利用率 和 延迟。
- 编译器提示: 来自 Prefetchability Table(见 Table 1)的信息,明确指出哪些 thread 正在访问哪些 memory region,以及这些区域位于哪个内存层级。
- 页面迁移日志: Runtime 自身维护的页面在 DRAM 和 CXL 之间的迁移记录,用于动态更新线程与内存层级的映射关系。
- 硬件监控指标: 通过 Performance Monitoring Units (PMUs) 采集以下关键计数器:
-
决策与执行流程 (
Listing 1中的tolerate方法体现此逻辑):- 检测拥塞: Runtime 持续监控 CXL 层级的带宽和延迟指标。当指标超过预设阈值(例如,带宽利用率 > 80% 或延迟增长超过 2 倍),判定 CXL tier 处于 high contention 状态。
- 关联线程与层级: 利用 Prefetchability Table 和页面迁移信息,Runtime 精确识别出当前正在访问 CXL 内存页的所有 core/thread。
- 选择性禁用: 通过写入特定的 Model-Specific Registers (MSRs),Runtime 仅对步骤 2 中识别出的那些核心,禁用其 stream 和 stride 硬件预取器。
- 保留快速路径: 对于访问 DRAM 的核心,其硬件预取器保持启用状态,确保它们能继续从预取中获益,维持高性能。
- 动态调整: 当 CXL 的拥塞状况缓解后,Runtime 会重新启用之前被禁用的核心的硬件预取器。
Figure 5: Linden consists of a compiler and runtime. Compiler takes a program and finds the prefetchable regions in the program. Runtime is responsible for detecting hotness, hardware monitoring, and compiler hints to enforce different policies. Runtime able to migrate pages between the tiers, enable/disable hardware prefetchers and change the software behavior in terms prefetchability.
参数设置与关键指标
该机制的有效性依赖于几个关键参数和指标的合理设定。
| 类别 | 参数/指标 | 说明 |
|---|---|---|
| 拥塞阈值 | CXL 带宽利用率 | 触发选择性禁用的临界点,需根据具体硬件(如 CXL 2.0 的 46 GB/s)进行校准。 |
| CXL 访问延迟 | 辅助判断指标,当延迟因预取而急剧上升(如 Figure 3 所示)时,可作为强信号。 | |
| 监控开销 | PMU 采样频率 | 为平衡监控开销与响应速度,Linden 计划采用类似 Memtis 的动态调整策略。 |
| 控制粒度 | Core-level MSR | 控制单元是 per-core,这是实现选择性的基础,依赖于现代 CPU 架构的支持。 |
在整体系统中的作用
Selective Hardware Prefetcher Control 是 Linden “Tolerate if You Cannot Reduce It” 核心理念的关键执行组件之一。
- 与“Reduce”策略协同: 它并不取代页面迁移(page migration)等“Reduce”策略,而是在“Reduce”无法完全解决问题时(例如,热点数据因容量限制必须部分驻留在 CXL)提供补充。它确保了即使数据在慢速层,系统也能以最优化的方式去容忍其延迟。
- 保障性能隔离: 该机制有效实现了 fast-tier 和 slow-tier 访问之间的 performance isolation,防止慢速设备的瓶颈拖累整个系统的性能,这对于多租户或混合工作负载的数据中心环境至关重要。
- 支撑高级策略: 它是实现论文 §3.4 中 “Control throttling (do not tolerate every time)” 策略的具体技术手段,使得 Linden 能够根据实时硬件状态,智能地决定何时、何地进行预取容忍。
4. 实验方法与实验结果¶
实验设置
- 硬件平台: 实验基于一个包含本地 DRAM 和 CXL-attached memory (CXL 2.0) 的系统。
- DRAM: 空闲延迟 112 ns, 带宽 271 GB/s。
- CXL: 空闲延迟 237 ns, 带宽 46 GB/s (约为 DRAM 带宽的 1/5.9)。
- 基准测试套件: 主要使用 GAP benchmark suite 来评估硬件预取效果,并针对特定场景(如多核扩展性、预取距离)设计了自定义微基准测试(microbenchmark)。
- 预取机制对比:
- 硬件预取: 评估系统默认的硬件预取器在 DRAM 和 CXL 上的表现。
- 软件预取: 通过编译器插入软件预取指令,并手动调整 prefetch distance (预取距离) 来测试其在不同内存层级上的最优值。
- 控制变量: 在测试软件预取距离时,禁用了硬件预取,以隔离变量。
结果数据
- 硬件预取效果:
- 在 DRAM 上,20个应用中有18个受益,平均加速比为 1.47×。
- 在 CXL 上,20个应用中有17个受益,但平均加速比降至 1.26×,并且观察到最高达 19% 的性能下降。
- 多核扩展性: 随着 CPU 核心数增加,硬件预取在 CXL 上的效果急剧恶化,最终导致性能损失。
Figure 2: When the number of threads increases the prefetching effectiveness of CXL decreases while DRAM being constant, and for high number of threads prefetching hurts the performance on CXL.
- 带宽争用影响: 在高负载下,硬件预取会因 CXL 有限的带宽而引发严重争用,导致访问延迟飙升至 1,500 ns,是关闭预取时的 6.3×。
Figure 3: Under high load, prefetching causes latency to increase dramatically at lower loads compared to when prefetching is disabled, resulting in up to 6.3× higher latency.
- 软件预取效果:
- 最优预取距离: 实验发现 DRAM 和 CXL 的最优预取距离不同。对于扫描微基准,DRAM 的最优距离为 4,而 CXL 因其更高延迟,需要更长的距离 7 才能有效隐藏延迟。
Figure 4: DRAM and CXL have different optimal prefetch distances. For example, in the scan microbenchmark, DRAM performs best with a prefetch distance of 4, while CXL requires a longer distance of 7 due to its higher latency.
- Linden 策略验证:
- “无法减少则容忍”策略: 在一个混合分配(5GB DRAM + 5GB CXL)的微基准中,将 hot and prefetchable 的区域主动迁移到 CXL 慢层,反而获得了最高 7% 的性能提升,证明了容忍策略的有效性。
消融实验
论文虽未明确标注“消融实验”章节,但其实验设计和结果分析包含了典型的消融思想,用于验证各个组件和假设的必要性。
-
硬件预取的负面影响验证:
- 通过对比开启/关闭硬件预取在 CXL 上的性能,直接证明了在带宽受限的慢层上,无差别启用硬件预取是有害的。这是对现有系统默认行为的一个关键消融。
-
预取距离敏感性分析:
- 通过系统地改变软件预取距离(从1到16),并分别在 DRAM 和 CXL 上测量性能,验证了 tier-aware prefetch distance 的必要性。该实验消融了“使用统一预取距离”的假设,证明了动态调整距离的重要性。
-
带宽争用归因实验:
- 使用 Intel MLC 工具在不同负载下测量延迟,将性能下降明确归因于 prefetch-induced bandwidth contention,而非其他因素。这消融了性能下降可能由其他原因(如缓存污染)导致的可能性。
-
Linden 策略有效性验证:
- 提出的三种策略(容忍、节流、及时性控制)都通过具体的微基准或场景进行了验证。例如,“无法减少则容忍”策略通过主动迁移 hot/prefetchable 页面到慢层并观察到性能增益,消融了“所有热数据都必须在快层”的传统观念。