Tolerate It if You Cannot Reduce It: Handling Latency in Tiered Memory 通俗讲解¶
0. 整体创新点通俗解读¶
痛点直击 (The "Why")
当前的 tiered memory(分层内存)系统,比如结合了本地 DRAM 和 CXL-attached memory 的架构,面临一个根本性的思维盲区:它们只想着“减少延迟”(Reduce Latency),也就是通过把热数据迁移到快 tier 来解决问题。这个思路本身没错,但它忽略了一个关键事实——不是所有延迟都值得或能够被消除。
- 在 CXL 这种高延迟、低带宽的慢 tier 上,盲目迁移会带来巨大开销。更糟的是,现有的 hardware prefetcher(硬件预取器)是为同构 DRAM 设计的,在 CXL 上会因为带宽瓶颈而疯狂制造 contention(争用),反而让延迟飙升到 1500ns(见 Figure 3),性能直接崩盘。
- 同时,software prefetching(软件预取)如果沿用 DRAM 的策略,也会失效。因为 CXL 的延迟几乎是 DRAM 的 2.1 倍(237ns vs 112ns),但预取距离却没变,导致数据要么来得太晚(没藏住延迟),要么来得太早(被 cache evict 掉)。
- 所以,问题的核心在于:系统只有“迁移”这一招,缺乏“容忍”延迟的第二条腿。当数据因为各种原因(比如容量限制、迁移开销)不得不留在慢 tier 时,系统就束手无策了。
通俗比方 (The Analogy)
想象你管理一个大型仓库,有近区(快,但小)和远区(慢,但大)两个库房。
- 传统做法就像一个固执的仓库经理,他坚信:“所有热销品必须放近区!”于是他不停地把货搬来搬去。但搬运本身要花时间、占通道,有时候搬着搬去,发现近区满了,或者搬运的车堵在路上(带宽争用),反而耽误了出货。
- 而这篇论文的思路是:“既然有些热销品暂时搬不进近区,那就别硬搬了。我们换个思路——提前下单,让货车在客户下单前就把货从远区运到配送站(CPU cache)等着。”
- 这个“提前下单”的策略就是 prefetching(预取)。关键是,给远区下单不能和给近区一样。远区路远,你得更早下单(更大的 prefetch distance),而且不能一次性下太多单,否则会把唯一的运输通道(CXL link)堵死。
这就是论文标题 “Tolerate It if You Cannot Reduce It” 的精髓:能搬则搬,不能搬就忍(通过聪明地预取来忍)。
关键一招 (The "How")
作者没有推翻现有的内存分层系统,而是巧妙地在其中嫁接了一个“感知-决策-执行”的智能预取控制环,其核心是一个名为 Linden 的编译器-运行时协同系统。
-
感知层:
- 编译器在编译时分析代码,找出哪些内存区域是 prefetchable(可预取的),并标注其访问模式(如 stride, sequential)和理想的预取距离。这些信息被打包成“hints”注入到二进制程序中。
- 运行时则负责动态监控:通过硬件性能计数器(如
L2_RQSTS.ALL_HWPF)感知硬件预取的有效性,通过 Intel PEBS 等机制跟踪页面热度(hotness),并通过带宽/延迟探针感知CXL 链路的拥塞状况。
-
决策与执行层(Listing 1 中的
reduce和tolerate方法):- 动态调整预取策略:当一个被软件预取的页面从 DRAM migrate(迁移)到 CXL 时,运行时会立刻介入,利用 JIT 技术重写对应的预取指令,将其 prefetch distance 从 DRAM 最优的 4 调整为 CXL 最优的 7(见 Figure 4)。这就解决了“timeliness”(及时性)问题。
- 选择性开关硬件预取:当检测到 CXL 链路拥塞时,系统不会一刀切地关掉所有核心的硬件预取器。它会查自己的 prefetchability table(见 Table 1),只关掉那些正在访问 CXL 内存的 core 的硬件预取,让访问 DRAM 的 core 不受影响。这避免了“城门失火,殃及池鱼”。
- 反直觉的数据放置:最妙的一招是,对于既热又高度可预取的数据,系统甚至会主动将其 demote(降级)到 CXL!因为预取器能完美 hide 掉 CXL 的延迟,而把它留在 DRAM 反而浪费了宝贵的快速空间给其他无法被预取的数据。实验显示,这样做能带来 7% 的性能提升。
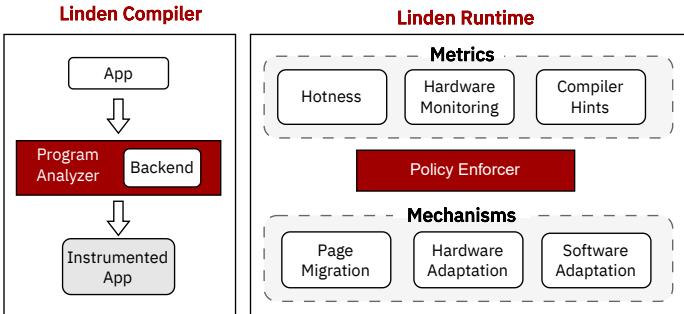
Figure 5: Linden consists of a compiler and runtime. Compiler takes a program and finds the prefetchable regions in the program. Runtime is responsible for detecting hotness, hardware monitoring, and compiler hints to enforce different policies. Runtime able to migrate pages between the tiers, enable/disable hardware prefetchers and change the software behavior in terms prefetchability.
总而言之,Linden 的核心创新在于将 latency reduction(通过迁移)和 latency tolerance(通过智能预取)统一到一个协同的框架下,让系统能根据数据的特性和硬件的实时状态,动态选择最优的延迟应对策略,而不是只会“搬家”这一种笨办法。
1. Prefetchable Regions¶
痛点直击
- 传统的内存分层系统(tiered memory)只想着“减少延迟”——把热数据挪到快的 DRAM,冷数据扔到慢的 CXL。这招在带宽充足时挺好用。
- 但问题来了:CXL 的 带宽远低于 DRAM(论文里差了近 6 倍),一旦你疯狂迁移数据或让硬件预取器(hardware prefetcher)瞎猜,就会在 CXL 链路上造成严重带宽争抢。
- 更糟的是,现有软/硬件预取器都是为同构 DRAM 设计的。它们不知道 CXL 的延迟更高、带宽更窄,于是:
- 硬件预取器会发出太多无效请求,在高并发下反而让延迟飙升到 1500ns(见 Figure 3);
- 软件预取器用的 prefetch distance(预取距离)是为 DRAM 调的,对 CXL 来说太短,根本来不及把数据提前搬进 cache(见 Figure 4)。
简言之:只靠“迁移”来减少延迟,在带宽受限的异构内存里行不通;而盲目“容忍”延迟(靠预取),又会因不匹配硬件特性而适得其反。
通俗比方
想象你在两个仓库之间调度货物:
- 快仓(DRAM):离工厂近,运力强(高带宽),但租金贵。
- 慢仓(CXL):离得远(高延迟),卡车少(低带宽),但便宜。
传统做法是:把畅销品全塞进快仓。但如果畅销品太多,快仓放不下,你就只能把一部分留在慢仓——这时,如果还按老办法派车(比如每小时派一辆),等货到厂早就停工了。
Linden 的思路是:别光想着换仓库,先看看哪些货能“精准预约送达”。\ 它把货物分成“可预约区域”(prefetchable regions)——比如那些每天固定时间要 100 个螺丝的生产线(顺序访问),你完全可以根据路程(延迟)和车速(带宽),算出提前多久下单(prefetch distance = 7 而不是 4)。而对于随机要货的维修组(指针追逐),则用另一种预约方式(软件预取 + JIT 调整)。
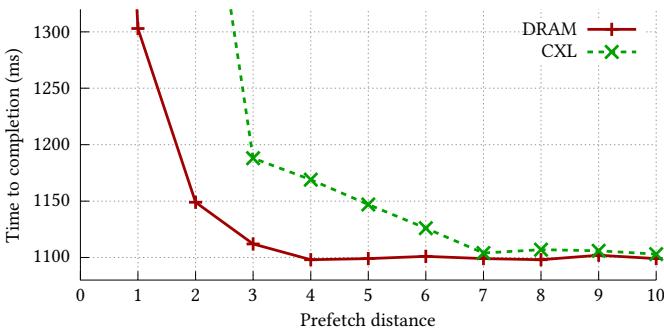
Figure 4: DRAM and CXL have different optimal prefetch distances. For example, in the scan microbenchmark, DRAM performs best with a prefetch distance of 4, while CXL requires a longer distance of 7 due to its higher latency.
关键一招
作者没有抛弃“迁移”,而是在迁移决策中引入了“预取可行性”作为新维度。具体来说:
-
定义了一个结构化的“预取区域”(prefetchable region),它不只是一页内存,而是一组具有相似访问模式的页,并附带四个关键属性:
- Prefetchability ratio:这个区域能被预取“拯救”的比例(0~1),越高说明越值得预取;
- Access pattern type:是顺序(stride)、空间局部(spatial)还是指针追逐(irregular)?决定用硬件还是软件预取;
- Target & prefetch distance:明确哪个 load 对应哪个 prefetch,以及当前最优的提前量;
- Freshness:防止用过期的访问模式做决策。
-
运行时动态联动:
- 当一个预取区域被迁移到 CXL 时,runtime 自动把它的 prefetch distance 从 4 改成 7(见 Figure 4);
- 如果检测到 CXL 链路拥塞(通过硬件计数器),就只关掉访问慢仓的 core 的硬件预取器,而不是全局关闭(避免误伤 DRAM 访问);
- 甚至可以反过来:如果一个区域又热又高度可预取,干脆把它留在 CXL——因为预取已经能 hide 掉延迟,省下的 DRAM 空间留给真正无法预取的数据。
Figure 5: Linden consists of a compiler and runtime. Compiler takes a program and finds the prefetchable regions in the program. Runtime is responsible for detecting hotness, hardware monitoring, and compiler hints to enforce different policies. Runtime able to migrate pages between the tiers, enable/disable hardware prefetchers and change the software behavior in terms prefetchability.
本质上,Linden 把“是否迁移”这个问题,从单一的“hot/cold”判断,升级成了一个 多目标优化问题:在“减少延迟”(迁移)和“容忍延迟”(预取)之间做智能权衡。而 prefetchable regions 就是实现这种权衡的最小决策单元。
2. Linden Compiler¶
痛点直击 (The "Why")
- 传统的 tiered memory 系统(比如 DRAM + CXL)只想着“把热数据搬快点”,也就是通过 page migration 来 reduce latency。这在数据访问模式简单、局部性好的时候很有效。
- 但现实是,很多应用的 hot data 并不一定能被高效迁移(比如数据太大、迁移开销高),或者即使迁移到 fast tier,依然有延迟。
- 更关键的是,现有系统完全忽略了:有些延迟其实可以“忍”过去——只要提前把数据拿进 cache,CPU 就不用干等。这就是 tolerate latency 的思路。
- 问题在于,现有的 hardware/software prefetcher 都是为 homogeneous memory(纯 DRAM)设计的。直接用在 CXL 上会出大问题:
- Hardware prefetcher 不知道 CXL 带宽窄,疯狂发请求反而造成 bandwidth contention,让延迟从 237ns 暴涨到 1500ns(见 Figure 3)。
- Software prefetcher 用的 prefetch distance 是为 DRAM 调的(比如距离=4),但在 CXL 上需要更远(比如距离=7)才能 cover 住高延迟(见 Figure 4)。
- 所以,系统缺一个“先知”:能在程序跑之前,就告诉 runtime “哪些内存区域值得 prefetch,该怎么 prefetch”。
通俗比方 (The Analogy)
- 想象你是个快递调度中心经理(runtime),手下有两种仓库:市中心闪电仓(DRAM)和郊区大仓(CXL)。
- 以前的做法是:看哪个商品卖得火(hotness),就把它挪到闪电仓。但如果闪电仓满了,或者挪货太慢,顾客(CPU)还是得等。
- Linden Compiler 就像是你的 智能订单分析员。他提前看销售数据(源代码),发现:“哦,每周一早上 9 点,总有一批人要买《周一晨报》,而且他们都是按固定路线来的。”
- 于是他告诉你:“别急着把报纸全搬进闪电仓,你只要在周日半夜,提前把下周一的报纸从郊区大仓发车送到配送站(cache)就行。” 这样,即使报纸还在郊区仓,顾客也感觉不到延迟。
- 但他不会对“随机购买的限量球鞋”这么做,因为没法预测。
关键一招 (The "How")
- Linden Compiler 的核心动作不是自己去做 prefetch,而是 给 runtime 提供精准的“作战地图”。
- 它通过 pluggable backends(比如传统编译器 pass 或 ML 模型)扫描源代码,识别出具有 predictable access pattern 的循环或数据结构。
- 然后,它 instrument 原始二进制,在关键位置插入轻量级的 helper functions。
- 这些 helper functions 在程序运行时会被触发,向 runtime 报告:
- 当前线程 ID
- 涉及的 memory region(一组 pages)
- 访问模式 pattern(如 stride, sequential)
- 初始的 prefetchability ratio(预测能隐藏多少延迟)
- 这个信息最终填入 runtime 维护的 prefetchability table(见 Table 1),成为后续决策(迁移、开关硬件 prefetcher、调整软件 prefetch distance)的依据。
Figure 5: Linden consists of a compiler and runtime. Compiler takes a program and finds the prefetchable regions in the program. Runtime is responsible for detecting hotness, hardware monitoring, and compiler hints to enforce different policies. Runtime able to migrate pages between the tiers, enable/disable hardware prefetchers and change the software behavior in terms prefetchability.
- 换句话说,作者并没有让 compiler 直接生成 prefetch 指令,而是巧妙地 把“能不能 prefetch”这个语义信息,从 compile-time 传递到 runtime,让 runtime 能结合 实时的 hotness 和 hardware contention 做出最合适的 reduce or tolerate 决策。
3. Linden Runtime¶
痛点直击 (The "Why")
- 传统的 tiered memory 系统(比如 DRAM + CXL)只做一件事:把热数据迁移到快层,冷数据扔到慢层。这叫 latency reduction(延迟削减)。
- 但问题在于:不是所有热数据都值得留在快层。有些热数据访问模式非常规整(比如顺序扫描),即使放在慢层,只要提前预取(prefetch),CPU 根本感觉不到延迟。
- 更糟的是,现有系统对 prefetcher 是“放养”状态:
- Hardware prefetcher 在 CXL 上会疯狂发请求,但 CXL 带宽只有 DRAM 的 1/6,结果造成 严重带宽争用,反而让延迟飙升(如 Figure 3 所示,延迟从 237ns 暴涨到 1500ns)。
- Software prefetcher 用的是为 DRAM 调优的 prefetch distance,放到高延迟的 CXL 上就“太晚了”,根本藏不住延迟(Figure 4 显示 CXL 需要距离 7,DRAM 只需 4)。
- 所以,旧思路是“能迁就迁”,但忽略了“能忍则忍”——对于可预测的访问,与其费劲迁移,不如让它待在慢层,靠聪明的 prefetch 来容忍延迟。
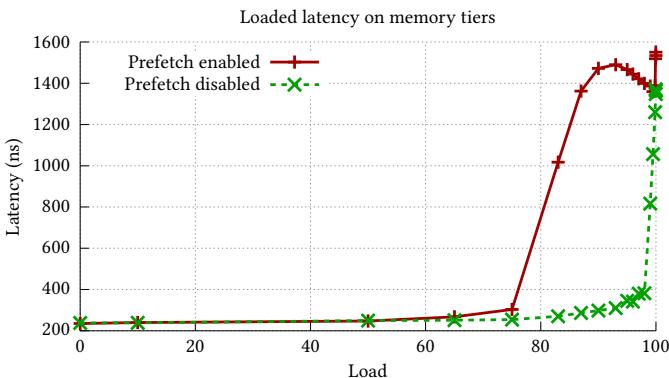
Figure 3: Under high load, prefetching causes latency to increase dramatically at lower loads compared to when prefetching is disabled, resulting in up to 6.3× higher latency.
Figure 4: DRAM and CXL have different optimal prefetch distances. For example, in the scan microbenchmark, DRAM performs best with a prefetch distance of 4, while CXL requires a longer distance of 7 due to its higher latency.
通俗比方 (The Analogy)
想象一个图书馆(内存系统)有两个区域:
- A区(DRAM):就在阅览室旁边,取书只要 1 分钟。
- B区(CXL):在地下室,取书要 2.5 分钟。
传统管理员(tiering system)的做法是:谁常看的书,就搬到 A 区。但 Linden 的管理员更聪明:
- 他先问:“这本书是按顺序读的(比如字典),还是随机翻的(比如查资料)?”
- 如果是顺序读,他就说:“别搬了,我让助手提前下去拿好下一章,你读完这页,下一页刚好送到。” 这就是 tolerate latency by prefetching。
- 如果是随机翻,那才真的搬上来。
- 而且,如果发现地下室电梯(CXL link)太挤,他会立刻让助手暂停下去拿书(disable hardware prefetcher),避免堵死。
- 如果书被临时搬到了地下室,他会马上调整助手出发的时间(动态改 prefetch distance),确保书还是能准时送到。
这个管理员手里有三张表:读者偏好表(compiler hints)、热门书籍排行榜(hotness)、电梯实时拥堵监控(hardware counters)。他根据这三张表动态决策。
Figure 5: Linden consists of a compiler and runtime. Compiler takes a program and finds the prefetchable regions in the program. Runtime is responsible for detecting hotness, hardware monitoring, and compiler hints to enforce different policies. Runtime able to migrate pages between the tiers, enable/disable hardware prefetchers and change the software behavior in terms prefetchability.
关键一招 (The "How")
Linden Runtime 的核心创新,是在传统 tiering 的“迁移决策”之外,增加了一个基于上下文的 prefetch 控制平面。它没有推翻现有机制,而是在其上叠加了一层智能调度:
-
它把决策依据从单一的 hotness,扩展为三位一体的信号:
- Compiler hints:标记哪些内存区域是 prefetchable(如 Table 1 所示,包含 pattern, ratio, target 等)。
- Page hotness:沿用传统指标,判断数据是否频繁访问。
- Real-time hardware monitoring:持续采样 bandwidth utilization、useless prefetches、tier-specific congestion。
-
基于这三者,Runtime 动态执行三种操作:
- Page migration:对不可预取的热数据,依然迁移到快层(Reduce)。
- Hardware prefetcher control:通过 MSR 寄存器,按核粒度开关硬件预取器。例如,只关掉访问 CXL 的核心的预取,不影响 DRAM 用户。
- Software prefetch adaptation:
- 利用 JIT 或二进制重写,动态调整 prefetch distance。当页面从 DRAM 迁移到 CXL 时,自动把距离从 4 改成 7。
- 甚至可以按需插入新的 prefetch 指令。
-
其策略引擎(Listing 1)的核心逻辑是:“Tolerate it if you cannot reduce it”:
- 如果一个区域又热又可预取,反而可以故意把它留在慢层,省下宝贵的 DRAM 空间给真正需要它的随机访问数据。
- 实验证明,这样做在特定场景下能带来 7% 的性能提升。
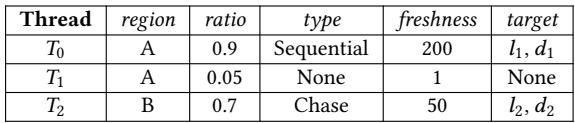
Table 1: An example of a prefetchability table.

Listing 1: Algorithm for policy enforcement in the Linden runtime.
4. Tier-Aware Prefetch Distance Adaptation¶
痛点直击 (The "Why")
- 传统的 软件预取(Software Prefetching) 在设计时,通常假设内存是同构的(homogeneous),即所有数据访问延迟都差不多。因此,它会用一个固定的 prefetch distance(比如提前4个元素)来发出预取指令。
- 但在 Tiered Memory(分层内存) 系统里,这个假设崩了。数据可能今天在 低延迟的 DRAM(112ns),明天就被迁移到 高延迟的 CXL(237ns)。同一个 prefetch distance,在 DRAM 上刚刚好,在 CXL 上就太晚了——数据还没进 Cache,程序就已经卡住等它了。
- 更糟的是,如果为了 CXL 把距离设得太长,数据又可能在 DRAM 里被提前太久加载,结果在真正用到之前就被别的数据挤出 Cache,白忙活一场。这就是 “timeliness”(及时性) 的两难困境。
通俗比方 (The Analogy)
- 想象你是个快递调度员,要给两个仓库送货:一个是市内本地仓(30分钟达),一个是郊区仓(90分钟达)。
- 以前只有一个本地仓,你总是提前30分钟下单,货刚好准时到。
- 现在系统自动把货在两个仓之间调来调去。如果你还是死板地提前30分钟下单:
- 货在郊区仓?那肯定迟到,生产线停工。
- 货在本地仓但你提前90分钟下单?货早就到了,结果堆在门口被偷了(Cache Eviction)。
- Linden 的做法是:给每个包裹贴个标签,标明它现在在哪个仓。调度系统一看到标签变了,立刻动态调整下单时间——本地仓提前30分钟,郊区仓提前90分钟。这样,无论货在哪,都能刚好在需要时送到门口。
关键一招 (The "How")
- 作者没有重新发明预取器,而是巧妙地在 Page Migration(页面迁移) 和 Prefetch Instruction(预取指令) 之间架了一座桥。
- 具体来说:
- 编译器阶段:先静态分析代码,识别出哪些内存区域是 prefetchable 的,并在二进制里埋点(instrumentation),记录下这些区域的访问模式和初始的 prefetch distance。
- 运行时阶段:Linden Runtime 持续监控页面是否在 DRAM ↔ CXL 之间迁移。
- 关键扭转:一旦检测到某个包含预取指令的页面被迁移到了新 tier,Runtime 就会立刻介入,通过 JIT(Just-In-Time Compilation) 技术,动态重写(rewrite) 那条预取指令里的 distance 参数。
- 例如,当数据从 DRAM demote 到 CXL 时,把
prefetch(distance=4)改成prefetch(distance=7)。 - 反之,当数据被 promote 回 DRAM 时,再改回
distance=4。
- 例如,当数据从 DRAM demote 到 CXL 时,把
- 这个机制的核心在于,它把 “数据位置” 和 “预取时机” 绑定成了一个闭环反馈系统,而不是像传统方法那样,让两者脱节。
Figure 4: DRAM and CXL have different optimal prefetch distances. For example, in the scan microbenchmark, DRAM performs best with a prefetch distance of 4, while CXL requires a longer distance of 7 due to its higher latency.
上图清晰地展示了这个核心思想:DRAM 和 CXL 有着截然不同的最优 prefetch distance。Linden 的价值就在于,它能确保系统始终运行在这个“最优值”上,而不是在一个对任何 tier 都不合适的固定值上将就。
5. Selective Hardware Prefetcher Control¶
痛点直击
- 传统的内存分层系统(如 DRAM + CXL)在处理 硬件预取器(Hardware Prefetcher) 时,采用的是“一刀切”策略:要么全开,要么全关。
- 这在 异构内存带宽 场景下非常难受。CXL 的带宽只有 DRAM 的约 1/6(46 GB/s vs. 271 GB/s),一旦多个核心同时触发大量预取请求,CXL 链路就会严重拥塞。
- 更糟的是,即使某些核心只访问 本地 DRAM(带宽充足、无拥塞),它们也会被连累——因为全局关闭预取器后,这些本可受益于预取的快速访问也失去了加速机会。
- 结果就是:慢的没救成,快的还被拖垮了,整体性能反而下降(论文提到最高恶化 19%)。
Figure 2: When the number of threads increases the prefetching effectiveness of CXL decreases while DRAM being constant, and for high number of threads prefetching hurts the performance on CXL.
通俗比方
想象一个双车道高速公路收费站:
- 快车道(DRAM):ETC 自动抬杆,车流顺畅。
- 慢车道(CXL):人工收费,窗口少、速度慢,高峰期排长队。
现在,传统做法是:只要慢车道堵了,就把整个收费站的所有ETC都关掉,强制所有车走人工通道。结果?
- 慢车道确实压力小了点(因为没人预取了),
- 但快车道上那些本来能秒过的车,也被迫排队,整体通行效率暴跌。
Linden 的做法是:只关慢车道入口的ETC引导牌,让去慢车道的车别提前变道插队;而快车道的ETC照常工作,该秒过还是秒过。这样,各走各的,互不干扰。
关键一招
作者并没有沿用“全局开关”的粗粒度控制,而是巧妙地引入了 基于访问目标的细粒度预取器调控机制:
- Linden 的运行时系统会持续追踪:
- 哪些 core 正在访问哪些 memory tier(通过页表或性能计数器);
- 当前 CXL 链路是否拥塞(通过带宽/延迟监控)。
- 一旦检测到 CXL 出现拥塞,它不会全局关闭硬件预取器,而是:
- 仅对那些正在(或将要)访问 CXL 内存的 core,通过 MSR 寄存器 动态关闭其硬件预取功能;
- 同时,允许访问 DRAM 的 core 继续使用硬件预取,维持其高性能。
- 这个决策依赖于 Linden 构建的 prefetchability table(见下表),其中记录了每个内存区域被哪些线程以何种模式访问。
Table 1: An example of a prefetchability table.
这种“按需禁用、精准隔离”的策略,本质上是将预取控制从 系统级(system-wide) 下沉到了 核心-内存域级(core-to-tier-aware),从而在容忍慢速内存延迟的同时,保护了快速内存的性能不受牵连。