TIP: Time-Proportional Instruction Profiling 通俗讲解¶
0. 整体创新点通俗解读¶
痛点直击 (The "Why")
- 传统的性能分析工具(profilers)在现代高性能处理器上“指鹿为马”。它们试图告诉你程序的时间花在哪条指令上,但因为处理器内部极度复杂的 out-of-order execution 和 pipeline stalls,这些工具的采样逻辑与真实的性能瓶颈脱节。
- 具体来说,现有方法如 Intel PEBS 的 Next-Committing Instruction (NCI) 启发式,在遇到 pipeline flush(例如分支预测错误)时,会把时间错误地归咎于 flush 之后提交的第一条指令,而不是真正引发 flush 的那条指令。这就像火灾后,消防员不去找纵火犯,反而去责怪第一个跑进火场的救火队员。
- 论文用一个理想的 Oracle profiler 作为黄金标准进行量化,发现即便是最先进的 NCI 方法,其 instruction-level profile error 也高达 9.3%,而其他方法(如 Software, Dispatch, LCI)的错误率更是超过了 50%。这种系统性偏差让开发者很难定位真正的性能瓶颈。
通俗比方 (The Analogy)
- 想象你在管理一条繁忙的高速公路(处理器 pipeline)。你的任务是找出哪个入口(指令)造成了最严重的拥堵(stall)。
- 旧的方法就像是在出口收费站(commit stage)随机拦下一辆车(NCI),然后问:“嘿,你觉得堵车是因为谁?” 这辆车可能只是恰好路过,对拥堵毫无责任。
- 而论文提出的 TIP (Time-Proportional Instruction Profiling) 则像是在每个车道上都安装了智能摄像头。它不仅能记录哪辆车通过了出口,更能回溯到拥堵发生时,是哪辆车(或哪些车)卡在了最前面,挡住了后面所有人的路。它关注的是 谁暴露了延迟(exposed the latency),而不是谁碰巧在错误的时间出现在了错误的地点。
关键一招 (The "How")
- 作者的核心洞察是:一个准确的 profiler 必须做到 time-proportional attribution,即每个时钟周期都应该被归因于那个让处理器“卡住”的指令。
- 为了实现这一点,TIP 并没有发明全新的硬件,而是巧妙地将理想 Oracle profiler 的归因逻辑与现实可行的 statistical sampling 结合起来。
- 具体来说,TIP 在处理器的 Reorder Buffer (ROB) 提交阶段做文章:
- 当处理器正常提交多条指令时(Computing state),TIP 会将采样到的时间 平均分摊 给所有同时提交的指令,正确处理了 ILP (Instruction-Level Parallelism)。
- 当处理器因为某条指令未执行完而卡住时(Stalled state),TIP 会将时间全部归因于 ROB 头部 的那条指令。
- 当发生 pipeline flush 或 front-end drain 导致 ROB 为空时,TIP 会利用一个 Offending Instruction Register (OIR) 来记住最后一个提交的、可能导致问题的指令(如 mispredicted branch),并将空闲周期归因于它。
- 这个设计的关键在于,TIP 通过少量额外的硬件(主要是 OIR 和一些状态标志位),在每次 PMU 触发采样时,都能根据处理器当前的精确状态(计算中、卡住、flush后、前端停顿),做出与 Oracle 一致的归因决策,从而将平均错误率从 NCI 的 9.3% 大幅降低到惊人的 1.6%。
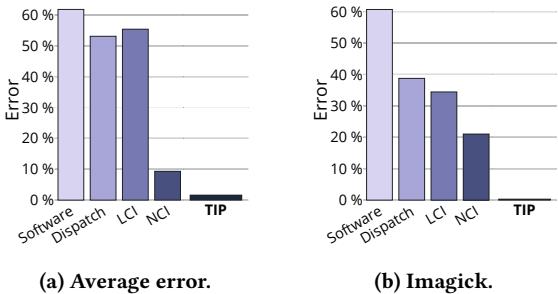
Figure 1: Instruction-level profle error of state-of-the-art profilers compared to our Time-Proportional Instruction Profiler(TIP).Existing profilers are inaccurate due to lack of ILP support and systematic latency misattribution.
这个精度的提升不是纸上谈兵。论文用 SPEC CPU2017 中的 Imagick 做案例研究:NCI 的报告让人摸不着头脑,而 TIP 则精准地指出了罪魁祸首是两条不必要的 CSR (Control Status Register) 操作指令,它们频繁触发 pipeline flush。开发者据此优化后,性能直接提升了 1.93×,充分证明了 TIP 在实战中的巨大价值。
1. Oracle Profiler¶
痛点直击
- 以前的性能分析器(比如 Intel PEBS 的 NCI、外部调试器的 LCI,或者软件中断采样)在给指令“算账”时,逻辑是混乱的。它们不是在真正决定程序慢下来的那个时刻去记录,而是在一个方便但不准确的点(比如刚提交完或即将提交时)随便抓一个指令来背锅。
- 这导致了两种典型的“冤假错案”:
- 系统性误判:比如,一个分支预测错了,导致整个流水线被冲刷(flush),后面几十个周期都在空转等新指令进来。这时候,NCI 会把这几十个空转周期的“罪责”算到冲刷后第一个提交的无辜指令头上,而真正的罪魁祸首——那个错误的分支——反而看起来没花什么时间。
- 忽略并行性 (ILP):现代处理器一个周期能提交好几条指令。旧方法只会挑其中一条(比如下一条要提交的)来代表整个周期,这就让其他同时提交的指令“白干了”,它们对性能的贡献完全没被统计到。
通俗比方
- 想象你在管理一个快递分拣中心(处理器)。你的目标是找出哪个环节最拖后腿。
- 旧方法就像这样:
- 软件采样:每隔一段时间,你派个人去仓库门口看一眼,记下他看到的第一个包裹(指令)的单号。但这个包裹可能早就该处理完了,只是因为前面卡住了才堆在门口,它本身没问题。
- NCI/LCI:你只盯着传送带末端的扫描仪。LCI 记录上一个扫过的包裹,NCI 记录下一个要扫的包裹。但如果传送带因为上游故障停了半小时,这两个方法记录的包裹都和这半小时的停工毫无关系。
- Oracle Profiler的做法完全不同。它相当于在分拣中心的每个关键节点(尤其是出口闸口)都装了高清摄像头,并且有一个超级聪明的会计:
- 当传送带正常运转时(Computing State),它知道这一秒有4个包裹同时通过闸口,就给每个包裹的账本上精确记上0.25秒的工作量。
- 当传送带卡住时(Stalled State),它立刻锁定卡在闸口最前面的那个包裹(比如一个需要特殊开箱检查的大件),把所有等待时间都记在这个包裹头上。
- 当因为地址写错导致一批包裹全被退回重发时(Flushed State),它不会去怪重新发来的第一个新包裹,而是精准地找到那个写错地址的原始订单,并把所有清空传送带和等待重发的时间都算在它头上。
关键一招
- 作者没有试图去改进现有的采样硬件,而是先构建了一个理论上完美的“黄金标准”——Oracle Profiler。它的核心思想是 “时间比例归因” (time-proportional attribution):每一个时钟周期,都必须且只能归因于当前让处理器“暴露延迟”的那条(或那些)指令。
- 为了实现这一点,Oracle 将处理器的提交阶段(Commit Stage)抽象为四种基本状态,并为每种状态定义了精确的归因规则:
- State 1: Computing:如果有
n条指令提交,则每条指令分摊1/n个周期。 - State 2: Stalled:如果ROB非空但无法提交,则将整个周期归因于ROB队首那条尚未执行完的指令。
- State 3: Flushed:如果ROB因错误预测等原因被清空,则将空转周期归因于引发冲刷的那条指令(如错误的分支)。
- State 4: Drained:如果ROB因前端(如指令缓存未命中)供不上货而变空,则将空转周期归因于第一个因前端阻塞而未能及时进入ROB的指令。
- State 1: Computing:如果有
- 正是这套基于提交阶段状态机的、覆盖所有可能场景的、无歧义的归因逻辑,使得 Oracle 成为了衡量其他所有实际性能分析器准确性的黄金参考。它揭示了现有方法的根本缺陷——它们都没有遵循这种严格的时间比例原则。
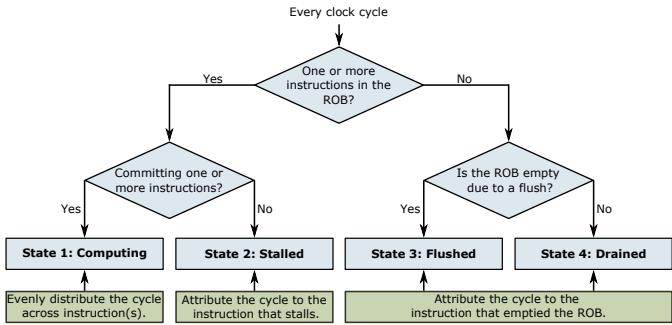
Figure 3: Oracle profiler clock cycle attribution overview.
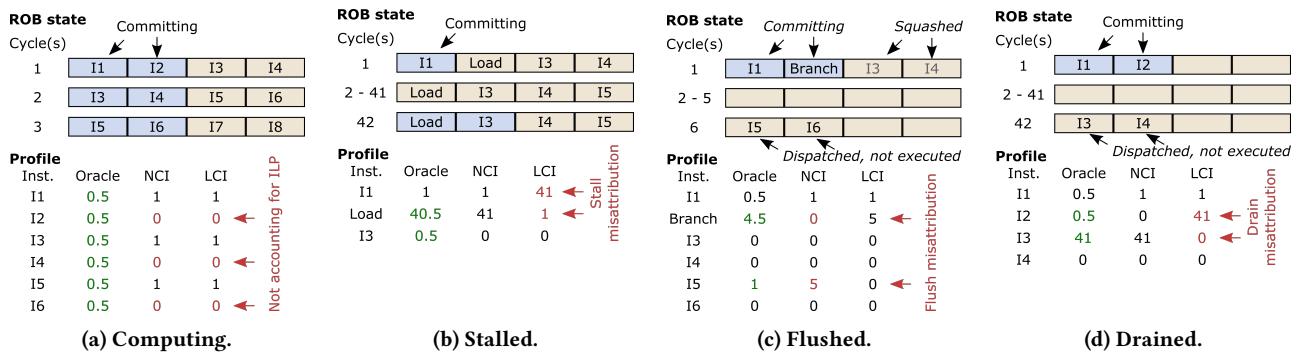
Figure4:Exampleillustrating theOracle,NC1,andLCIprofilersona2-wideout-of-orderprocessor.NCIandLCIfallhortbeuse they do not account for ILPat the commit stage and misattribute pipeline stall,flush and/ordrain latencies.
2. Time-Proportional Instruction Profiling (TIP)¶
痛点直击 (The "Why")
- 传统的性能分析器(Profiler)在现代乱序执行(Out-of-Order)处理器上“指鹿为马”。它们采样的指令,往往不是真正导致性能瓶颈的“元凶”。
- 软件级 Profiler(如 Linux perf)存在严重的 skid 问题:中断发生时,流水线里正在执行的指令早已被冲刷掉,采样点落在了几十甚至上百条指令之后,完全失真。
- 硬件级 Profiler(如 Intel PEBS 的 NCI, AMD IBS 的 Dispatch-tagging)虽然解决了 skid,但归因逻辑有根本缺陷:
- NCI (Next-Committing Instruction):在流水线冲刷(flush)后,它会把空转的周期错误地归咎于冲刷后第一个提交的指令,而不是引发冲刷的那个分支指令。这就像火灾后,把损失算在第一个进火场的消防员头上,而不是纵火犯。
- Dispatch-tagging:它在指令分发(Dispatch)时就打上标签,但一个指令在后端执行单元卡住时,会导致前端分发停顿,让无辜的、刚分发的指令“背锅”。
- 它们都忽略了 ILP (Instruction-Level Parallelism):当多个指令并行提交时,它们只归因给其中一个,导致 profile 严重偏斜。
通俗比方 (The Analogy)
- 想象你在管理一个繁忙的快递分拣中心(处理器)。你的目标是找出哪个包裹(指令)导致了整个中心的延误。
- 旧方法:
- 软件 Profiler 就像每隔一段时间,你随便抓一个刚进门的快递员问:“现在最忙的是谁?” 快递员可能刚来,对积压的包裹一无所知。
- NCI 就像你只记录每次传送带启动时,上面的第一个包裹。但如果传送带是因为之前的危险品(错误预测的分支)爆炸而停摆,你却把停摆时间算在了重启后第一个普通包裹头上。
- Oracle(理想参考) 就像你给每个包裹都装了GPS,并且有上帝视角,能精确记录每一秒传送带的停滞是因为哪个包裹在安检(执行单元)卡住了,或者是因为入口堵了(前端停顿)。但这会产生海量数据,根本不现实。
- TIP 的做法是:你不需要追踪每个包裹,而是聪明地在关键决策点(包裹离开分拣区,即 commit 阶段)设置几个智能摄像头。这些摄像头不仅能拍下离开的包裹,还能根据传送带的状态(是否停滞、是否刚经历爆炸清理)来推断刚才那一秒的延误到底该算在谁头上。它用极少的快照,还原了接近上帝视角的真相。
关键一招 (The "How")
- TIP 的核心创新在于,它将 Oracle 的时间归因策略 精巧地融入到一个基于 统计采样 的硬件单元中,使其既实用又精准。
- 具体来说,TIP 在处理器的 ROB (Reorder Buffer) 提交阶段做文章,通过一个名为 OIR (Offending Instruction Register) 的寄存器和一套状态机,实现了对四种核心状态的精准捕捉:
- Computing (计算中):当多个指令并行提交时,TIP 不会只选一个,而是将采样周期 平均分配 给所有提交的指令,正确反映了 ILP。
- Stalled (停滞中):当 ROB 头部的指令因未执行完而阻塞提交时,TIP 会将采样周期全部归因于这个 头部指令。
- Flushed (冲刷后):当 ROB 因错误预测等原因变空时,TIP 会利用 OIR 中记录的 最后一个提交的、导致冲刷的指令(如 mispredicted branch)作为归因对象。
- Drained (排空后):当 ROB 因前端停顿(如 i-cache miss)而变空时,TIP 会将空转周期归因于 第一个重新进入 ROB 的指令。
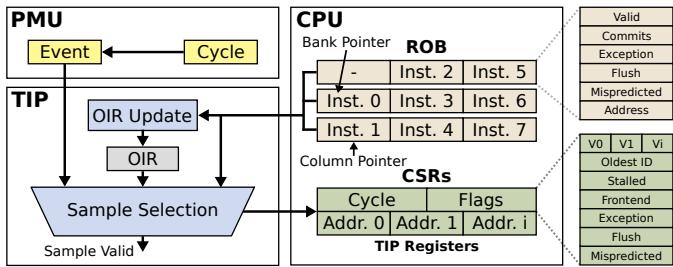
Figure 5: Structural overview of our Time-Proportional Instruction Profiler (TIP). TIP is triggered by the PMU,collects a sample,and finally exposes the sample to software.
- 这个设计的关键扭转在于:它不再盲目地采样“下一个”或“上一个”指令,而是根据处理器 commit stage 的实时状态,动态地、原则性地决定“此刻的延迟应该由谁负责”。它把 Oracle 的复杂逻辑,压缩成了一个轻量级的状态判断和寄存器读取操作,从而在仅 1.6% 的平均指令级误差下,实现了工程上的可行性。
为了直观感受其效果,看看在 SPEC CPU2017 的 Imagick 基准测试中的表现:
- NCI 的 profile 错误地将大量时间归因于
feq.d和ret指令,让开发者无从下手。 - TIP 则精准地定位到罪魁祸首是
frflags和fsflags这两个控制状态寄存器(CSR)的指令,它们频繁触发 pipeline flush。 - 开发者只需将这两个不必要的 CSR 操作替换为
nop,就获得了 1.93× 的惊人性能提升。 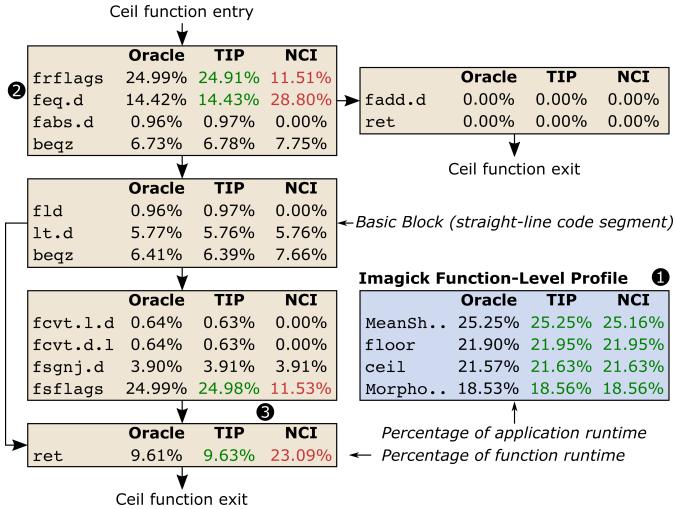
Figure 12:Function and instruction-level profiles for lmagick for TIP and NCI compared to Oracle.
| Profiler | 平均指令级误差 | 最大误差 | 相对于 TIP 的误差倍数 |
|---|---|---|---|
| TIP | 1.6% | 5.0% | 1.0x |
| NCI (Intel PEBS) | 9.3% | 21.0% | 5.8x |
| LCI | 55.4% | - | 34.6x |
| Dispatch (AMD IBS) | 53.1% | - | 33.2x |
| Software | 61.8% | - | 38.6x |
3. Offending Instruction Register (OIR)¶
痛点直击
- 传统的硬件性能分析器(如 Intel PEBS 的 NCI)在处理器流水线 flush(冲刷)或 drain(排空)后,ROB(Reorder Buffer)会暂时变空。此时,分析器面临一个棘手问题:这些“空转”的时钟周期到底该算在谁头上?
- 如果简单地将这些周期归因于下一个提交的指令(NCI 的做法),就会产生严重的系统性误判。例如,在分支预测错误导致 flush 后,真正应该为延迟负责的是那个预测错误的分支指令,而不是 flush 之后才开始执行的新指令。这会让开发者完全找错优化方向。
通俗比方
- 想象一个工厂的装配流水线(ROB)。正常情况下,产品(指令)一个接一个地流过并被打包(提交)。
- 突然,质检员发现上游送来了一批有缺陷的零件(比如一个 mispredicted branch),必须立刻停掉整条线,清空所有半成品(flush)。
- 在清理和重新上料的这段时间里,流水线是空的,但工厂却在白白烧钱(消耗时钟周期)。
- OIR 的作用,就像是一个尽职的“事故记录员”。他在质检员喊停的瞬间,立刻记下:“事故责任人:质检员老王(即那个分支指令)”。这样,后续计算停工损失时,就能准确地把账算到老王头上,而不是算在下一个无辜的、刚进厂的新工人(下一个提交的指令)身上。
关键一招
- 作者没有试图在 ROB 为空时去“猜测”该归咎于谁,而是设计了一个极其精巧的硬件寄存器——Offending Instruction Register (OIR),来主动追踪潜在的“罪魁祸首”。
- 其核心逻辑转换在于:
- 持续监控:OIR 并非只在需要时才工作,而是在每一个时钟周期都默默地更新自己。
- 在正常提交时,它会记录下最新提交的那批指令中最年轻的一个及其关键标志位(比如是否是 mispredicted branch)。
- 在检测到即将发生异常(exception)时,它会立刻捕获引发异常的那个指令。
- 按需调用:只有当采样时刻发现 ROB 为空(即处于 Flushed 或 Drained 状态)时,TIP 才会去读取 OIR 中保存的信息。
- 如果 OIR 标记了 flush 或 exception,就将空闲周期归因于 OIR 中记录的那条“肇事”指令。
- 如果 OIR 没有这些标记,则说明是前端供料不足(Drained),此时将周期归因于 OIR 之后第一个被分发(dispatched)的指令。
- 持续监控:OIR 并非只在需要时才工作,而是在每一个时钟周期都默默地更新自己。
- 这个设计的巧妙之处在于,它用一个极小的硬件开销(论文中提到仅 9B 存储),通过前瞻性的记录而非事后的推断,完美解决了 ROB 空窗期的归因难题,从而实现了与 Oracle 黄金标准一致的时间-比例归因。
Figure 5: Structural overview of our Time-Proportional Instruction Profiler (TIP). TIP is triggered by the PMU,collects a sample,and finally exposes the sample to software.
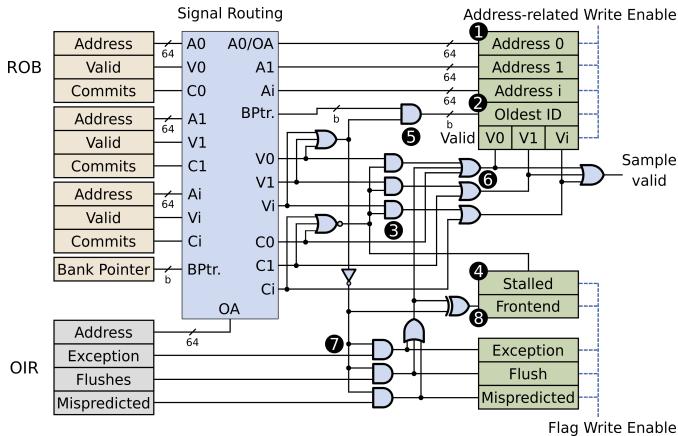
Figure 6: TIP sample selection logic.TIP classifies samples based on the the core state, ROB-flags,and OIR-flags.
4. Instruction-Level Parallelism (ILP) Aware Attribution¶
痛点直击 (The "Why")
- 传统的硬件性能分析器(如 Intel PEBS 的 NCI)在处理器每个周期提交多条指令时,只会把整个周期的“功劳”或“罪责”归于其中一条指令(比如下一条要提交的指令)。
- 这在现代 superscalar 处理器上会引发严重的系统性偏差。想象一个循环体里有四条完全独立、可以并行执行的加法指令。在一个 4-wide 的处理器上,它们很可能在一个周期内全部提交。但 NCI 只会采样其中一条,导致另外三条在性能画像中“隐身”了,或者让被采样的那条看起来慢了四倍。
- 更糟糕的是,这种偏差不是随机的,而是结构性的。它会让开发者误判热点代码,把优化精力用在错误的地方,甚至得出完全相反的结论。
通俗比方 (The Analogy)
- 这就像一个四人划船队,大家齐心协力,一桨下去船就前进了一大截。现在有个教练(性能分析器)要评估谁贡献最大。
- 老派教练(NCI/LCI)的做法是:每次船前进,他只记录第一个把桨收回船内的队员的名字,并把这次前进的全部功劳都算在他头上。
- 结果可想而知:那个总是第一个收桨的队员(可能只是动作快一点)被评为了 MVP,而其他三个同样卖力的队员却被忽略了。整个团队的真实协作效率完全无法体现。
- TIP 的做法则是:教练看到四个人同时发力,就把这次前进的功劳平均分给四个人。这样每个人的贡献才真实、公平。
关键一招 (The "How")
- 作者并没有发明新的采样硬件,而是巧妙地扭转了采样数据的解释逻辑。
- 在处理器的 commit stage,当一个采样事件发生时:
- 如果当前周期有
n条指令正在提交(即处于 Computing state),TIP 不会像 NCI 那样只选一个“代表”,而是将这个采样周期所代表的时间平均拆分成1/n,并分别归属给这n条指令。 - 如果处理器因为某条指令未执行完而卡住(Stalled state),TIP 会将时间全部归属给 ROB(Reorder Buffer)队头的那条阻塞指令。
- 如果当前周期有
- 这个看似简单的“按提交数量均摊”的策略,正是其能实现 time-proportional attribution 的核心。它尊重了 Instruction-Level Parallelism (ILP) 的事实:并行完成的工作,其耗时就应该由所有参与者共同承担。
Figure4:Exampleillustrating theOracle,NC1,andLCIprofilersona2-wideout-of-orderprocessor.NCIandLCIfallhortbeuse they do not account for ILPat the commit stage and misattribute pipeline stall,flush and/ordrain latencies.
这张图(Figure 4a)清晰地展示了这个关键区别。在 Cycle 1,两条指令 I1 和 I2 同时提交。Oracle(以及 TIP)会给每条指令记 0.5 cycles。而 NCI 和 LCI 只会把 1 whole cycle 归给其中一条,造成了明显的失真。正是这种对 commit parallelism 的精确处理,让 TIP 的指令级画像误差(1.6%)远低于 NCI(9.3%)。
5. Four-State Commit Stage Model¶
痛点直击 (The "Why")
- 传统的硬件性能分析器(如 Intel PEBS 的 NCI 或外部调试器的 LCI)在归因执行时间时,逻辑非常“粗糙”。它们只看一个点:要么是“下一个要提交的指令”,要么是“上一个刚提交的指令”。
- 这种做法在现代乱序处理器复杂的执行流面前会彻底失效。想象一下,当处理器因为一个 cache miss 而卡住时,NCI 会把所有等待的时间都算到那个无辜的、即将提交的指令头上;而 LCI 则会把这笔账记在很久以前就提交完的指令上。这两种情况都完全歪曲了性能瓶颈的真实根源。
- 更糟糕的是,当多个指令并行提交(ILP)时,这些分析器只会随机或固定地挑其中一个来“背锅”,导致 profile 结果充满系统性偏差,开发者根本无法信任。
通俗比方 (The Analogy)
- 想象你是一个工厂的生产经理,需要搞清楚生产线为什么慢。旧的方法就像是:
- NCI:每次看表时,就把当前时间算在“下一个要下线的产品”上。
- LCI:每次看表时,就把时间算在“上一个刚下线的产品”上。
- 显然,如果生产线因为缺少某个关键螺丝(相当于 stall)而停摆了10分钟,这两种方法都会把这10分钟错误地算在某个不相关的产品上。
- Oracle 的 Four-State Model 则像是一位拥有上帝视角的智能监控系统。它不只看产品下线的瞬间,而是实时监控整个生产线的状态:
- 计算 (Computing):机器正在正常运转,产品源源不断下线 → 时间平均分给这批产品。
- 阻塞 (Stalled):生产线卡住了,第一个待加工的产品堵在入口 → 所有等待时间都算在这个“堵王”头上。
- 冲刷 (Flushed):发现之前的生产计划错了(比如用错了图纸),整条线上的半成品都要报废重来 → 等待新图纸的时间,全部算在那个做错决策的“错误指令”上。
- 排空 (Drained):原材料仓库空了,生产线自然停下来等货 → 等待时间算在那个“第一个因为没料而无法开工”的产品上。
- 这个模型确保了每一分一秒的“停工损失”都能精准地追溯到真正的责任源头。
Figure 3: Oracle profiler clock cycle attribution overview.
关键一招 (The "How")
- 作者没有去发明一种全新的采样硬件,而是为性能分析建立了一套严谨、完备且符合处理器微架构原理的归因逻辑框架。这个框架的核心就是将处理器提交阶段(Commit Stage)的瞬时状态,严格划分为上述四种互斥且覆盖所有可能性的状态。
- 最关键的扭转在于,它将“时间归因”的焦点从“单个指令”转移到了“处理器的全局状态”。具体来说:
- 在 Computing 状态,它通过均分时间给所有并行提交的指令,完美解决了 ILP 归因问题。
- 在 Stalled 状态,它直接锁定 ROB (Reorder Buffer) 头部的指令作为罪魁祸首,因为正是它无法完成才挡住了整个流水线。
- 在 Flushed/Drained 状态(即 ROB 为空时),它没有放弃,而是利用一个 Offending Instruction Register (OIR) 来记住导致 ROB 清空的那个“元凶”指令(如错误预测的分支或触发缺页异常的指令),并将后续的空转时间全部归于它。
- 正是这套基于状态机的、原则性的归因策略,使得 Oracle 成为了衡量所有其他 profiler 准确性的“黄金标准”,也为 TIP 的实用化设计提供了坚实的理论基础。TIP 本质上就是将这套逻辑用统计采样的方式高效地实现出来。