TEA: Time-Proportional Event Analysis 通俗讲解¶
0. 整体创新点通俗解读¶
痛点直击 (The "Why")
- 以前的性能分析工具,无论是 instruction-driven(如 AMD IBS, Arm SPE)还是 event-driven(如 PMC 计数),都有一个致命盲区:它们无法回答“为什么执行这些关键指令花了这么多时间?”
- Instruction-driven 的方法(在 fetch/dispatch 阶段打标签)会严重偏向那些卡在流水线前端的指令,而不是真正卡住整个程序进度的指令。想象一下,你的快递车(ROB)因为前面一辆车抛锚(stalled at head)而动弹不得,但分析员却只记录后面不断涌来的、根本上不了路的新快递单(dispatched instructions),这显然抓错了重点。
- Event-driven 的方法(单纯计数 cache miss, branch mispredict)则完全忽略了现代处理器的 latency hiding 能力。一个 cache miss 发生了,但如果处理器能同时干别的活,这个 miss 对总时间的影响可能微乎其微。反之,一个没被计数的事件如果恰好发生在关键路径上,就能让整个程序停摆。所以,事件计数和它对性能的真实影响之间,常常没有强相关性(见图7)。
通俗比方 (The Analogy)
- 这篇论文提出的 TEA (Time-Proportional Event Analysis),就像是给 CPU 的 commit stage(退休办公室)装了一个带“病因诊断”的打卡机。
- 传统的 profiler(比如 TIP)只是记录“谁在退休办公室门口排队”,告诉你哪些指令是瓶颈(Q1)。但它不知道这些人为什么排队。
- TEA 则更进一步:当某条指令在退休办公室门口排队时(即暴露了延迟),这个打卡机会立刻翻出这条指令从出生(fetch)到现在的完整“病历”(Performance Signature Vector, PSV),看看它一路上经历了哪些“病症”(performance events),比如是不是得了“L1 cache miss”或者“branch mispredict”。
- 最终,TEA 给每个静态指令生成一份 PICS (Per-Instruction Cycle Stacks),这份报告不仅告诉你这个指令总共耽误了多少时间(高度),还把这段时间精确地分解成各种“病症”所贡献的部分(各层高度)。这就完美地同时回答了 Q1(谁是病人)和 Q2(得了什么病)。
关键一招 (The "How")
- 作者的核心洞察是:要建立时间与事件之间的因果关系,采样点必须在 commit stage,并且要追踪所有 in-flight 指令的事件。
- 为了解决 overhead 问题,他们没有盲目追踪所有几百个 PMU 事件,而是回归第一性原理,只关注那些能直接导致 commit stall 的关键事件,并利用 performance event hierarchies 精心挑选了 9 个最具解释力的事件(见表1)。
- 具体实现上,他们在处理器的各个关键模块(Fetch, Dispatch, LSU, ROB)中嵌入逻辑,为每条动态指令(µop)维护一个 9-bit 的 PSV。这个向量会随着指令在流水线中前进而不断更新,记录下它遭遇的所有关键事件。
- 当基于 TIP 的时间比例采样器决定在某个周期进行采样时,它会根据当前的 commit state(Compute, Drained, Stalled, Flushed)精准定位到应该为此刻延迟负责的那条(或几条)指令,然后连同它的 PSV 一起打包上报。
- 通过这种设计,TEA 巧妙地将 时间归属(由 TIP 解决)和 事件归因(由 PSV 解决)无缝结合,最终以极低的开销(~0.1% 功耗,1.1% 性能)实现了前所未有的分析精度(平均误差仅 2.1%,远优于 IBS/SPE/RIS 的 ~55%)。
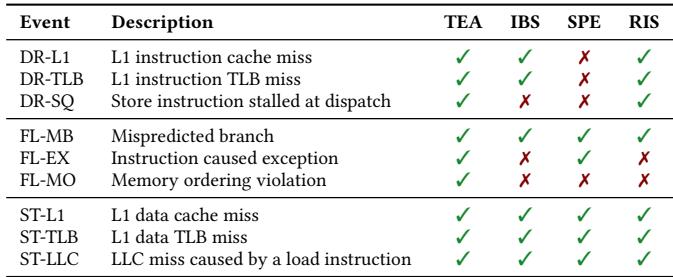
Table 1: The performance events of TEA, IBS, SPE, and RIS.
| 方法 | 平均误差 | 存储开销 | 关键缺陷 |
|---|---|---|---|
| TEA | 2.1% | 249 B | 需要硬件支持 |
| NCI-TEA | 11.3% | - | Flush 场景下归因错误 |
| AMD IBS | 55.6% | ~1 B | 非时间比例,前端采样偏差 |
| Arm SPE | 55.5% | ~1 B | 非时间比例,前端采样偏差 |
| IBM RIS | 56.0% | ~1 B | 非时间比例,前端采样偏差 |
正是这种高精度,让 TEA 能在 lbm 和 nab 这样的真实 benchmark 中发现传统工具无法定位的深层次性能问题,并指导开发者做出有效的优化,分别获得了 1.28x 和 2.45x 的显著加速。
1. Time-Proportional Per-Instruction Cycle Stacks (PICS)¶
痛点直击 (The "Why")
- 以前的性能分析工具,无论是 instruction-driven(如 AMD IBS, Arm SPE)还是 event-driven(如 PMC 计数),都有一个根本性的“错位”问题。
- Instruction-driven 的难受之处:它们在指令刚进入流水线(fetch/dispatch 阶段)就给它“贴标签”,然后记录它一生中遇到的所有事件。但问题是,一条指令可能在前端卡了很久,但真正拖慢整个程序的却是另一条在 commit 阶段卡住的指令。这种做法会严重高估那些“生不逢时”(在错误时间被取指/分发)的指令的重要性,导致你优化了错误的目标。
- Event-driven 的难受之处:它只告诉你“发生了多少次缓存未命中、分支预测失败”,但这些事件的计数和它们对整体执行时间的真实影响之间没有直接关系。因为现代处理器有强大的 latency hiding(延迟隐藏)能力,很多事件的影响被掩盖了。你看到一个很高的 L1 miss 计数,但它可能对性能毫无影响,而一个低频但致命的 pipeline flush 却被淹没在数据海洋里。
通俗比方 (The Analogy)
- 想象你在管理一个繁忙的餐厅(CPU)。你想找出是什么让顾客(程序)等待时间变长。
- 旧方法(IBS/SPE) 就像在顾客一进门(fetch)就给他手腕上戴个计时器,记录他从进门到坐下点餐期间遇到的所有麻烦(比如等位、找不到服务员)。但这完全忽略了后厨(execution/commit)才是真正的瓶颈。可能后厨的一个主厨(关键指令)手受伤了(stall),导致所有菜都出不来,但你的计时器却在记录那些早就坐好、只是在闲聊的顾客。
- 旧方法(PMC计数) 就像你只统计“今天摔碎了多少个盘子”、“服务员跑了多少趟”。这些数据本身没错,但无法告诉你哪个事件是导致翻台率(性能)下降的元凶。也许摔盘子发生在客流低谷,影响不大;而一次关键的食材短缺(pipeline flush)虽然只发生一次,却让整个餐厅停摆半小时。
- TEA 的 PICS 则像一个聪明的经理,他只在上菜窗口(commit stage)观察。每当上菜窗口空闲(stalled/drained/flushed),他就立刻记下:“此刻,是因为后厨的哪道菜(指令)没准备好?具体是因为缺了哪种食材(cache miss)还是厨师切错了(branch mispredict)?” 这样,他记录的每一分钟等待,都精确地、按时间比例地对应到真正造成瓶颈的那个环节。
关键一招 (The "How")
- 作者并没有抛弃现有的采样框架,而是巧妙地在 TIP (Time-Proportional Instruction Profiling) 这个已经能准确定位“谁在 commit 阶段卡住”的基础上,增加了一个 Performance Signature Vector (PSV)。
- 核心逻辑转换:传统的采样只关心“哪个指令地址在卡”,而 TEA 的采样关心的是“哪个指令地址在卡,以及它身上带着哪些‘事件徽章’(PSV)”。
- 具体来说,TEA 在硬件层面为每个 in-flight 指令(ROB entry)维护一个 9-bit 的 PSV,这个向量会随着指令在流水线中流动,实时记录它是否遭遇了预定义的关键事件(如 ST-L1, FL-MB 等)。
- 当 TIP 的采样逻辑在 commit 阶段触发时,它不仅抓取指令地址,还会一并抓取该指令当前的 PSV。通过大量这样的采样,就可以为每个静态指令构建一个 Cycle Stack:栈的总高度代表它对总执行时间的贡献(回答 Q1),而栈内不同颜色的区块大小则代表不同事件(或事件组合)所贡献的时间比例(回答 Q2)。
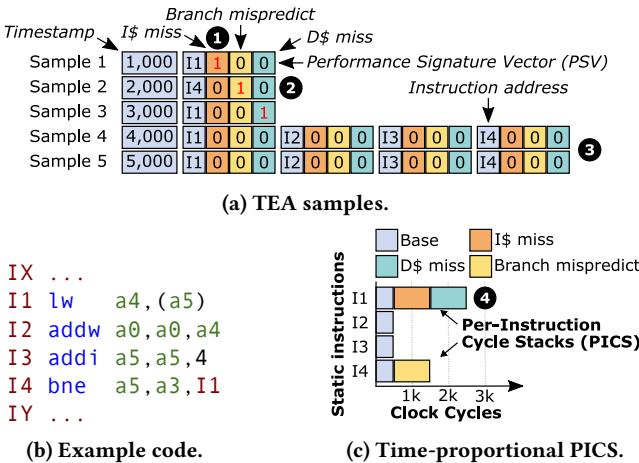
Figure 1: Example explaining how TEA creates PICS. TEA explains how performance events cause performance loss.
- 这个设计的精妙之处在于,它将“时间归属”和“事件归因”这两个问题,在 commit 这个唯一能暴露真实延迟的时刻,通过 PSV 这个载体一次性、原子性地解决了。这从根本上保证了分析结果的 time-proportionality。
2. Performance Signature Vector (PSV)¶
痛点直击
- 传统的性能分析工具,比如 AMD IBS、Arm SPE,它们的问题在于“抓错了人”。它们在指令刚进入流水线(fetch/dispatch阶段)就给它贴上一个标签,然后记录这个指令后续遇到了什么事件(比如 cache miss)。但问题是,一个指令可能在前端等了很久,但它真正卡住整个程序的地方是在后端(commit阶段)。这种“前端采样”的方式,会把大量时间花在那些其实对整体性能影响不大的指令上,导致分析结果严重失真。论文里提到,这些方法的平均误差高达 55%+,几乎没法用。
- 另一种方法是只统计事件发生的总次数(event-driven),比如总共发生了多少次 L1 cache miss。但这更糟糕,因为它完全忽略了 latency hiding(延迟隐藏)效应。一个 cache miss 如果被其他指令的执行掩盖了,那它对性能就没啥影响;反之,一个没被掩盖的 miss 才是真凶。光看总数,根本分不清谁是“真凶”,谁是“背锅侠”。
通俗比方
- 想象你在调查一条高速公路为什么堵车。老办法(IBS/SPE)就像是在入口收费站(fetch)给每辆车发一个记录仪,让它自己记下路上遇到的所有事故。但问题在于,很多车在入口排队时就被记录了,而真正的堵点可能在几十公里外的一个隧道里(commit)。你拿到的数据里,全是入口排队的车,却漏掉了隧道里动弹不得的车。
- Performance Signature Vector (PSV) 的做法则完全不同。它相当于在整条高速公路上部署了无数个微型传感器,每辆车(动态指令)一上路,就自动激活一个专属的“状态手环”(PSV)。这个手环只有几个简单的指示灯(bit),分别对应“是否遇到隧道事故”、“是否遇到桥梁维修”等关键事件。最关键的是,交通指挥中心(TEA sampler)只在道路最拥堵的瓶颈点(commit stage)拍照取证。照片里不仅有堵在那里的车牌号(instruction pointer),还有它手上手环亮着的灯(PSV)。这样,你就精准地知道,到底是哪个事件组合导致了这个具体的堵点。
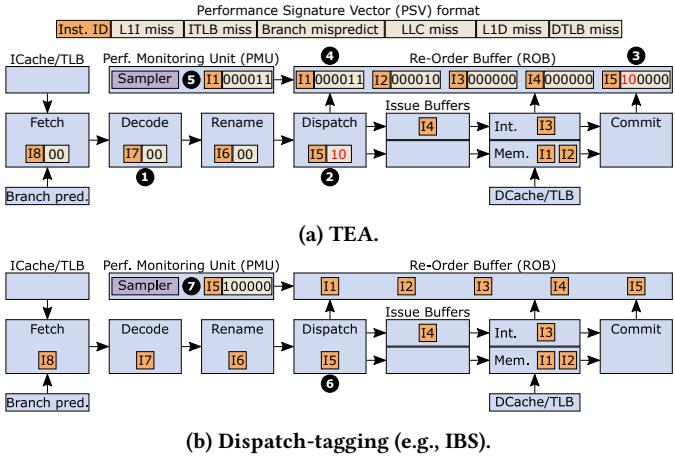
Figure 2: Example comparing TEA to dispatch-tagging. TEA is time-proportional whereas dispatch-tagging is not.
关键一招
- 作者没有改变采样的核心逻辑(依然在 commit 阶段进行 time-proportional 采样),而是巧妙地在原有的指令数据包(instruction packet)中,为每个动态指令都附加了一个轻量级的 PSV。
- 这个 PSV 是一个 bit-vector,它的每一位都对应一个精心挑选的、能解释 commit stall 的关键性能事件(如 ST-L1, FL-MB 等,见下表)。当指令在流水线中执行时,硬件会自动将它经历的事件“点亮”对应的 bit。
- 在采样时刻,硬件不仅捕获当前造成 stall 的指令地址,还一并捕获它完整的 PSV。通过聚合大量这样的(指令地址, PSV)样本,就能为每个静态指令构建出 Per-Instruction Cycle Stacks (PICS),清晰地展示其执行时间是如何被不同的事件组合所消耗的。
- 这一招的精妙之处在于,它用极低的开销(仅 9 bits per instruction, 功耗增加 ~0.1%)实现了对性能瓶颈的精准归因,将平均误差从 55%+ 降到了 2.1%。
| Commit State | Performance Event (in PSV) | Explanation |
|---|---|---|
| Stalled (ST) | ST-L1, ST-TLB, ST-LLC | Load 指令在 ROB 头部等待数据 |
| Drained (DR) | DR-L1, DR-TLB, DR-SQ | ROB 为空,因前端取指或 Store Queue 满 |
| Flushed (FL) | FL-MB, FL-EX, FL-MO | 因分支误预测、异常或内存排序冲突导致 flush |
3. Commit-State-Based Event Hierarchy¶
痛点直击
- 传统的性能分析工具,比如 AMD IBS、Arm SPE,它们的问题在于“抓错了人”。它们在指令刚进入流水线(fetch/dispatch阶段)就给指令打上标签,然后记录它后面遇到的所有事件。
- 这导致一个致命问题:一个指令可能在前端被卡住很久(比如等缓存),但它本身并不是程序慢的“罪魁祸首”。真正让程序变慢的,是那些已经执行完、却卡在 Re-Order Buffer (ROB) 头部无法退休(commit)的指令,因为它们堵住了整个流水线。旧方法会过度关注那些“无辜的等待者”,而忽略了真正的“瓶颈制造者”。
- 另一方面,单纯的事件计数器(Event Counting)只告诉你“发生了多少次缓存未命中”,但完全不关心这些未命中是否真的拖慢了程序。现代处理器有强大的乱序执行和延迟隐藏能力,很多未命中都被掩盖了,对性能毫无影响。这种“只看数量,不看影响”的方式,让开发者很难判断优化方向。
通俗比方
- 想象你在管理一条高速公路的收费站(Commit Stage)。你的目标是找出造成交通大拥堵的根本原因。
- 旧方法(如IBS)就像是在车辆刚进入高速入口匝道(Fetch/Dispatch)时,就给每辆车发一个记录仪。结果你发现入口处排了很长的队,就以为问题是入口太窄。但实际上,队伍之所以长,是因为前方主路的收费站(Commit)被一辆抛锚的大卡车(Stalled Instruction)堵死了。你记录了一堆在入口排队的私家车的数据,却完全没搞清楚真正的问题所在。
- TEA的做法则聪明得多。它直接在收费站现场观察。它看到收费站当前处于什么状态:
- Stalled: 收费站开着,但第一辆车(ROB Head)坏了动不了。
- Drained: 收费站空着,因为后面没车来了(前端停顿)。
- Flushed: 刚才有一辆车逆行(分支预测错误),导致后面所有车都被清空了。
- 然后,TEA不是漫无目的地记录所有信息,而是根据这三种“拥堵状态”,去追溯最可能导致该状态的关键原因。比如,如果是“Stalled”状态,它就重点检查这辆坏掉的车是不是因为“没油了”(L1 Cache Miss)或者“驾照有问题”(TLB Miss)。这就像是建立了一个“故障树”,从现象(拥堵状态)精准定位到少数几个核心病因。
关键一招
- 作者的核心洞察是:所有的性能损失,最终都会在 Commit 阶段以三种非计算状态(Stalled, Drained, Flushed)暴露出来。因此,不需要追踪成百上千个性能事件,只需要围绕这三种状态,构建一个精简的“事件因果树”即可。
- 具体来说,他们做了两件事:
- 状态驱动采样:硬件采样器不再随机或在前端采样,而是紧密耦合到 Commit 逻辑。只有当处理器处于 Stalled/Drained/Flushed 状态时,才去采样那个“责任指令”(即导致该状态的指令)。
- 层次化事件选择:针对每种状态,只选择最顶层、最具解释力的几个事件。例如,对于 Stalled 状态,他们没有去追踪所有可能的缓存层级未命中,而是选择了 ST-L1 (L1 Data Cache Miss), ST-TLB (L1 Data TLB Miss), 和 ST-LLC (Last-Level Cache Miss) 这三个关键节点。因为 L1 未命中是 LLC 未命中的前提,抓住这几个根因,就能解释绝大多数情况,同时将需要追踪的事件数量从几百个锐减到 九个。
- 这个设计巧妙地平衡了洞察力(Insight)和开销(Overhead)。通过聚焦于 Commit 状态这个“性能损失的唯一出口”,并利用事件间的依赖关系进行剪枝,TEA 用极小的硬件代价(仅增加 249 bytes 存储和 ~0.1% 功耗)就获得了远超现有工具的准确性。
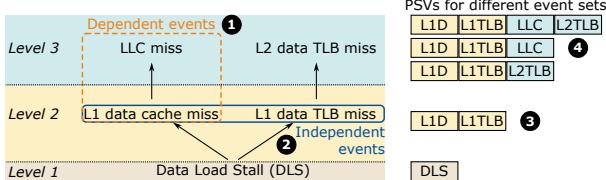
Figure 3: Performance event hierarchy for the Stalled (ST) commit state.
Table 1: The performance events of TEA, IBS, SPE, and RIS.
4. Time-Proportional Sampling Logic¶
痛点直击 (The "Why")
- 传统的性能分析工具,比如 AMD IBS、Arm SPE,它们的采样逻辑是“在哪里打标签,就在哪里采样”,通常在 fetch 或 dispatch 阶段给指令打上标记。
- 这个做法在现代乱序执行(out-of-order)处理器上会出大问题。想象一下,一个指令因为 cache miss 卡在了 Re-Order Buffer (ROB) 的头部,导致整个流水线都停摆了。此时,前端(fetch/dispatch)可能还在不断地把新指令塞进来,但这些新指令根本没机会执行,它们只是“无辜的旁观者”。
- 传统工具会错误地采样到这些“旁观者”指令,并把当前巨大的性能开销(stall cycles)归咎于它们。这就像是工厂停工了,你不去找那个卡住机器的坏零件,反而去记录那些堆在仓库里还没用上的新零件,完全本末倒置。
- 结果就是,开发者看到的性能报告严重失真,无法定位真正的性能瓶颈(performance-critical instructions),优化工作变成了“盲人摸象”。
通俗比方 (The Analogy)
- 这就像调查一场交通大拥堵的原因。传统方法(fetch/dispatch tagging)相当于在高速入口收费站随机拍下车牌号,然后说:“看,这些车造成了堵车!”
- 但实际上,造成堵车的很可能是在几公里外事故现场那辆抛锚的大卡车。收费站拍到的车,只是被堵在路上的受害者。
- Time-Proportional Sampling Logic 的做法则聪明得多:它直接飞到拥堵最严重的路段(即处理器的 commit stage),找到那辆真正挡在路上的车(即 head of ROB 的指令),然后问:“嘿,兄弟,你为啥停在这儿?是因为没油了(cache miss)?还是爆胎了(branch mispredict)?”
- 它只关心那个正在暴露延迟(exposing latency) 的指令,因为它才是真正消耗系统时间的“罪魁祸首”。
关键一招 (The "How")
- 作者没有改变采样的基本形式(依然是statistical sampling),而是彻底扭转了采样的目标选择逻辑。
- 核心在于,TEA 的硬件采样器会实时监控 commit stage 的状态,并根据四种不同状态精准定位“元凶”:
- Compute: 多条指令同时提交,时间均匀分摊给它们。
- Stalled: ROB 头部的指令还没执行完。采样目标就是这个next-committing instruction。
- Drained: ROB 空了,因为前端取指慢(如 I-cache miss)。采样目标是下一个将要提交的指令。
- Flushed: 因为分支预测错误等原因,ROB 被清空了。此时,真正该负责的是那个已经提交但导致 flush 的指令(last-committed instruction),而不是下一个要提交的。
- 为了实现这一点,TEA 在硬件上做了一个精巧的设计:它为每个动态指令维护一个 Performance Signature Vector (PSV),并在 commit stage 的采样时刻,将正确的指令地址与其完整的 PSV(记录了它经历的所有性能事件)一起打包上报。
- 这个逻辑转换确保了最终生成的 Per-Instruction Cycle Stacks (PICS) 是 time-proportional 的——每条指令在报告中所占的“高度”,严格正比于它对总执行时间的真实贡献。
Figure 1: Example explaining how TEA creates PICS. TEA explains how performance events cause performance loss.
Figure 2: Example comparing TEA to dispatch-tagging. TEA is time-proportional whereas dispatch-tagging is not.