SHADOW: Simultaneous Multi-Threading Architecture with Asymmetric Threads 通俗讲解¶
0. 整体创新点通俗解读¶
痛点直击 (The "Why")
传统CPU设计陷入了“非此即彼”的困境,这在处理现代应用时非常难受:
- Out-of-Order (OoO) 核心:擅长挖掘单线程内的 Instruction-Level Parallelism (ILP),但一旦遇到稀疏、不规则的内存访问(比如Sparse Matrix Multiplication),就会因为大量的Cache Miss而卡住。它的大型Reorder Buffer (ROB) 和 Reservation Station (RS) 会被长延迟的Load指令占满,导致整个流水线几乎停滞,资源严重浪费。
- In-Order (InO) 核心:轻量级,可以轻松跑很多线程来利用 Thread-Level Parallelism (TLP),不怕内存停顿。但它完全无法利用ILP,在计算密集型任务上性能很差。
- 现有SMT方案:要么像Intel那样只支持2个OoO线程(TLP不足),要么像MorphCore那样在OoO模式和InO模式之间切换(不能同时利用两者)。这就导致当一个应用的工作负载在ILP和TLP之间动态变化时(这在现实世界中很常见),CPU总有一部分资源是闲置或低效的。
通俗比方 (The Analogy)
想象你有一个高效的专业厨师(OoO线程)和一群手脚麻利但只会按菜谱一步步做的帮厨(InO线程),他们共用一个厨房(CPU核心)。
- 在做一道需要复杂火候和调味的精致料理(计算密集型任务)时,专业厨师大显身手,帮厨们只能干看着。
- 但当任务变成处理一大堆需要从不同冰箱里取食材的简单沙拉(内存密集型、稀疏任务)时,专业厨师会因为频繁跑去远处的冰箱(Cache Miss)而大部分时间在发呆等待。此时,如果让帮厨们也一起动手,每人负责几份沙拉,即使他们效率低一点,也能把空闲的灶台和案板(执行单元)都用起来,整体出餐速度反而更快。
SHADOW的核心思想就是:别让他们互相等待或切换角色,让他们在同一时间、同一厨房里,各干各最擅长的活! 工作量会根据谁“手快”自动分配——厨师快时多干点,厨师被冰箱拖慢时,帮厨就多接点活。
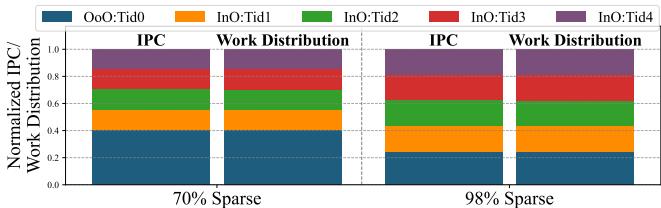
Figure 1: SHADOW dynamically redistributes work as IPC changes.High ILP skews execution toward the OoO thread, while a low IPC distributes the work more evenly. SHADOW adapts to the application without software intervention.
关键一招 (The "How")
作者没有去发明新的硬件加速器,也没有搞复杂的指令流拆分,而是对SMT架构做了一个精妙的“不对称”改造:
- 在同一物理核心内,并行运行两种完全不同类型的线程:一个(或少数几个)全功能的 OoO线程,加上多个极度轻量化的 InO线程。
- 硬件层面做了干净的隔离与共享:
- 共享:Fetch/Decode前端、执行单元(ALU等)、Cache。
- 隔离:OoO线程使用完整的重命名、ROB、Load/Store Queue进行推测执行;而InO线程则完全绕过这些昂贵的结构,它们使用简单的FIFO队列和非推测执行,只消耗极少的额外硬件(主要是寄存器)。
- 通过软件工作窃取(Work Stealing)实现动态负载均衡:所有线程(无论OoO还是InO)都从一个公共任务池里“抢”活干。当OoO线程因为高ILP而跑得快时,它自然能抢到更多任务;当它被内存延迟拖慢时,IPC下降,抢活的速度变慢,InO线程就能抢到更多任务,从而自动将负载向TLP倾斜。
这个设计的绝妙之处在于,它用极低的硬件开销(仅1%面积/功耗),在一个核心内同时具备了深度ILP挖掘能力和宽裕的TLP扩展能力,并且能无缝、动态地在两者之间取得最佳平衡,完美适应了现代应用中普遍存在的、不断变化的并行性需求。最终在评测中实现了最高3.16倍的加速比,平均提升1.33倍。
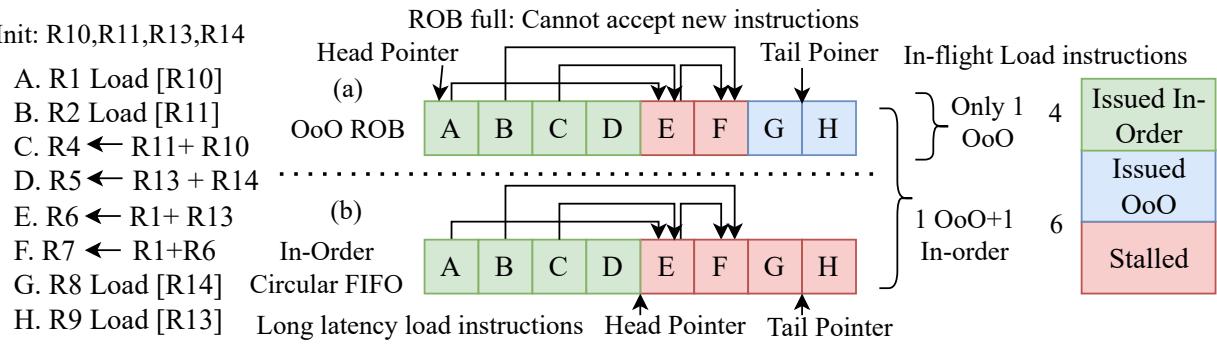
Figure 9: Impact of adding an InO Thread to an OoO system: An illustrative assembly example.
1. 异构线程并发执行 (Asymmetric Thread Co-execution)¶
痛点直击 (The "Why")
- 传统CPU设计陷入了“非此即彼”的困境。Out-of-Order (OoO) 核心擅长挖掘ILP (Instruction-Level Parallelism),但一旦遇到内存密集型(memory-bound)任务,比如处理稀疏矩阵(SpMM),就会因为大量的缓存未命中而卡住。它的**Reorder Buffer **(ROB) 和 **Reservation Station **(RS) 会被那些等待内存数据的指令占满,导致整个流水线几乎停滞。
- 另一方面,**In-Order (InO) 核心虽然轻量、能跑很多线程来利用TLP **(Thread-Level Parallelism),但它无法隐藏长延迟的内存访问,单个线程性能很差,对于计算密集型任务完全无能为力。
- 现有的解决方案都不够优雅:
- 模式切换(如 MorphCore):要么全开OoO,要么全切InO。但现实中的程序往往是混合的,一部分代码需要ILP,另一部分需要TLP。在两者之间硬切换,会导致资源在切换瞬间被浪费。
- 指令级分流(如 FIFOShelf):试图在指令层面决定走OoO还是InO路径。这引入了巨大的复杂性,需要跨路径跟踪依赖、处理错误预测恢复等,硬件开销大。
通俗比方 (The Analogy)
想象一个工厂车间(CPU核心)。
- 以前的做法是,要么把整个车间都布置成高度自动化的精密生产线(OoO),能高效处理复杂的定制订单(高ILP任务),但一旦某个零件(数据)缺货(cache miss),整条线就得停下来等,工人(执行单元)全都闲着。
- 要么就把车间改造成大量简单的工作台(InO),每个工作台处理一个简单的标准件(TLP任务)。这样即使某个工作台缺货,其他工作台还能继续干。但面对复杂的定制订单,这些简单工作台根本搞不定。
- SHADOW的做法是:在一个车间里,同时保留一条精密生产线和几个简单工作台。复杂的订单交给精密线,大批量的标准件分给简单工作台。它们共享车间的公共资源(如电力、物流),但互不干扰。当精密线因为缺货而慢下来时,简单工作台可以多接点活,保证整个车间的机器都在转,不会闲置。这就是异构线程并发执行的核心思想——让不同特性的任务,由最适合的“工人”去处理,而且他们能在一个屋檐下协同工作。
Figure 1: SHADOW dynamically redistributes work as IPC changes.High ILP skews execution toward the OoO thread, while a low IPC distributes the work more evenly. SHADOW adapts to the application without software intervention.
关键一招 (The "How")
作者并没有发明新的执行单元,也没有搞复杂的指令调度器。他们的巧妙之处在于在SMT的线程粒度上做文章,并简化了InO线程的硬件需求。
- 线程级分区,而非指令级分流:SHADOW将软件线程整体分配给两种执行模式。一个线程要么是OoO线程,要么是InO线程。这彻底规避了FIFOShelf那种跨路径依赖追踪的噩梦。
- 为InO线程“减负”:InO线程被设计得极其轻量:
- 绕过重命名(Rename):直接使用**Architectural Register File **(ARF),省去了复杂的重命名逻辑和物理寄存器分配。
- 绕过ROB:不需要乱序提交,因此不占用宝贵的ROB资源。它们通过一个简单的per-thread FIFO queue进入**Reservation Station **(RS)。
- 简化唤醒与选择:每个InO线程在RS中只占一个槽位,依赖检查通过一个轻量级的scoreboard完成,无需复杂的CAM匹配。
- 动态工作分配:通过一个简单的软件工作窃取(work stealing)机制(见Algorithm 1),让线程自己去抢活干。性能强的OoO线程(高IPC时)自然能抢到更多活;当它因内存延迟变慢时,轻快的InO线程就能抢到更多份额。这种负载均衡是自适应且去中心化的,无需硬件干预。
Figure 9: Impact of adding an InO Thread to an OoO system: An illustrative assembly example.
这种设计的精妙在于,它用极低的硬件开销(仅1%的面积和功耗增加)就实现了ILP和TLP的无缝融合。OoO线程负责攻坚克难,InO线程负责人海战术,两者在同一个核心内各司其职,最大化了硬件资源的利用率。
2. 动态工作窃取机制 (Dynamic Work Stealing Mechanism)¶
痛点直击
传统 SMT(Simultaneous Multi-Threading)架构在处理 内存密集型且稀疏性高 的工作负载时,会陷入一个两难困境:
- 如果只用 OoO (Out-of-Order) 线程,一旦遇到大量 L2 cache miss,其巨大的 ROB (Reorder Buffer) 会被长延迟的 load 指令占满,导致整个流水线“堵死”,新的指令无法发射,IPC (Instructions Per Cycle) 断崖式下跌。
- 如果只用 InO (In-Order) 线程,虽然能通过高 TLP (Thread-Level Parallelism) 维持一定的吞吐,但完全放弃了 OoO 在计算密集或缓存友好阶段能榨取的 ILP (Instruction-Level Parallelism),白白浪费了核心的高性能潜力。
更糟糕的是,像 MorphCore 这样的方案采用 模式切换,要么全 OoO,要么全 InO。但现实中的程序(比如 SpMM)往往是 动态变化 的:一开始数据在缓存里,OoO 跑得飞快;跑着跑着数据变稀疏,cache miss 暴增,OoO 就卡住了。这种“一刀切”的切换方式,无法做到 细粒度、实时 的资源平衡,总有一部分硬件在“摸鱼”。
通俗比方
想象一个餐厅厨房(CPU 核心),里面有:
- 1 个 米其林大厨 (OoO thread):技艺精湛,能同时处理多道复杂的菜(高 ILP),但一旦等某个特殊食材(内存数据)从很远的仓库(DRAM)运来,他就会站在原地干等,手里的活全停了。
- 4 个 高效学徒 (InO threads):手艺简单,只能按顺序做菜(无 ILP),但他们不需要等特殊食材,手头有啥就做啥,而且人多力量大(高 TLP)。
传统的做法是:要么只让大厨干活(OoO-only),要么把大厨赶出去,让四个学徒上(InO-only)。但 SHADOW 的聪明之处在于,它让大厨和学徒 共用一个厨房,并且引入了一个 自助取单系统。
这个系统就是 动态工作窃取。厨房中央有个任务板(currentChunk 全局计数器),上面贴着所有待做的菜(workload chunks)。无论是大厨还是学徒,只要自己手上的活干完了,就立刻去任务板上 抢一张新单子。当食材供应顺畅(低 sparsity, 高 IPC)时,大厨手脚麻利,总能抢到更多的单子。一旦食材供应不上(高 sparsity, 低 IPC),大厨被卡住,学徒们就能迅速把剩下的单子抢光,保证厨房的炉灶(执行单元)始终在烧火,不会冷下来。

Figure 19: Distribution of work across threads with dynamic work stealing for various degrees of sparsity.
这张图完美展示了这个过程:随着稀疏度(sparsity)增加,OoO 线程的 IPC 下降,它能“偷”到的工作量(蓝色柱子)就越来越少,而 InO 线程(绿色柱子)则接管了大部分工作,实现了 负载的自动、无缝迁移。
关键一招
作者并没有设计一个复杂的、由硬件控制的中央调度器来分配任务。相反,他们做了一个极其巧妙的 逻辑转换:将 负载均衡的责任完全下放给软件线程自身,利用一个简单的 去中心化锁(lock) 来实现。
具体来说,就是在原来的并行程序(如 Pthreads)中,将静态的任务划分(比如每个线程固定处理 1/N 的数据)替换为以下动态逻辑:
- 所有线程共享一个全局的
currentChunk计数器。 - 每个线程在一个循环里不断执行:
- 加锁,从
currentChunk获取自己下一批要处理的工作索引,并原子地递增currentChunk。 - 解锁,然后专心处理这批工作。
- 处理完后,回到循环开头,尝试“偷”下一批工作。
- 加锁,从
这个机制的精妙之处在于:
- 零硬件开销:硬件不需要任何新的仲裁或调度逻辑,完全复用现有的多线程和原子操作支持。
- 自适应性:线程的“偷窃”频率天然地与其执行速度(IPC)成正比。快的线程(高 ILP 时的 OoO)自然能更快地回到循环起点去偷下一块,慢的线程(被内存卡住的 OoO)则偷得少。InO 线程因为没有 ROB 压力,在内存瓶颈期反而成了“偷窃”主力。
- 涌现的平衡:整个系统的最优负载分配不是被“计算”出来的,而是作为所有线程独立、贪婪行为的 涌现结果 (emergent property) 自然形成的。
通过这一招,SHADOW 用最朴素的软件协同,解决了最棘手的硬件资源动态平衡问题,真正做到了 “随 workload 而动”。
3. 轻量级顺序线程设计 (Lightweight In-Order Threads)¶
痛点直击 (The "Why")
传统CPU设计陷入了“鱼与熊掌不可兼得”的困境:
- Out-of-Order (OoO) 核心:为了榨取 Instruction-Level Parallelism (ILP),配备了庞大的 Reorder Buffer (ROB)、Reservation Station (RS) 和复杂的 寄存器重命名 逻辑。这套机制在计算密集型任务上所向披靡,但一旦遇到 内存密集型 工作负载(比如稀疏矩阵运算 SpMM),就会因为频繁的 cache miss 而卡住。此时,昂贵的 OoO 硬件资源大部分时间都在空转等待数据,造成了巨大的浪费。
- 增加 OoO 线程? 不行。因为 ROB、物理寄存器文件 (PRF) 等关键资源是所有 OoO 线程共享且竞争激烈的。增加线程数很快就会导致 资源争用,IPC(每周期指令数)不升反降,如 Figure 4 所示。
- 纯 In-Order 核心? 也不行。虽然它们轻量、能跑很多线程来提升 Thread-Level Parallelism (TLP),但在需要高 ILP 的场景下性能孱弱,无法兼顾通用性。
所以,核心痛点是:如何在同一个核心里,既保留强大的单线程 OoO 性能,又能以极低的代价引入大量轻量级线程来应对内存瓶颈,实现 ILP 和 TLP 的动态平衡?
通俗比方 (The Analogy)
想象一个高端餐厅(代表 CPU 核心)。
- OoO 厨师 就像米其林主厨,他有一套极其复杂的 中央调度系统(ROB/重命名),可以同时处理多张订单(指令),并根据食材(数据)何时到位来动态调整烹饪顺序,效率极高。但如果供应商(内存)迟迟不送货,这位主厨和他的整套昂贵系统就只能干等着。
- SHADOW 的做法 是,在同一个厨房里,除了这位主厨,还雇佣了几位 实习生(InO 线程)。这些实习生没有复杂的调度系统,他们只遵循一个简单的 FIFO 待办清单。当主厨因为缺货而停工时,实习生们可以立刻接手那些不需要复杂调度、只需要按部就班执行的任务(比如打包、洗菜等内存操作),充分利用厨房里闲置的灶台(执行单元)。
关键在于,这些实习生的“工位”非常简单,几乎不占用厨房额外的空间(硬件开销极小),却能在主厨“卡壳”时维持整个厨房的产出。
关键一招 (The "How")
作者并没有试图去改造或扩展那个庞大而昂贵的 OoO 引擎,而是巧妙地在核心内部 开辟了一条完全独立、极度简化的执行通道 给 InO 线程。这招的关键在于 “绕过”和“简化”:
-
绕过重命名和 ROB:InO 线程的指令 完全跳过 了 OoO 流水线中最复杂、最占面积的两个阶段——寄存器重命名和 ROB 分配。这意味着它们不会消耗宝贵的 PRF 条目和 ROB 槽位,从根本上避免了与 OoO 线程的资源争抢。
-
采用极简依赖跟踪:为了保证顺序执行的正确性,InO 线程没有使用 OoO 那种基于 CAM(内容寻址存储器)的广播式唤醒机制,而是为每个线程配备了一个超轻量的 记分板 (scoreboard)。这个记分板只是一个简单的位图,用来跟踪源寄存器是否就绪,硬件开销微乎其微。
-
非推测执行:InO 线程不进行任何分支预测和推测执行。遇到分支就老实等待结果,这省去了 Return Address Stack (RAS) 和 错误路径恢复 的所有逻辑,进一步降低了复杂度。
-
共享后端,独占前端状态:这些轻量级线程与 OoO 线程共享 ALU、Cache 等后端执行资源,但拥有自己独立的 PC(程序计数器)和简单的 FIFO 队列。这种设计让它们能无缝融入现有核心,仅需增加少量的多路选择器和控制逻辑。
正是这一系列“做减法”的设计,使得增加多个 InO 线程带来的 面积和功耗开销仅为 1%(见 Table 4),却能显著提升在内存瓶颈场景下的 TLP 和整体吞吐量。Figure 9 清晰地展示了这种设计的优势:当 OoO 线程因长延迟加载而占满 ROB 时,InO 线程依然可以利用空闲的执行单元继续工作,有效缓解了 ROB 压力。
Figure 9: Impact of adding an InO Thread to an OoO system: An illustrative assembly example.

Table 4: Hardware overhead of SHADOW
4. 运行时可重构资源分区 (Runtime-Configurable Resource Partitioning)¶
痛点直击
- 传统CPU的SMT(Simultaneous Multi-Threading)设计是“静态对称”的,所有硬件线程共享一套固定的资源池(比如ROB、RS、PRF),并且执行模式完全一样(要么全是OoO,要么全是InO)。
- 这在面对动态变化的工作负载时非常难受:当程序从计算密集型(高ILP)切换到访存密集型(高TLP)时,CPU无法随之调整。例如,在稀疏矩阵乘法(SpMM)中,随着稀疏度增加,OoO线程因大量Cache Miss而卡住,ROB被长延迟Load指令占满,但此时空闲的执行单元却无法被利用,因为没有额外的轻量级线程来填充。
- 先前的方案如MorphCore虽然能切换模式(2-OoO ↔ 8-InO),但它是“非此即彼”的,不能同时兼顾ILP和TLP。这就导致在混合型负载下,总有一部分硬件资源在“摸鱼”。
通俗比方
- 想象你管理一个工厂车间,里面有精密机床(代表OoO引擎,适合做复杂、高价值的单件)和流水线工人(代表InO线程,适合做大量简单、重复的任务)。
- 传统SMT就像规定这个车间只能全员开机床,或者全员上流水线。当订单突然从“定制工艺品”变成“大批量螺丝”时,你必须停工半天来重新布置整个车间。
- 而SHADOW的做法是,把车间设计成可重构的。它既有几台固定的精密机床,又预留了可以快速搭建或拆除的简易工位。当订单变化时,你不需要停工,只需发一个指令,就能立刻调整机床和工位的比例,让两者同时开工,各干各的活,最大化利用整个车间的空间和人力。
关键一招
- 作者的核心洞察是:不需要为不同模式准备两套独立的硬件,而是通过软件指令在上下文切换时,对同一套硬件资源进行逻辑上的动态切分。
- 具体来说,他们引入了一个新的系统调用
shdw_cfg <#OoO>, <#InO>。当操作系统进行上下文切换时,会执行这个指令,从而:- 重置前端:激活指定数量的OoO和InO程序计数器(PC)。
- 重构重命名表:将物理寄存器文件(PRF)按需分配。每个InO线程只分到与其架构寄存器(ARF)数量相等的物理寄存器(因为它不投机,不需要额外空间),剩下的全部留给OoO线程。
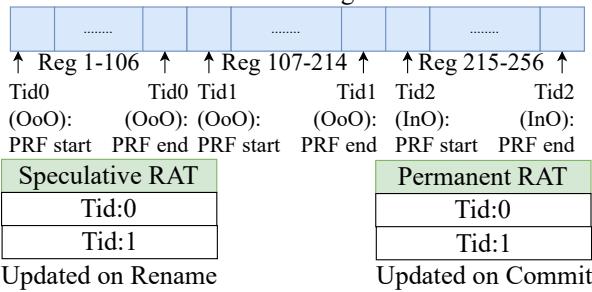
Figure 8: Register File partitioning in SHADOW.
- 分区后端资源:ROB和RS这些关键结构也被静态划分。OoO线程共享大部分ROB/RS条目,而每个InO线程只占用一个极简的FIFO队列和一个RS条目,几乎不消耗这些昂贵的资源。
- 这个“扭转”在于,它把资源配置的决策权从硬件自动调度(容易产生争用和低效)转移到了软件显式控制(由程序员或运行时根据 workload 特性选择最优配置),实现了零成本的模式共存。InO线程因为绕过了重命名和ROB,其硬件开销极小(仅1%面积 overhead),却能有效利用OoO线程因stall而空闲的执行单元。
Figure 9: Impact of adding an InO Thread to an OoO system: An illustrative assembly example.