Prodigy: Improving the Memory Latency of Data-Indirect Irregular Workloads Using Hardware-Software Co-Design 通俗讲解¶
0. 整体创新点通俗解读¶
痛点直击 (The "Why")
- 传统的 硬件预取器(如 GHB-based prefetcher)依赖于地址的空间局部性或固定步长,但像图计算、稀疏矩阵这类不规则工作负载(irregular workloads)的内存访问是“跳跃式”的,完全无法预测,导致这些预取器基本失效。
- 纯软件预取虽然知道程序逻辑,但它是在编译时静态插入指令的,无法感知运行时 CPU 的实际执行速度。如果 CPU 跑得快,预取的数据还没到;如果 CPU 跑得慢,预取的数据早就被挤出缓存了,造成缓存污染。这就是典型的“顾头不顾尾”。
- 之前一些针对图计算的专用硬件方案(如 IMP, DROPLET)要么只能处理简单的指针跳转(single-valued indirection),要么只覆盖部分数据结构,无法应对更复杂的、通过一个数组的两个值来界定另一个数组访问范围的模式(ranged indirection,比如 CSR 格式中通过 offset 数组找 edge 数组的一段邻居)。
通俗比方 (The Analogy) 想象你要在一个巨大的、杂乱无章的图书馆里找书。传统预取器就像一个只会沿着书架一行行扫的机器人,对你要找的书毫无概念。而 Prodigy 则像是你给了图书管理员一张藏宝图(DIG)。这张图不是告诉你具体哪本书,而是清晰地画出了“先去 A 区域拿一张索引卡,索引卡上写着要去 B 区域的第 X 排;到了 B 区域,你会发现一整排书(从 Y 到 Z)都是你需要的”。管理员(硬件预取器)拿着这张图,就能在你真正走到 A 区域之前,就提前把 B 区域那整排书都搬到你手边的桌子上,让你随用随取。
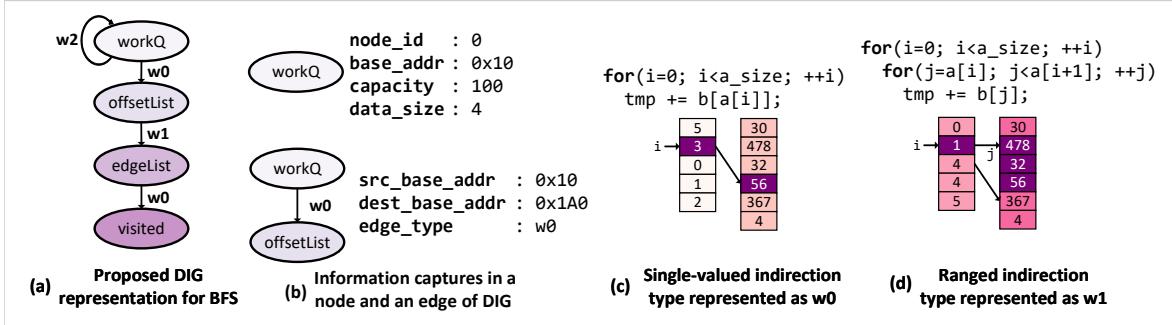
Figure 5. Proposed Data Indirection Graph (DIG) representation—(a) example representation for BFS, (b) data structure memory layout and algorithmic traversal information captured by a DIG node and a weighted DIG edge respectively; two unique data-dependent indirection patterns supported by Prodigy—(c) single-valued indirection, and (d) ranged indirection.
关键一招 (The "How") 作者的核心洞察是:虽然不规则工作负载的访问地址千变万化,但其背后的数据结构遍历模式却可以被抽象为两种基本操作——single-valued indirection 和 ranged indirection。于是,他们没有试图让硬件去“学习”复杂的地址流,而是设计了一个精巧的软硬协同流程:
- 第一步(软件侧):通过一个 LLVM 编译器 Pass,自动分析源代码,将程序中关键数据结构(如 CSR 的 offset 和 edge 数组)及其相互间的访问关系,编码成一个极其紧凑的数据间接图(Data Indirection Graph, DIG)。这个 DIG 就是上面提到的“藏宝图”。
- 第二步(硬件侧):设计了一个超低成本的硬件预取器,它内部有专门的存储(总共只需 0.8KB)来存放这个 DIG。当 CPU 发出一个对“触发节点”(如 BFS 的 work queue)的请求时,预取器就根据 DIG 上的指引,立刻启动一个多级预取链。
- 最关键的扭转:这个硬件预取器不是盲目地一路预取到底。它引入了一个叫 PFHR(PreFetch status Handling Register)的结构来跟踪每个预取链的状态,并且能动态感知 CPU 的执行进度。一旦发现 CPU 已经快要追上预取器了,它就会果断丢弃当前这条可能来不及用上的预取链,转而去为后面的请求预取,从而保证了预取的时效性(timeliness),避免了缓存污染。
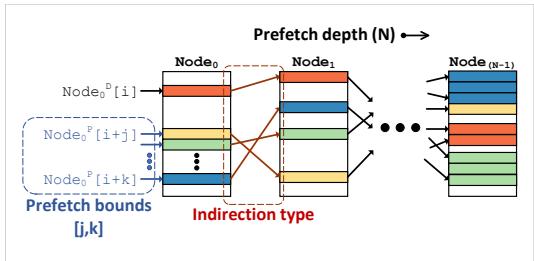
Figure 9. Memory structures used in Prodigy—(a) node table, (b) edge index table, and (c) edge table for storing the DIG representation, (d) prefetch status handling register (PFHR) file tracking progress for live prefetch sequences and issuing non-blocking prefetches. Figure 10. Prefetching algorithm initiates prefetch sequences between prefetch bounds j and k and advances a prefetch sequence using software-defined indirection types. The superscripts denote a demand (D) or a prefetch (P) access.
最终效果就是,通过这种“软件提供语义地图,硬件动态精准导航”的方式,Prodigy 以极低的硬件开销(0.8KB),实现了对复杂不规则内存访问模式的高效预取,在真实 workload 上平均获得了 2.6倍 的性能提升。
| 对比方案 | 平均性能提升 (vs. 无预取) | 硬件存储开销 |
|---|---|---|
| **Prodigy **(本文) | 2.6× | 0.8KB |
| Ainsworth & Jones [6] | ~1.7× | ~1.6KB |
| DROPLET [15] | ~1.6× | ~7.8KB |
| IMP [99] | ~1.1× | ~1.1KB |
1. Data Indirection Graph (DIG)¶
之前那些通用的硬件预取器(比如 GHB-based prefetcher)在处理图计算、稀疏矩阵这类不规则工作负载时,简直是在“盲人摸象”。
- 它们依赖空间局部性或简单的地址相关性,但像 CSR 格式的图,其访问模式是 data-dependent 的:你得先读
offset[i]和offset[i+1]这两个值,才能知道接下来要一口气读edge[offset[i]]到edge[offset[i+1]-1]这一整段数据。 - 传统的预取器根本看不懂这种“先查表再决定读哪”的逻辑。它们要么完全失效,要么只能瞎猜,甚至因为乱预取而污染缓存,让性能更差。
- 而纯软件预取呢?它虽然知道程序逻辑,但它是在编译时就插好指令的“死命令”,无法感知运行时 CPU 执行的快慢。如果 CPU 跑得慢,预取的数据早就被挤出缓存了;如果 CPU 跑得快,预取又跟不上,还是得等内存。
通俗比方
想象你要在一个巨大的、没有目录的图书馆里找书。你的任务不是找一本,而是执行一个复杂的查询:“找出作者A写的、所有出版年份在B和C之间的书,然后把这些书的第一页内容都复印一份”。
- 传统预取器就像一个只会按书架顺序拿书的机器人。它看到你拿了书架1的书,就以为你下一个要拿书架2的,结果你其实要去书架1000查作者索引。
- 软件预取就像你自己提前写好了一张超长的待办清单。但如果你中途被人打断(比如CPU流水线停顿),清单就作废了,或者你执行得太快,清单还没写完。
- Prodigy 的 DIG 做的事情,相当于你给了机器人一张流程图(就是那个 Data Indirection Graph)。这张图上清晰地画着:
- 第一步:去“作者索引区”(
offset数组)找到作者A对应的起始和结束位置。 - 第二步:根据这两个位置,去“图书正文区”(
edge数组)批量拿书。 - 第三步:对每本拿到的书,再去“图书属性区”(
visited数组)查一下状态。
- 第一步:去“作者索引区”(
这个机器人(硬件预取器)拿着这张流程图,就能在你真正走到“作者索引区”并开始查询时,立刻明白你下一步、下下一步要干什么,并提前把书搬到你手边的桌子上(L1 cache)。
Figure 5. Proposed Data Indirection Graph (DIG) representation—(a) example representation for BFS, (b) data structure memory layout and algorithmic traversal information captured by a DIG node and a weighted DIG edge respectively; two unique data-dependent indirection patterns supported by Prodigy—(c) single-valued indirection, and (d) ranged indirection.
关键一招
作者并没有试图让硬件去“学习”或“猜测”这种复杂的访问模式,而是做了一个非常聪明的职责分离:
- 软件(编译器)负责“翻译”:在编译阶段,通过静态分析,把程序里那些复杂的、由数据驱动的内存访问逻辑,翻译成一种极其紧凑的、与具体数据格式无关的图结构——DIG。这个 DIG 只包含两类核心信息:
- 节点 (Node):代表一个数据结构(如
offset,edge),记录其内存布局(基地址、大小、元素尺寸)。 - 边 (Edge):代表数据结构间的访问关系,明确标注是 single-valued indirection(用一个值去索引,如
visited[vertex_id])还是 ranged indirection(用一对值确定一个范围,如edge[offset[i] ... offset[i+1]])。
- 节点 (Node):代表一个数据结构(如
- 硬件(预取器)负责“执行”:硬件不再需要复杂的模式识别电路。它只需要一个很小的本地存储(仅 0.8KB!)来存放这个 DIG,然后像一个“图遍历引擎”一样工作:
- 当 CPU 发出一个对“触发节点”(如 BFS 中的
workQueue)的请求时,硬件就知道一个预取序列开始了。 - 它根据 DIG 中的边,动态地、一步步地生成后续的预取地址。对于 ranged indirection,它甚至能一次性发出对整个范围的预取请求。
- 最关键的是,它引入了 PFHR (PreFetch status Handling Register) 文件来跟踪多个并行的预取序列,并能根据 CPU 的实际执行进度(通过监听 load 请求)动态丢弃那些已经没用的、过时的预取,保证预取的“时效性”。
- 当 CPU 发出一个对“触发节点”(如 BFS 中的
这一招的核心扭转在于:把“理解语义”的重担交给了离源码最近、最懂逻辑的编译器,而把“高效执行”的任务留给了硬件。两者通过 DIG 这个精巧的“契约”进行沟通,实现了“1+1远大于2”的效果。
2. 编译器自动分析与代码生成¶
痛点直击
- 以前处理像图计算、稀疏矩阵这类 irregular workloads 时,硬件 prefetcher 几乎是瞎子。因为它们的内存访问模式不是简单的步长或流式,而是由数据内容决定的(data-dependent),比如
A[B[i]]这种间接寻址。 - 程序员可以手动加注解告诉硬件怎么预取(就像论文里提到的
registerNode()那一套 API),但这活儿又脏又累,还容易出错。你得对算法和数据结构有非常深的理解,才能准确地把那些复杂的遍历关系描述清楚。 - 所以问题就卡在这儿了:理想很丰满(用语义信息指导预取效果极佳),但现实很骨感(没人愿意/能干好这个体力活)。这就导致再好的硬件设计也难以推广。
通俗比方
- 想象你要给一个完全没见过乐高的新手(硬件 prefetcher)一套图纸(DIG),让他能提前把下一块要用的积木(数据)找出来。最笨的办法是你(程序员)自己对照着说明书,手动画一张新图纸给他。
- 而 Prodigy 的做法是,直接给了他一个智能扫描仪(compiler pass)。这个扫描仪能自动读取原始的乐高说明书(源代码),理解里面的拼装逻辑(比如“先找到红色底座,然后在它的第3个接口上插一个蓝色横梁”),并自动生成一份新手能看懂的、清晰的行动指南(DIG)。你完全不用动手,机器就替你完成了从“人类知识”到“机器指令”的翻译。
关键一招 作者并没有要求程序员做额外工作,而是巧妙地在 LLVM 编译流程中插入了一个分析器。这个分析器干了两件核心的事:
-
静态“侦探”工作:
- 它首先扫描代码中的内存分配点(如
malloc),把这些当作潜在的 DIG Node 候选,并记录下它们的基地址、大小等布局信息。 - 接着,它追踪这些分配出来的内存是如何被使用的。它会特别关注那些嵌套的数组访问模式,比如
b[a[i]]。通过分析 LLVM IR 中的地址计算(AddrCalc)和加载(Load)指令之间的依赖关系,它能自动识别出两种关键模式:- Single-valued indirection:
a[i]的结果直接作为b的索引。 - Ranged indirection:
a[i]和a[i+1]的结果共同决定了b中一个连续区间的访问范围(这正是 CSR 格式的核心)。
- Single-valued indirection:
- 它首先扫描代码中的内存分配点(如
-
自动化“翻译”工作:
- 一旦识别出这些模式和相关的数据结构,编译器 pass 就会自动在二进制代码中插入对 Prodigy API 的调用(如
registerNode,registerTravEdge)。 - 这些 API 调用会在程序运行初期被执行,从而动态地在硬件上构建出完整的 **Data Indirection Graph **(DIG)。这样,硬件 prefetcher 在程序真正开始密集计算前,就已经“胸有成竹”,知道了整个数据遍历的路线图。
- 一旦识别出这些模式和相关的数据结构,编译器 pass 就会自动在二进制代码中插入对 Prodigy API 的调用(如
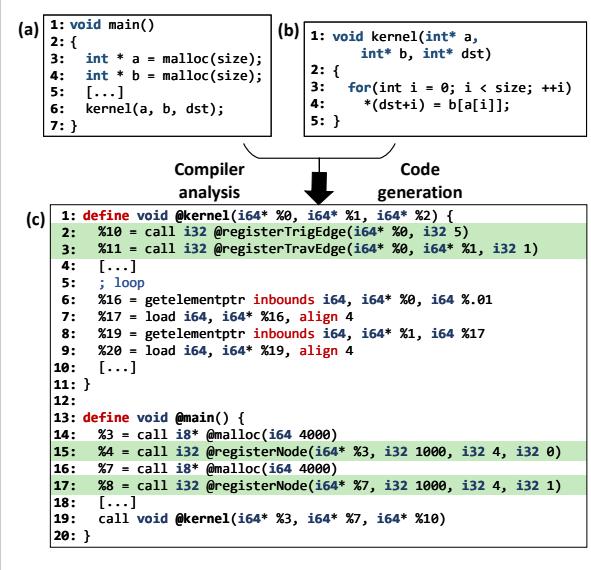
Figure 7. An example C program (a) and (b), translated into LLVM IR (c) and instrumented with our API calls to register DIG nodes and edges. Figure 8. Pseudocode of Prodigy’s compiler analyses for (a) node identification, (b) single-valued indirection, (c) ranged indirection, and (d) runtime.
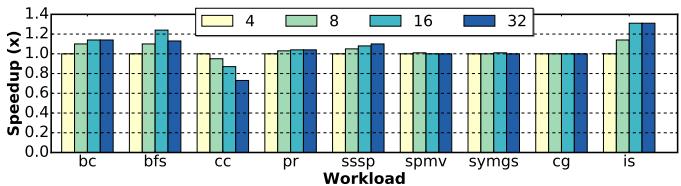
Figure 12. Design space exploration on the PFHR file size. Performance of each configuration is normalized to 4 entries.
这个设计的精妙之处在于,它把一个高度依赖领域知识的、易错的手动过程,转化成了一个通用的、自动化的编译期分析任务。这极大地降低了使用门槛,让 Prodigy 的强大能力可以被广泛应用,而不仅仅局限于少数专家优化的场景。
3. 基于DIG的低开销硬件预取器¶
之前那些通用的硬件预取器(比如 GHB-based prefetcher)在处理图计算、稀疏矩阵这类不规则工作负载时,简直是在“盲人摸象”。它们依赖地址间的空间或时间局部性来预测下一个要访问的地址,但像 CSR 格式的图遍历,其内存访问模式是由数据内容动态决定的——今天访问哪个邻居,完全取决于当前顶点在 offset 数组里的值。这种数据依赖的间接寻址(data-dependent indirection)让传统预取器彻底失效,导致 CPU 被 DRAM stalls 拖垮,性能瓶颈极其严重。
想象一下,你要在一个巨大的、没有目录的图书馆里找书。传统预取器就像一个只会按书架顺序一本本拿书的助手,效率极低。而 Prodigy 的做法是:在你开始找书前,先给你一张藏宝图(DIG)。这张图不是告诉你具体哪本书在哪,而是清晰地标出了“区域A的卡片能指引你去区域B的一段书架,而区域B每本书的附录又能带你去区域C的某本书”这样的逻辑关系。硬件预取器拿到这张图后,就变成了一个聪明的向导:它看到你拿到了区域A的一张卡片(demand access),立刻就能根据藏宝图,提前把区域B对应书架上的一整排书(ranged indirection)都搬到你的桌边;等你翻到其中一本书的附录时,它又已经把区域C那本指定的书(single-valued indirection)准备好了。整个过程流畅且精准,因为它知道的是“规则”,而不是死记硬背“地址”。
Figure 5. Proposed Data Indirection Graph (DIG) representation—(a) example representation for BFS, (b) data structure memory layout and algorithmic traversal information captured by a DIG node and a weighted DIG edge respectively; two unique data-dependent indirection patterns supported by Prodigy—(c) single-valued indirection, and (d) ranged indirection.
作者解决这个问题的关键一招,在于将软件的静态语义知识与硬件的动态执行信息完美桥接,并且用一种极度紧凑的方式编码。
- 他们没有试图在硬件里用复杂的模式识别电路去“学习”这些不规则模式(那样成本太高),而是设计了一个叫 Data Indirection Graph (DIG) 的中间表示。
- 这个 DIG 由编译器在编译期自动分析源代码生成(也可以手动标注),它只干一件事:用一个带权重的有向图来抽象程序中关键数据结构之间的两种核心间接访问关系:
- **Single-valued indirection **(w0):一个数据结构里的值作为索引,去访问另一个数据结构里的单个元素(如用顶点ID查属性)。
- **Ranged indirection **(w1):一个数据结构里的一对值(base, bound)定义了对另一个数据结构的一段连续访问范围(如用offset数组查邻居列表)。
- 这个 DIG 被编码后,仅需 0.8KB 的存储空间就能放进硬件。硬件预取器在运行时,通过监听 L1D cache 的请求,一旦发现对“触发节点”(trigger edge)的访问,就立刻启动预取。
- 预取器会根据 DIG 中的边(edge)类型,动态地解析刚预取回来的数据,并据此计算出下一批要预取的地址。为了保证预取的“及时性”(timeliness),它还引入了 **PFHR **(PreFetch status Handling Register) 文件来跟踪多个并行的预取序列,并能在 CPU 追上预取进度时果断丢弃过时的序列,避免污染缓存。
Figure 9. Memory structures used in Prodigy—(a) node table, (b) edge index table, and (c) edge table for storing the DIG representation, (d) prefetch status handling register (PFHR) file tracking progress for live prefetch sequences and issuing non-blocking prefetches. Figure 10. Prefetching algorithm initiates prefetch sequences between prefetch bounds j and k and advances a prefetch sequence using software-defined indirection types. The superscripts denote a demand (D) or a prefetch (P) access.
最终效果就是,这个基于 DIG 的预取器,以几乎可以忽略的硬件开销(0.8KB),实现了对复杂不规则内存访问模式的精准预判,从而将平均性能提升了 2.6倍,并节省了 1.6倍 的能耗。
4. 预取状态处理寄存器文件 (PFHR)¶
之前做硬件预取(Hardware Prefetching)处理像图计算这种不规则负载时,有个特别难受的地方:预取器一旦启动一个复杂的、跨多个数据结构的预取链(比如从 work queue -> offset list -> edge list -> visited list),就必须傻乎乎地等这条链上所有请求都完成才能干下一件事。这就像你派了一个快递员去帮你买咖啡,但他必须先去超市买咖啡豆,再去磨坊磨粉,最后才去咖啡机冲泡——在这整个漫长的过程中,他被“阻塞”了,没法接新活。更要命的是,如果你自己走路比他骑车还快,等他把咖啡送到时,你早就喝完水走人了,这杯咖啡就成了过时的垃圾,白白占着你的背包(Cache),这就是所谓的预取时效性(Prefetch Timeliness)问题。
通俗比方 你可以把 PFHR(PreFetch status Handling Register)文件想象成一个智能外卖调度中心的看板。以前的预取器只有一个脑子,记不住多件事。现在,这个调度中心有了一块大看板(PFHR file),上面有很多小卡片(PFHR entries)。每当你(CPU核心)点了一份“复杂套餐”(触发一个预取序列),调度中心就立刻在看板上挂一张新卡片,上面写着:
- 这单是谁点的(Node ID)
- 从哪开始送的(Prefetch trigger address)
- 现在已经派出去但还没送到的有哪些菜(Outstanding prefetch addresses)
最关键的是,调度中心会一直盯着你的位置。如果你已经走到餐厅门口准备自己吃了(CPU发出了对 trigger address 的需求),调度中心立刻就把这张卡片撕掉,告诉外卖员:“别送了,客户等不及了!” 这样既避免了送一堆没用的菜过来污染你的餐桌(Cache Pollution),又立刻空出了人手(Free PFHR entry)去接真正有价值的下一单。
Figure 9. Memory structures used in Prodigy—(a) node table, (b) edge index table, and (c) edge table for storing the DIG representation, (d) prefetch status handling register (PFHR) file tracking progress for live prefetch sequences and issuing non-blocking prefetches. Figure 10. Prefetching algorithm initiates prefetch sequences between prefetch bounds j and k and advances a prefetch sequence using software-defined indirection types. The superscripts denote a demand (D) or a prefetch (P) access.
关键一招 作者并没有沿用传统 Cache 里 MSHR(Miss Status Handling Register)那种只为处理缺失而设计的简单思路,而是巧妙地在预取器内部专门设计了一个状态机和配套的寄存器文件,用来管理预取特有的长链条和动态性。具体来说,他们做了两个核心扭转:
-
引入了“触发地址”作为时效性锚点:
- 每个 PFHR 条目都记录下预取序列开始的那个虚拟地址(Prefetch trigger address)。
- 预取器会持续监听 CPU 的 L1D 访问。一旦发现 CPU 自己访问了这个“触发地址”,就立刻判定:“坏了,我预取得太慢了,CPU已经追上来了!”
- 于是,它会果断丢弃(drop)整个与之关联的预取序列,释放所有相关资源。这保证了预取器永远在“有效提前量”的范围内工作,而不是盲目地、过时地搬运数据。
-
实现了真正的非阻塞多路预取:
- 传统的预取器在处理一个长链条时是串行阻塞的。而 PFHR 文件允许多个预取序列并行存在、独立追踪。
- 当一个预取请求的数据返回时,预取器通过 CAM(Content-Addressable Memory)查找 Outstanding prefetch addresses 字段,瞬间定位到对应的 PFHR 条目。
- 然后,它利用存储在 DIG 中的语义信息(比如是 single-valued indirection 还是 ranged indirection),立刻计算出下一个要预取的地址,并发出新的请求,同时更新该 PFHR 条目的状态。
- 这个过程完全不阻塞其他正在执行的预取序列,极大地提升了预取器的吞吐量和对复杂遍历模式的覆盖能力。
5. 自适应预取算法¶
痛点直击
传统硬件预取器在处理图计算这类不规则负载时,常常陷入两难境地:
- 如果预取得太“激进”(lookahead distance 太大),核心还没用到数据,缓存就被新来的预取项挤出去了,造成 cache pollution,白忙活一场。
- 如果预取得太“保守”(lookahead distance 太小),核心执行速度一旦变快,就会立刻追上预取器,导致 stall on DRAM,预取完全没起到隐藏延迟的作用。
- 更麻烦的是,不同算法的内存访问模式差异巨大。比如 BFS 可能要连续穿越四五个数据结构(offset list -> edge list -> visited list -> ...),而 PageRank 的路径可能就短很多。用一个固定的预取距离去应付所有情况,注定是顾此失彼。
通俗比方
想象你在一条崎岖的山路上给前方的朋友送水。你朋友走路的速度时快时慢,而你每次只能背有限的几瓶水。
- 一个笨办法是:不管朋友走多快,你每次都固定在他前面100米的地方放一瓶水。如果他突然加速,很快就跑到你放水点的前面去了,渴得不行;如果他走得很慢,你放的水早就被太阳晒干(被缓存替换)了。
- Prodigy 的聪明做法是:你先观察这条路有多“绕”(对应 DIG 中的 遍历深度)。如果路很绕(深度大),你知道朋友走完整个流程需要很久,那你就在离他近一点的地方(比如20米)放水,保证水是新鲜的。如果路很直(深度小),你就大胆地把水放到更远的地方(比如80米),让他一路畅通无阻。
- 同时,你还一直盯着朋友的位置。一旦发现他已经走到你上次放水点附近了,你就立刻放弃那个已经没意义的送水计划,转而集中精力为他下一个位置准备新的水。这就叫 选择性丢弃预取序列。
关键一招
作者并没有采用一个僵化的预取策略,而是在预取器内部植入了一个动态反馈和调整机制,其核心逻辑转换在于:
-
将静态的“预取距离”参数,转变为由 DIG 遍历深度驱动的动态变量。
- 具体来说,系统内置了一个简单的启发式规则:遍历深度越高,预取距离越短。论文中提到,对于穿越四个或更多数据结构的算法,预取距离直接设为1。这确保了在长依赖链下,预取的数据能及时被用上,避免因等待太久而失效。
-
引入了基于“触发地址”的实时监控与清理机制。
- 每当启动一个新的预取序列时,硬件会记录下这个序列的起始虚拟地址(即 prefetch trigger address,见
Figure 9. Memory structures used in Prodigy—(a) node table, (b) edge index table, and (c) edge table for storing the DIG representation, (d) prefetch status handling register (PFHR) file tracking progress for live prefetch sequences and issuing non-blocking prefetches. Figure 10. Prefetching algorithm initiates prefetch sequences between prefetch bounds j and k and advances a prefetch sequence using software-defined indirection types. The superscripts denote a demand (D) or a prefetch (P) access.
中的 PFHR 结构)。
- 在后续执行中,如果核心发出了一个对这个“触发地址”的需求加载(demand load),就意味着核心已经赶上了这个预取序列的进度。
- 此时,系统会果断 drop the prefetch sequence,因为继续完成这个序列只能部分隐藏延迟,性价比极低。释放出的硬件资源(如 PFHR 条目)可以立即用于启动更有价值的新预取任务。
这个设计的精妙之处在于,它用极低的硬件开销(仅需在 PFHR 中增加一个地址字段和一个比较器),就实现了预取器与核心执行节奏的动态同步,从根本上解决了预取“过犹不及”的难题。