Porting a JIT Compiler to RISC-V: Challenges and Opportunities 通俗讲解¶
0. 整体创新点通俗解读¶
痛点直击 (The "Why")
- 这篇论文的核心问题,不是要造一个新的 JIT 编译器,而是要把一个为 x86 量身定做的、已经很成熟的 JIT 编译器(Cogit)移植到 RISC-V 上。这听起来简单,但实际非常“难受”,因为这两个架构的设计哲学几乎是背道而驰的。
- x86 是 CISC 的代表:它有很多“高级”指令,比如一条指令就能完成比较和条件跳转(
cmp+jz),还有丰富的寻址模式和隐式的状态寄存器(flag register)。JIT 编译器可以利用这些特性,生成非常紧凑高效的代码。 - RISC-V 是精简主义的信徒:它刻意去掉了 flag register,所有分支指令都必须显式地比较两个寄存器;它没有复杂的寻址模式;加载一个大常数可能需要好几条指令拼凑。这意味着,原来在 x86 上“理所当然”的编译逻辑,在 RISC-V 上直接就“断片”了。
- 如果强行硬搬,要么生成的代码效率极低,要么根本无法工作。所以,作者面临的挑战是:如何在不彻底重写整个编译器的前提下,弥合这种由底层 ISA 设计差异带来的巨大鸿沟?
通俗比方 (The Analogy)
- 想象你是一个习惯了用多功能瑞士军刀(x86)的厨师。你的菜谱(JIT IR)里写满了“用小刀切”、“用开瓶器开”这样的指令,因为你手里的工具能完美执行它们。
- 现在,有人让你去一个只提供最基础厨具(RISC-V)的厨房:只有菜刀、砧板和锅。这里没有开瓶器,也没有削皮刀。
- 你有两个选择:
- 重写所有菜谱:把“用开瓶器开”改成“找块布垫着,用菜刀撬”。但这工作量巨大,而且你原来的菜谱在其他厨房(ARM)还能用,全改了太亏。
- 在执行时动态翻译:当你看到菜谱上写着“用开瓶器开”时,你临时把它替换成一连串基础操作:“拿布 -> 包住瓶盖 -> 用菜刀撬”。这样,你的原始菜谱不用动,只是在执行前多了一步“智能翻译”。
- 这篇论文干的就是第二件事。他们没有推翻原有的“菜谱”(CogRTL IR),而是在“做菜”(concretization,即机器码生成)这个环节,增加了一个聪明的“现场翻译官”。
关键一招 (The "How")
-
作者的核心思路是保持中间表示(IR)不变,但在后端生成阶段进行巧妙的“指令融合”和“策略切换”。具体来说,他们做了几件关键的事:
-
解决无 Flag Register 的问题:
- 原来的 IR 是
CmpCqR(比较常数和寄存器) +JumpZero(如果为零就跳) 这样的两步走。 - 在 RISC-V 后端,编译器会向前看(look-ahead)。当它发现
CmpCqR后面紧跟着一个条件跳转时,它不会真的生成一个比较指令,而是直接融合成一条 RISC-V 的分支指令(如beq)。 - 如果是比较常数,它会先用一两条指令把常数加载到一个临时寄存器,然后再用
beq比较两个寄存器。这本质上是把 x86 的“隐式状态传递”转换成了 RISC-V 的“显式寄存器操作”。
- 原来的 IR 是
-
解决大常数加载和代码膨胀的问题:
- 直接在指令里嵌入大常数(inline literals)在 RISC-V 上代价太高,可能需要多达 8 条指令。
- 作者引入了 OutOfLineLiteralsCompiler 策略。对于超过 12 位的常数,编译器不再尝试塞进指令流,而是把这些常数统一放到代码附近的“数据池”里。
- 访问时,只需要固定的两条指令:
auipc(获取数据池的基地址) +ld(从基地址加载常数)。这极大地简化了代码生成和后续的**代码修补(code patching)**逻辑。
-
构建强大的仿真与测试环境:
- 为了高效开发,他们充分利用了 Pharo 语言本身的元循环(meta-circular) 特性。整个 VM 可以在 Pharo 环境中被完整模拟。
- 他们建立了一个 ISA-agnostic 的测试套件,可以在没有真实 RISC-V 硬件的情况下,通过 Unicorn 模拟器验证 JIT 生成的每一条指令是否正确。
- 更妙的是,这个框架还支持自定义指令的仿真。开发者可以先在 Pharo 里用高级代码模拟新指令的行为,快速验证硬件加速的想法,而无需等待真实的芯片流片。
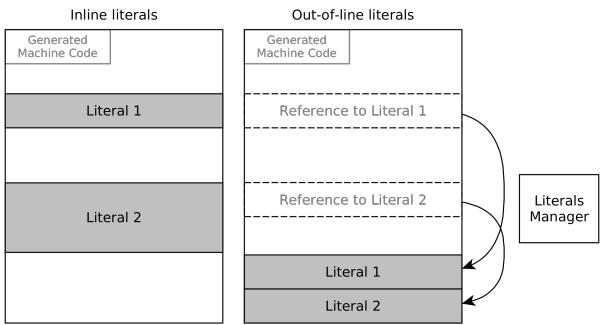 Figure 3: Inline and out-of-line literals.
Figure 3: Inline and out-of-line literals.
总而言之,这篇论文的精髓在于展示了一种务实且高效的移植策略:通过在编译器后端引入智能的指令融合、灵活的常量管理以及强大的仿真工具链,成功地将一个为复杂 ISA 设计的 JIT 编译器,“嫁接”到了一个设计哲学截然不同的精简 ISA 上,同时为未来的硬件/软件协同设计打开了大门。
1. CogRTL IR to RISC-V Concretization with Conditional Code Handling¶
痛点直击 (The "Why")
- 传统的 CogRTL IR 是围绕 x86 这类有条件码(condition codes) 的架构设计的。它的典型模式是:先发一条
Cmp指令,这条指令偷偷把结果(比如是否为零、是否溢出)记在一个叫 flag register 的地方;下一条JumpZero指令就直接去读这个 flag register 来决定跳不跳。 - 这套逻辑在 x86 上跑得飞起,因为硬件天生就这么干。但到了 RISC-V 这里就“水土不服”了。RISC-V 根本没有 flag register,它的分支指令(如
bne)要求你当场把两个寄存器拿来比较,然后立刻决定跳不跳。 - 如果强行把 CogRTL 的两步走(
Cmp+Jump)翻译成 RISC-V,你会发现根本找不到对应的单条指令,整个 IR 到机器码的 one-to-one 映射 就崩了。这就像你拿着一份菜谱(IR),上面写着“尝一下咸淡”,但你的厨房(RISC-V)里压根没有舌头(flag register),你只能把“尝”和“判断”这两步合并成一个动作。
通俗比方 (The Analogy)
- 这就好比以前你有个秘书(flag register)。你跟他说:“去查一下A和B谁大(
Cmp A, B)”,秘书默默记下结果。过一会儿你再吩咐:“如果A大,就发邮件(JumpIfAGreater)”。秘书会根据刚才的记录执行。 - 现在你被派到一个新公司,这里不配秘书(RISC-V no flags)。老板(CPU)要求你必须一次性把指令说清楚:“如果A大于B,就立刻发邮件”。你不能再分两步走了。
- 所以,聪明的做法不是抱怨没秘书,而是在下达指令前,自己先把“比较”和“行动”这两件事揉成一句话再说出去。论文里的解决方案,本质上就是让编译器扮演了这个“揉指令”的角色。
关键一招 (The "How")
- 作者并没有去重写整个历史悠久的 CogRTL IR(那会牵一发动全身,成本太高),而是巧妙地在 concretization(具体化,即 IR 到机器码的最后一步)阶段动了手脚。
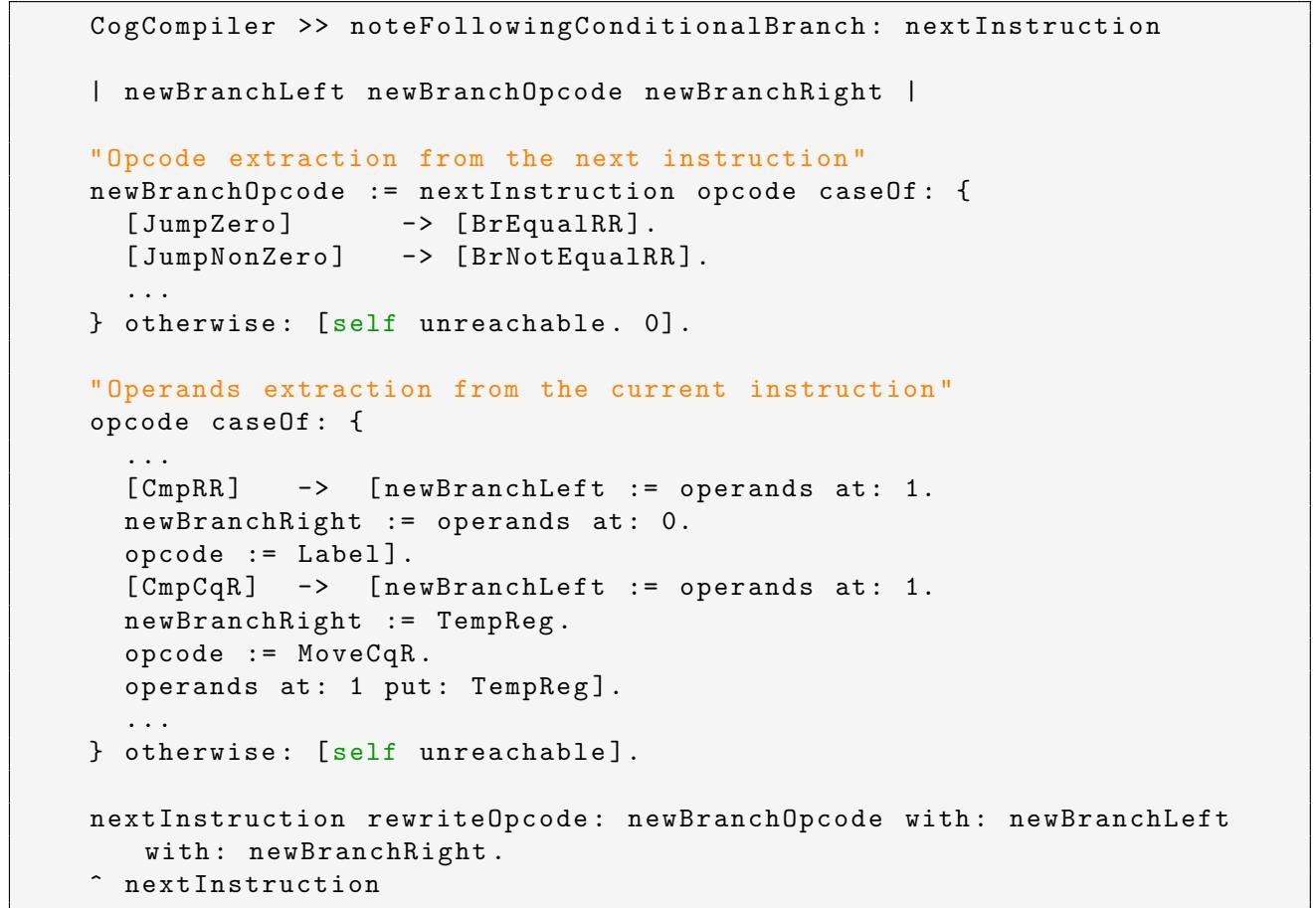
- 具体来说,当编译器在遍历 IR 指令流时,它不再是“看一条翻一条”。一旦它看到一条
Jump<Condition>指令,它会立刻回头看上一条是不是Cmp指令。 - 如果是,它就把这两条 IR 指令吃掉,然后吐出一条全新的、符合 RISC-V 风格的复合分支指令。
- 例如,
CmpRR R1, R2+JumpZero L这对 IR,在 x86 后端会变成两条指令。 - 但在 RISC-V 后端,编译器会识别出这个模式,直接生成一条
beq R1, R2, L。 - 对于涉及立即数的情况,比如
CmpCqR #42, R1,编译器会先插入一条li T0, #42把常量加载到临时寄存器,然后再生成beq T0, R1, L。
- 例如,
- 这个扭转的关键在于,将原本由硬件隐式维护的状态(flag),转变成了由编译器显式传递的操作数。通过在 concretization 阶段引入这种窥孔优化(peephole optimization)式的重写逻辑,完美地弥合了 IR 的抽象与 RISC-V 硬件现实之间的鸿沟。
2. Out-of-Line Literals Management¶
痛点直击 (The "Why")
- 在 RISC-V 这种精简指令集架构上,加载一个 64位立即数(literal) 是个“脏活累活”。不像 x86 那样一条指令搞定,RISC-V 需要组合
lui、addi、slli等指令,最坏情况下能膨胀到 8条指令。 - 这带来两个致命问题:
- 代码膨胀:原本一行逻辑,现在占了八行机器码,严重浪费宝贵的 I-Cache 空间。
- 动态更新噩梦:JIT 编译器经常需要 patch(打补丁)这些立即数(比如更新方法地址)。如果一个值占了8条指令,你不仅要预留足够空间,还得在每次更新时重新跑一遍复杂的 immediate encoding logic,效率极低且极易出错。
通俗比方 (The Analogy)
- 想象你要在一张便签纸上写一个超长的电话号码。RISC-V 的规则是:每行只能写12个数字。于是你不得不把一个号码拆成好几行,还得分清哪些是区号、哪些是分机号,写起来麻烦,改起来更麻烦。
- “Out-of-Line Literals” 的思路就聪明多了:它不再执着于把号码写在便签(代码段)里,而是拿出一张专门的 小卡片(数据段),把完整的号码写在上面。然后在便签上只写一句:“去我桌上的小卡片看号码”。这样,便签内容变得简洁统一(永远只需要两行指令),而修改号码也只需换掉那张小卡片即可。
Figure 3: Inline and out-of-line literals.
关键一招 (The "How")
- 作者没有硬着头皮去优化那个复杂的 立即数编码逻辑,而是巧妙地 改变了存储策略。
- 具体来说,他们在 JIT 编译流程中引入了一个 LiteralsManager 组件,并设定了一个简单的阈值:任何超过12位的字面量,一律不尝试内联(inline)到指令流中。
- 取而代之的是:
- 将这些大字面量统一收集起来,存放在生成的机器码附近的 专用内存区域(模拟了
.data段)。 - 在需要使用该字面量的地方,用一个 固定长度(总是两条)的指令序列 来访问它:
- 第一条是
auipc,用于获取字面量所在内存区域的 基地址。 - 第二条是
ld(或lw),从该基地址加上一个偏移量处 加载 出完整的字面量。
- 第一条是
- 将这些大字面量统一收集起来,存放在生成的机器码附近的 专用内存区域(模拟了
- 这个设计将一个 可变长度、逻辑复杂 的问题,转换成了一个 固定长度、逻辑简单 的问题。无论是生成代码还是后续的 code patching,都变得极其可靠和高效。
3. ISA-Agnostic Test Harness and VM Simulation Framework¶
痛点直击 (The "Why")
- 以前给一个新的 ISA(比如 RISC-V)移植一个 JIT compiler,最难受的地方在于:你得在真机上反复调试生成的 machine code。但 RISC-V 硬件要么没有,要么很贵、很慢,调试体验极差。
- 更要命的是,JIT 编译器和 VM 的逻辑是深度耦合的。一个错误可能源于编译器生成了错的指令,也可能源于 VM 的运行时状态不对。在硬件上 debug 这种问题,就像在黑夜里用望远镜找一根针。
- 如果每次修改都要交叉编译、部署到目标机、再跑测试,开发迭代速度会慢到让人崩溃。这本质上是一个 开发环境与目标环境严重脱节 的问题。
通俗比方 (The Analogy)
- 这套方法就像是给你的 JIT 编译器和 VM 搭建了一个 “数字孪生”沙盒。
- 想象你要设计一辆新车的引擎(JIT compiler),但不用真的造出一台车开上路去测试。你可以在一个高保真的赛车游戏(VM Simulation Framework)里,用完全相同的物理规则(Unicorn emulator)来模拟引擎的每一个细节。
- 而那个 ISA-Agnostic Test Harness,就是一套标准化的、可编程的“驾驶考试”。无论你的引擎是为 F1 赛车(x86)、越野车(ARM)还是未来的概念车(RISC-V)设计的,这套考试都能用同样的标准(1400+个测试用例)来检验它是否合格。你只需要在游戏里换一辆车的模型,就能立刻开始测试。
关键一招 (The "How")
- 作者并没有把开发流程硬塞进传统的“写代码 -> 交叉编译 -> 真机调试”的死循环里,而是巧妙地利用了 Pharo 语言本身的 meta-circular 特性(VM 用自身语言编写)。
- 核心创新点在于将整个开发和验证闭环都拉回到了高级的 Pharo 环境中:
- 第一步,构建架构无关的验证标准:他们围绕 Cogit JIT 的核心功能(从单字节码编译到复杂的 Polymorphic Inline Cache 生成),建立了一个包含 1400+ 个可配置测试的 ISA-Agnostic Test Harness。这些测试只关心“输入字节码应该产生什么样的语义行为”,完全不关心底层是 x86 还是 RISC-V 指令。
- 第二步,创建一个可交互的虚拟硬件:他们使用 Unicorn CPU 模拟器作为后端,构建了一个 VM Simulation Framework。这个框架不仅能执行生成的机器码,还能通过 hook 机制(如
UC_MEM_UNMAPPED和UC_INSN_INVALID)将控制流无缝地交还给 Pharo 环境。这意味着,当 JIT 代码需要调用 VM 的 runtime 服务(比如分配内存或触发 GC)时,模拟器能精准地捕获并重定向到 Pharo 中对应的模拟方法。 - 第三步,实现无缝的开发体验:开发者可以在 Pharo 强大的 IDE 里直接编写、修改 JIT 后端代码,然后立刻用测试套件在模拟器上运行和调试。他们甚至可以使用 Pharo 内置的 machine code debugger 来可视化地查看 IR、生成的汇编和寄存器状态,就像在调试普通的 Smalltalk 对象一样。
 Figure 2: Cogit compilation phases.
Figure 2: Cogit compilation phases.
- 这个框架的威力在于,它把对 真实硬件 的依赖,转化成了对 模拟器正确性 的依赖。而 Unicorn 作为一个成熟的、支持多架构的模拟器,其可靠性远高于自己从头搭建的硬件测试平台。这使得团队在没有 RISC-V 硬件的情况下,就完成了整个 JIT 后端的开发和验证,极大地加速了移植过程。
4. Custom Instruction Prototyping via Simulator Hooks¶
痛点直击 (The "Why")
- 传统硬件开发流程里,想验证一个 RISC-V custom instruction 的想法,得先改 RTL(寄存器传输级)代码,然后用 FPGA 综合、上板测试。这个过程动辄几小时甚至几天,迭代成本极高。
- 对于 VM 开发者来说,他们关心的是“这条新指令能否加速 GC 或 JIT 编译”,而不是底层电路细节。他们需要一个能像写普通 Pharo 代码一样快速试错的环境。
- 如果没有这种能力,VM 和硬件的协同设计就变成了空谈,因为反馈回路太长,根本没法敏捷地探索设计空间。
通俗比方 (The Analogy)
- 这就像你在玩一个沙盒游戏(比如《我的世界》),你想添加一个全新的“魔法方块”。正常情况下,你需要修改游戏引擎的源代码并重新编译整个游戏。
- 但作者的做法是:利用游戏已有的“错误处理”机制。当游戏引擎遇到一个它不认识的方块 ID 时,通常会崩溃。作者却说:“别崩溃,把这个未知方块的 ID 和参数传给我,我用一段现成的脚本(Pharo 方法)来定义它的行为。”
- 这样,你就可以在不碰游戏核心引擎的情况下,动态地、安全地为游戏注入全新的功能。这本质上是一种 "Just-in-Time Hardware" 的思想。
关键一招 (The "How")
- 作者并没有去魔改 RISC-V 模拟器(如 Spike)或自己从头造一个,而是巧妙地利用了现有通用模拟器 Unicorn 提供的一个强大钩子(hook):
UC_INSN_INVALID。 - 具体流程如下:
- 在 Pharo 的 Cogit JIT compiler 中,当需要生成一条自定义指令的机器码时,就直接输出一个在标准 RISC-V ISA 中未定义的 opcode。
- 当 Unicorn 模拟执行到这条“非法”指令时,它不会直接报错退出,而是触发
UC_INSN_INVALID事件。 - 作者预先注册了一个错误处理回调函数。这个函数会:
- 从当前的程序计数器(PC)位置读取这条非法指令的原始字节码。
- 解析出 opcode 和操作数(例如,寄存器编号、立即数等)。
- 动态查找 Pharo 环境中一个与该 opcode 同名的方法(例如,
customInstruction_0x55)。 - 调用这个 Pharo 方法,并将解析出的操作数作为参数传入,从而在高级语言层面模拟了这条硬件指令的功能。
- 执行完这个 Pharo 方法后,回调函数将 PC 指针推进到下一条指令,Unicorn 继续模拟执行。
- 这个设计最精妙的地方在于,它把硬件指令的语义定义完全交给了高级语言环境。VM 开发者只需要在熟悉的 Pharo IDE 里写一个方法,就能立刻拥有一个“虚拟”的新硬件指令,并在完整的 VM 上下文中进行端到端的测试和性能评估。 Figure 3: Inline and out-of-line literals.