OCOLOS: Online COde Layout OptimizationS 通俗讲解¶
0. 整体创新点通俗解读¶
痛点直击 (The "Why")
传统 Profile-Guided Optimization (PGO) 是个好东西,但它有个致命的“时间差”问题。想象一下:
- 你花了一周时间,在旧版本的 MySQL 上跑了一个典型的负载,收集了profile。
- 然后你用这个 profile 去优化新版本的 MySQL。
- 但在这期间,代码已经变了!新功能、新补丁让旧 profile 的很多信息变得无法映射甚至完全错误。
- 结果就是,你精心优化的二进制文件,可能因为用了过时的 profile,性能反而不如不优化,或者错失了大量优化机会。
这就像拿着去年的地图去开今年的车——路都修好了,你的地图还显示是泥巴路,导航自然不准。尤其是在数据中⼼这种代码高频迭代的环境里,这个问题尤为突出。更别提 PGO 还需要重新编译/链接整个应用,对于大型服务来说,部署成本极高。
通俗比方 (The Analogy)
OCOLOS 的思路,就像是给一辆正在高速行驶的汽车换引擎,而不是把车开回车库大修。
- 传统 PGO:相当于把车开回4S店(停机),拆掉旧引擎(旧二进制),根据上次开车的数据(旧 profile)设计一个新引擎(新二进制),再装回去。问题是,你这次开车的路况(输入)和上次完全不同,新引擎可能根本不适合。
- OCOLOS:它直接在车上装了一个“热插拔引擎舱”。它一边开着车(程序运行),一边偷偷记录当前的驾驶习惯(在线 profiling)。等新引擎(通过 BOLT 优化好的代码)造好后,它会找个安全时机(短暂暂停),把新引擎塞进引擎舱,并巧妙地把油管、电路(代码指针)都接到新引擎上,然后继续飞驰。这样,引擎永远是最适合当前路况的。
关键一招 (The "How")
OCOLOS 的核心创新在于,它没有试图去“修改”正在运行的代码,而是采用了“保留+重定向”的策略,完美解决了在线代码替换中最棘手的代码指针失效问题。
- 保留旧代码 (C0):OCOLOS 永远不会覆盖或删除原始的代码段(C0)。这保证了任何指向 C0 的指针(无论是栈上的返回地址、vtable 里的函数指针,还是程序员自己存的函数指针)都依然有效,程序不会崩溃。
- 注入新代码 (C1):它将 BOLT 优化后的新代码(C1)加载到进程地址空间的一个新位置。
- 智能重定向:OCOLOS 只修改那些可控且值得改的入口点,将执行流引导至更快的 C1 代码。具体来说:
- 它会修改 C0 中的直接调用指令,让它们跳转到 C1 中对应的函数。
- 它会更新 vtable 中的函数指针,指向 C1。
- 对于连续优化(从 C1 到 C2),它甚至能处理栈上正在执行的函数,通过复制一份兼容的代码来安全地更新返回地址。
- 规避不可控指针:对于那些散落在堆、栈、寄存器里,无法追踪的函数指针,OCOLOS 采用了一个聪明的编译期插桩:强制所有新创建的函数指针都指向原始的 C0 地址。这样,即使这些指针被到处传递,当它们被调用时,也会先进入 C0,而 C0 里的直接调用已经被重定向到 C1 了,最终还是会执行到优化后的代码。
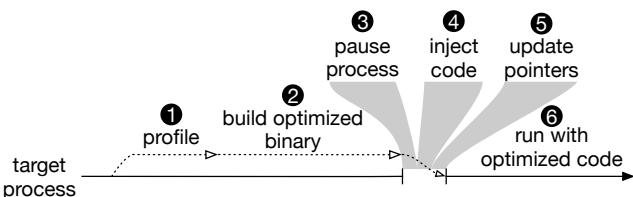
Figure 4a: Main steps OCOLOS takes to optimize a target process
通过这套组合拳,OCOLOS 实现了对未修改的、复杂的 C/C++ 应用(如 MySQL, MongoDB)进行在线、安全的代码布局优化。它把 PGO 从一个离线、静态、有滞后性的工具,变成了一个在线、动态、始终与当前负载匹配的活系统。
最终效果非常显著,论文展示了对 MySQL 最高 1.41×、对 Verilator 高达 2.20× 的加速比,而且这一切都不需要改动一行应用代码。
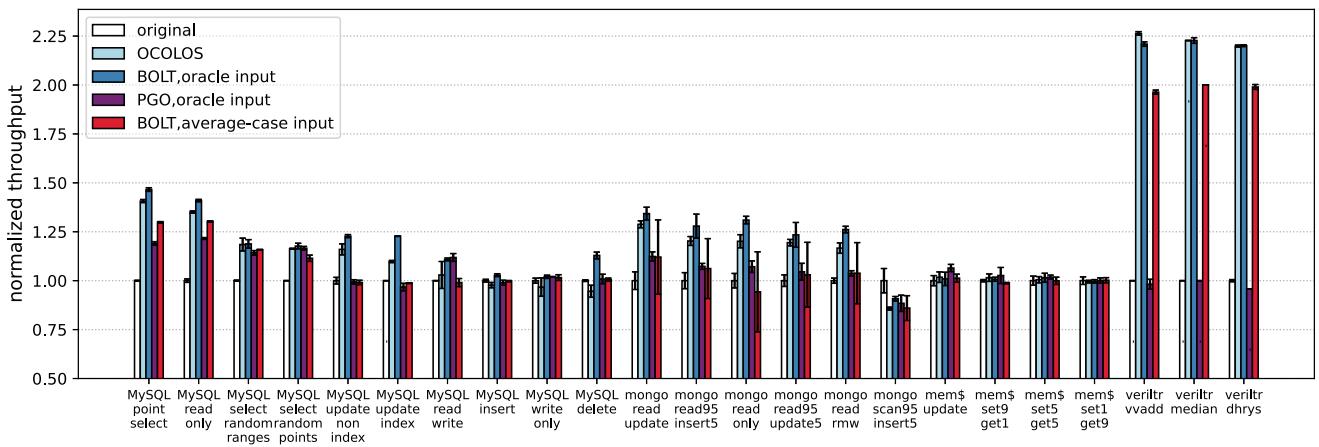
Fig. 5: Performance of OCOLOS (light blue bars) compared to BOLT using an oracle profile of the input being run (dark blue bars), Clang PGO using the same oracle profile (purple bars) and BOLT using an average-case profiling input aggregated from all inputs (pink bars). All bars are normalized to original non-PGO binaries (white bars).
1. 在线代码布局优化 (Online Code Layout Optimization)¶
痛点直击
- 传统的 Profile-Guided Optimization (PGO) 是个“马后炮”。它需要先跑一遍程序收集 profile(剖析数据),然后用这些数据去重新编译或重写二进制文件,最后再用这个新二进制文件去跑真正的任务。
- 这套流程在现代软件开发中会遇到两个致命问题:
- 输入漂移 (Input Drift):你 profiling 的时候用的是 A 场景的数据,但上线后跑的是 B 场景。用 A 的数据去优化 B 的代码,轻则没效果,重则性能更差。
- 代码漂移 (Code Drift):大型项目(比如 MySQL)可能每小时都在更新。昨天 profiling 的数据,今天代码一变,就完全对不上号了,只能丢弃,导致宝贵的优化机会白白浪费。
通俗比方
- 想象你在开车去一个陌生城市。传统的 PGO 就像是出发前,你根据一份昨天的纸质地图规划好了最优路线。但现实是,路上可能有突发的交通事故(输入变化)或者一夜之间修了新路(代码更新),你的旧地图立刻就失效了。
- OCOLOS 做的事情,相当于给你的车装了一个实时联网的高德地图。它一边开车(程序运行),一边通过 GPS(硬件性能计数器)感知当前路况(代码热点),并动态地、在线地为你重新规划一条最快的路线(重排代码布局),确保你永远走在最高效的路径上。
关键一招
- OCOLOS 的核心洞察是:与其费劲地把旧 profile “映射”到新代码上,不如直接在正在跑的进程里做优化。它的巧妙之处在于如何安全地“换引擎”而不让车熄火。
- 具体来说,它没有采用“原地修改”的危险操作,而是遵循了一个稳健的设计原则:保留原始代码 C0 的地址不变。
- 它先把优化后的新代码 C1 注入到进程的地址空间里。
- 然后,它只去精准地修改那些最容易追踪和更新的代码指针,比如:
- v-table 里的虚函数指针
- 直接调用 (direct call) 的指令目标
- 对于那些难以追踪的指针(比如被 cast 成整数、存到堆栈深处的函数指针),它选择不去碰它们。因为一旦执行流进入 C0,很快就会遇到一个被修补过的直接调用或虚函数调用,从而被“引流”回高性能的 C1 代码。
- 为了支持持续优化(比如应对程序的不同运行阶段),OCOLOS 还引入了一个精巧的机制来处理 return address 和 function pointer:
- 对于栈上的 return address,如果它指向即将被替换的旧代码 Ci,OCOLOS 会将对应的函数在新代码区域 Ci+1 中做一个精确副本 (bi,i+1),并修正 return address 指向这个副本,保证函数能正确返回。
- 对于 function pointer,它通过一个轻量级的 LLVM compiler pass,在编译时就插入一个钩子 (
wrapFuncPtrCreation)。这个钩子确保所有新创建的函数指针都指向原始代码 C0 的地址,而不是任何优化版本 Ci 的地址。这样一来,在后续的代码替换中,就完全不用操心这些指针的兼容性问题了,因为它们永远指向一个稳定的锚点。
Figure 4a: Main steps OCOLOS takes to optimize a target process
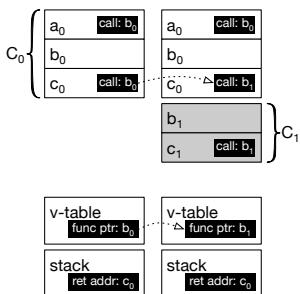
Figure 4b: Starting state of the address space (left) and state after code replacement (right)
这种设计让它既能获得接近离线 BOLT oracle 的性能收益(见下表),又完美规避了 profile 过期和代码映射的难题,而且对应用程序本身完全透明、无需修改。
| Benchmark (Input) | OCOLOS Speedup | BOLT (Oracle Input) Speedup |
|---|---|---|
| MySQL (read only) | 1.41x | ~1.48x |
| Verilator | 2.20x | ~2.25x |
| Clang Build (BAM) | 1.14x | N/A |
Fig. 5: Performance of OCOLOS (light blue bars) compared to BOLT using an oracle profile of the input being run (dark blue bars), Clang PGO using the same oracle profile (purple bars) and BOLT using an average-case profiling input aggregated from all inputs (pink bars). All bars are normalized to original non-PGO binaries (white bars).
2. 安全的在线代码替换机制 (Safe Online Code Replacement)¶
痛点直击 (The "Why")
- 传统的 Profile-Guided Optimization (PGO) 是个“事后诸葛亮”。它需要先跑一遍程序收集 profile,再用这个 profile 去重新编译或重写二进制文件。问题来了:
- 如果你的程序输入变了(比如数据库从读多变成写多),昨天的 profile 今天就可能成了“毒药”,优化反而变劣化。
- 更麻烦的是,如果你的代码本身在持续更新(比如每小时一个新版本),旧 profile 根本没法准确地映射到新代码上,大部分数据只能丢弃,非常浪费。
- 所以,理想情况是能边跑边优化,profile 永远是最新的。但这引出了一个致命问题:如何在程序运行时安全地替换掉正在执行的代码?
- 在 C/C++ 这类 unmanaged language 里,代码指针无处不在:函数指针、虚表、栈上的返回地址、甚至被 cast 成整数再算来算去的指针。你根本不可能追踪到所有指向旧代码的指针。一旦你把旧代码覆盖了,任何一个没被更新的指针跳回去,程序就直接崩溃。
通俗比方 (The Analogy)
- 想象你在高速公路上开车(程序在运行)。你想把前方一段坑洼的老路(C0)换成一条崭新的、更平顺的快速路(C1)。
- 传统做法是:封路!让所有车停下来,拆掉老路,建好新路,再放行。这对应于离线 PGO,代价巨大且不灵活。
- OCOLOS 的做法很聪明:它不拆老路,而是在旁边平行地修一条新路(C1)。然后,它只在几个最关键的高速公路入口匝道(比如虚表、直接调用点)上立新的指示牌,引导绝大多数车流(执行流)驶向新路。
- 那些没看到新指示牌、或者执意要走老路的小路(比如某些隐秘的函数指针),依然可以开,因为老路还在。虽然走老路慢一点,但至少不会翻车(程序不会崩溃)。等车流都习惯走新路后,老路就可以安全地废弃了。
Figure 4b: Starting state of the address space (left) and state after code replacement (right)
关键一招 (The "How")
- OCOLOS 的核心洞察是:与其冒着崩溃的风险去追踪和更新所有代码指针,不如保留旧代码作为安全网,并只更新那些最关键、最值得更新的指针。
- 具体来说,它做了三件事:
- 保留原始代码 (C0):这是整个方案安全性的基石。所有无法追踪的指针,即使指向 C0,也能正常工作。
- 注入优化代码 (C1):利用 BOLT 等工具生成优化后的代码,并将其加载到进程的新内存区域。
- 精准引导执行流:通过 ptrace 暂停进程,然后只修改两类关键指针:
- 虚表 (v-table) 中的函数指针:这是面向对象程序中动态分发的核心,更新它们能立刻让大量虚函数调用受益于 C1。
- C0 中的直接调用指令:将这些调用的目标地址从 C0 的函数改为 C1 的对应函数。
- 这个策略非常务实。它承认了在 unmanaged code 中完全掌控所有指针是不可能的,于是退而求其次,确保common case(通过虚表和直接调用的路径)能跑到高性能的 C1 上,而 rare case(通过其他方式调用的路径)则回退到功能正确但性能稍差的 C0 上,从而在安全性和性能之间取得了完美的平衡。
3. 函数指针创建拦截 (Function Pointer Creation Interception)¶
痛点直击 (The "Why")
在 OCOLOS 这类支持 连续优化 (Continuous Optimization) 的系统里,代码会经历 C0 → C1 → C2 ... 的多次在线替换。旧版本的代码(比如 C1)在新版本(C2)上线后会被当作“垃圾”回收掉以节省内存。但这里有个致命问题:如果程序在 C1 时代创建了一个指向 C1 中某个函数的 函数指针 (Function Pointer),并把它存到了堆、栈甚至寄存器里,那么当 C1 被回收后,这个指针就变成了一个 悬空指针 (Dangling Pointer)。一旦程序后续通过这个指针调用函数,就会直接崩溃。
- 传统的解决方案是尝试在运行时追踪所有函数指针的创建和传播,但这需要 持续的、高昂的运行时开销,违背了 OCOLOS “一次性成本”的设计哲学。
- 另一种方案是在每次代码替换时扫描整个内存去更新这些指针,这不仅 几乎不可能做到(指针可能被加密、拆分),而且 代价巨大,会严重拖慢替换过程。
所以,核心痛点是:如何在允许代码版本不断更迭、旧版本被回收的前提下,一劳永逸地解决函数指针悬空问题,且不引入任何持续的性能负担?
通俗比方 (The Analogy)
想象你在一个大型物流中心工作,货物(代码)会不断升级换代。旧仓库(C1)里的货物会被清空,腾出地方给新仓库(C2)。
- 传统做法:每当有人要记录一个货物的位置(创建函数指针),你就给他一张写有具体仓库格子号(C1地址)的纸条。等仓库清空后,所有拿着旧纸条的人都会迷路。
- OCOLOS的做法:你设立了一个永久不变的中央查询台(C0)。无论货物搬到哪个新仓库,当你给别人纸条时,上面写的都不是具体的仓库格子号,而是“请去中央查询台找XX货物”。这样,即使背后的仓库(Ci)变了又变,只要中央查询台(C0)还在,并且能正确指引到最新仓库,就不会有人迷路。
这个“中央查询台”就是原始代码 C0,它永远不会被移动或回收。
关键一招 (The "How")
作者并没有试图去追踪和更新那些已经散落在各处的函数指针,而是巧妙地在源头上做了一个“偷梁换柱”的操作。
- 在编译阶段,OCOLOS 插入了一个轻量级的 LLVM Compiler Pass。
- 这个 Pass 会找到程序中所有 创建函数指针 的地方(例如
func_ptr = &my_function;)。 - 它将这些语句重写,在其后插入一个对
wrapFuncPtrCreation回调函数的调用。 - 这个
wrapFuncPtrCreation函数内部维护了一张 映射表,记录了所有优化版本 Ci 中的函数地址到其在原始版本 C0 中对应地址的映射。 - 因此,无论
&my_function在当前时刻实际指向的是 C1、C2 还是 C99 中的地址,wrapFuncPtrCreation都会将其 拦截并重定向 到 C0 中那个永恒不变的地址。
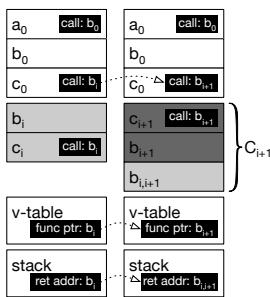
Figure 4c: Before (left) and after (right) continuous optimization
这个设计的精妙之处在于:
- 成本极低:拦截只发生在函数指针创建的瞬间,之后指针可以像普通数据一样自由传递,没有任何额外开销。论文提到 MySQL 每毫秒才创建约 45 个函数指针,开销完全可以忽略。
- 一劳永逸:由于所有函数指针最终都指向不会被回收的 C0,因此后续无论进行多少次代码替换和垃圾回收,这些指针都始终有效。
- 保持兼容性:C0 中的函数虽然未被优化,但它只是一个“跳板”,内部会立刻跳转到当前最新的优化版本 Ci+1 去执行,保证了性能。
4. 批处理加速模式 (Batch Accelerator Mode, BAM)¶
痛点直击
- 传统的 Profile-Guided Optimization (PGO) 工具(如 BOLT)是 离线 (offline) 的。它们需要先完整地跑一遍程序来收集 profile,然后用这个 profile 去优化二进制文件,最后再用这个优化后的二进制文件去运行真正的任务。
- 这个流程对于 长时运行的服务(如 MySQL)是可行的,但对于 短时进程组成的批处理任务(比如一个包含成千上万个
gcc调用的软件构建过程)就完全行不通了。因为:- 单次运行时间太短:每个
gcc进程可能只活几秒钟,根本来不及在它自己身上完成“剖析 -> 优化 -> 替换”这一整套昂贵的操作。等你优化好了,这个进程早就结束了。 - 无法受益于自身优化:即使你为某个
gcc调用生成了优化版本,它自己也用不上了,只能寄希望于后面的调用能用上。但离线 PGO 需要人为管理 profile 和优化后的二进制文件,这在复杂的构建系统中几乎是不可能的任务。
- 单次运行时间太短:每个
通俗比方
- 想象你要做一锅 100 个饺子。传统离线 PGO 就像是:你先拿一个饺子下锅煮,尝一口发现皮有点厚、馅有点少,于是你记下笔记。然后你把锅洗了,根据笔记重新和面、调馅,再包一个新的饺子。这个新饺子确实更好吃了,但你之前煮的那个已经浪费了。
- BAM 的做法则聪明得多:它就像一个 智能的厨房助手。他看到你开始包饺子(启动构建),就默默地观察你前几个饺子的做法(剖析早期的
gcc调用)。在他观察的同时,你还在继续包着普通的饺子。等他看明白了(profile 收集够了),他就立刻在旁边 快速准备好一批改良版的饺子皮和馅料(生成 BOLT 优化后的二进制文件)。从下一个饺子开始,你就自动用上了这些更好的材料,后面所有的饺子都变得更好吃,而整个过程对你(构建脚本)来说是完全透明的,你甚至不知道助手的存在。
关键一招
- BAM 的核心洞察是:在一个批处理任务中,同一个二进制文件会被反复执行多次。因此,不需要对每个进程都做在线优化,而是可以 “前人栽树,后人乘凉”。
- 为了实现这一点,作者巧妙地利用了 Linux 的 LD_PRELOAD 机制,并做了一个关键的逻辑扭转:
- 拦截点扭转:作者没有尝试去替换一个正在运行的短进程的代码(这几乎不可能),而是将优化的切入点放在了 进程创建之前。BAM 通过 LD_PRELOAD 注入一个共享库,这个库会 透明地拦截所有
exec*系统调用。 - 动态重定向:当 BAM 发现
exec调用的目标是它要优化的那个二进制文件(比如clang)时,它会分两步走:- 前期:让
exec正常执行,但同时 悄悄开启硬件性能剖析(通过perf),收集这个运行实例的 profile。 - 后期:一旦后台的 BOLT 工具利用收集到的 profile 生成了优化版的二进制文件,BAM 就会 动态修改后续的
exec调用,让它直接去执行那个 优化后的二进制文件,而不是原始的。
- 前期:让
- 拦截点扭转:作者没有尝试去替换一个正在运行的短进程的代码(这几乎不可能),而是将优化的切入点放在了 进程创建之前。BAM 通过 LD_PRELOAD 注入一个共享库,这个库会 透明地拦截所有
- 这个设计极其精妙,因为它:
- 完全透明:构建系统(如
make)对此毫无感知,不需要任何代码或脚本修改。 - 零切换开销:从原始二进制切换到优化二进制,只是
exec了一个不同的文件,没有运行时的“停顿世界”(stop-the-world)阶段。 - 自动适应:它剖析的就是当前构建任务的真实 workload,生成的优化是高度相关的,避免了离线 PGO 中 profile 过时或不匹配的问题。
- 完全透明:构建系统(如
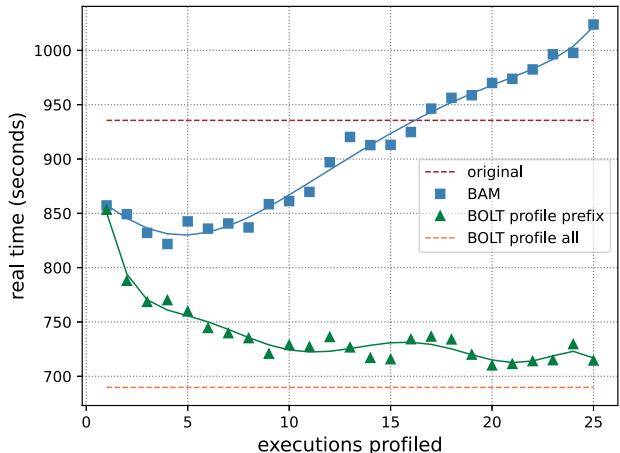
Fig. 10: The running time of a Clang build with the original compiler, and compilers optimized by BOLT and BAM.
如图所示,在 Clang 构建实验中,BAM 仅需剖析 少量(约5个)早期的编译器调用,就能生成一个足够好的优化版本,从而将整个构建时间加速 1.14倍。这证明了其“观察少数,惠及多数”的策略非常高效。