Integrating Prefetcher Selection with Dynamic Request Allocation Improves Prefetching Efficiency 通俗讲解¶
0. 整体创新点通俗解读¶
痛点直击 (The "Why")
传统硬件预取(Hardware Prefetching)的困境在于“大锅饭”式的管理。现代处理器通常会集成多个专用的预取器(Prefetcher),比如 Stream Prefetcher 处理连续访问,Stride Prefetcher 处理固定步长,Temporal Prefetcher 处理时间局部性。理想很丰满,但现实很骨感:
- 训练数据污染:所有预取器都用同一份来自CPU的 demand request(需求请求)来“学习”。一个本该由 Spatial Prefetcher 处理的复杂空间模式,也会被错误地喂给 Stride Prefetcher。这不仅浪费了 Stride Prefetcher 宝贵的 prefetcher table 条目(存储元数据的地方),还可能让它学出错误的规律。
- 资源内耗冲突:这些被错误训练出来的预取器,会生成大量无效或重复的预取请求,争抢 prefetch queue、cache space 和 DRAM bandwidth。结果就是,大家互相拖后腿,整体性能不升反降。
- 粗粒度调度:之前的调度方案(如DOL, IPCP, Bandit)要么是 静态优先级(永远让A先上),要么是在 输出端 做文章(等所有预取器都算完了,再选一个最好的)。它们都没能从源头——也就是 输入的demand request ——进行精准分配。
简单说,以前的做法就像让一群各有所长的专家(预取器)围在一张桌子旁,不管问题是什么,都把所有原始数据扔给他们看。结果专家们要么被无关信息干扰,要么互相抢着回答同一个问题,效率极低。
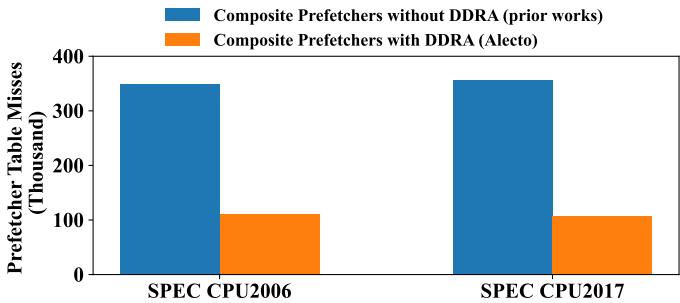
Fig. 1. Comparison of prefetcher table misses in the same composite prefetchers without dynamic demand request allocation (DDRA) and Alecto that utilizes DDRA. With efficient demand request allocation, Alecto proves to significantly reduce conflicts that occur within the prefetchers’ table.
通俗比方 (The Analogy)
想象一个高效的客服中心。客户(demand request)打电话进来,描述他们的问题。
- 旧方法(如IPCP/Bandit):所有客服专员(预取器)都能听到客户的全部描述。然后,每个专员都根据自己的理解给出解决方案。最后,由一个主管(调度器)从一堆方案里挑一个他认为最好的。这不仅浪费了其他专员的时间,而且如果专员A擅长处理账单问题,却总被要求听技术故障的描述,他的知识库(table)很快就会被垃圾信息填满。
- Alecto的新方法:在客户电话接入的瞬间,就有一个智能分诊员(Allocation Table)根据客户的来电号码(PC, Program Counter)快速判断问题类型。然后,他只把电话转接给最合适的一到两位专员。其他专员根本听不到这个电话,他们的精力和知识库得以专注在自己擅长的领域。同时,分诊员还会根据专员过去解决同类问题的成功率(accuracy),动态调整给他们分配的客户量(prefetching degree)。
这个分诊机制,就是论文提出的 Dynamic Demand Request Allocation (DDRA) —— 动态需求请求分配。
关键一招 (The "How")
Alecto 的核心创新在于,它把 预取器选择 这个动作,从传统的“输出端过滤”扭转到了“输入端分配”。具体来说,作者在标准的预取流程中,巧妙地插入了一个基于 PC 的实时决策中心。
- 作者并没有试图去改造每个预取器本身,而是在所有预取器的上游,增加了一个轻量级的 Allocation Table。
- 这个表以 PC 为索引,为每个内存访问指令记录其关联的各个预取器的 状态(State Machine):
- Un-Identified (UI): 初始状态,还不知道谁行。
- Identified and Aggressive (IA): 这个预取器被证明对这个PC很有效,可以多给点活干。
- Identified and Blocked (IB): 这个预取器对这个PC完全没用,暂时别让它接触相关数据。
- 当一个新的 demand request 到达时,Alecto 先查 Allocation Table。它只会生成一个 identifier,将这个请求动态路由给处于 UI 或 IA 状态的预取器。处于 IB 状态的预取器对此请求完全“不可见”,从根本上杜绝了训练污染。
- 这个状态机的转换依据,来自于一个精巧的反馈回路:通过 Sandbox Table 和 Sample Table 收集每个预取器针对每个PC的 实际命中率(accuracy),并以此作为奖惩信号,不断优化分配策略。
通过这一招,Alecto 同时解决了两大痛点:既保证了每个预取器能得到最干净、最相关的训练数据,又大幅减少了因无效预取导致的硬件资源冲突。最终实现了 更高性能(IPC提升)、更低能耗(减少48%的table访问)和 极小的存储开销(\<1KB)。
1. 动态需求请求分配 (Dynamic Demand Request Allocation, DDRA)¶
痛点直击 (The "Why")
- 以前的硬件预取系统就像一个大杂烩,所有类型的 Prefetcher(比如 Stream、Stride、Spatial)都盯着同一锅“需求请求”(Demand Requests)来学习。
- 这导致两个非常难受的问题:
- 训练污染:一个本该处理规则步长(Stride)模式的预取器,却被一堆不规则的空间访问模式“喂”了数据,结果它自己的 prefetcher table 里塞满了无用信息,把真正有用的条目给挤出去了。这直接导致 prefetcher table miss rate 飙升,如
Fig. 1. Comparison of prefetcher table misses in the same composite prefetchers without dynamic demand request allocation (DDRA) and Alecto that utilizes DDRA. With efficient demand request allocation, Alecto proves to significantly reduce conflicts that occur within the prefetchers’ table.
所示。
- 顾此失彼:现有的协调方案,要么像 DOL 那样用静态优先级硬性规定谁先谁后(见
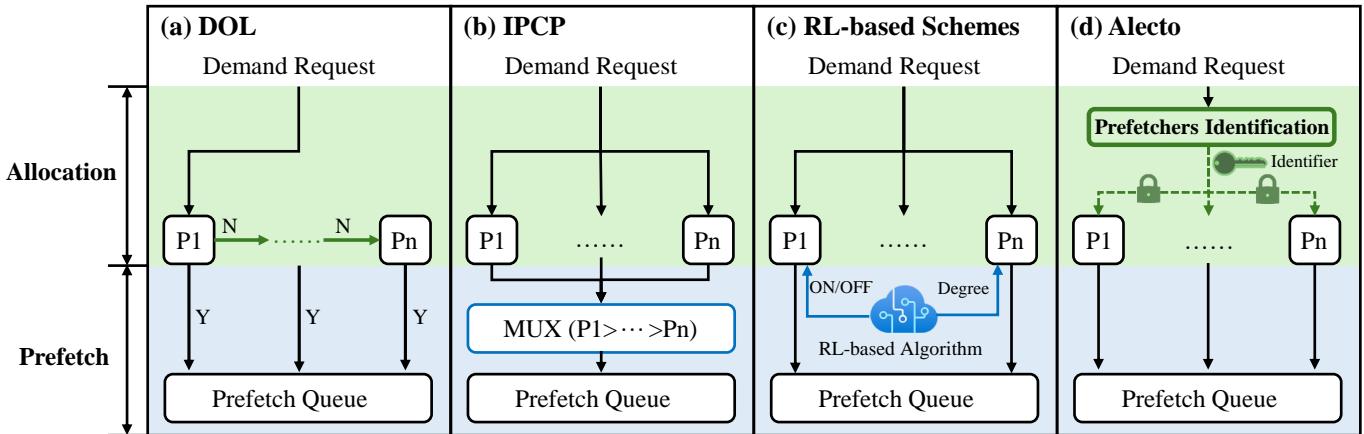
Fig. 3. Comparison of prefetcher selection algorithms. (a) DOL selects prefetchers in the allocation stage. It sequentially passes the demand request through all prefetchers. (b) IPCP selects prefetchers in the prefetch stage. It statically prioritizes the prefetching requests from different prefetchers. (c) RL-based schemes select prefetchers in the prefetch stage. It controls the outputs of prefetchers and applies identical rules for all memory accesses. (d) Alecto selects prefetchers in the allocation stage. It identifies suitable prefetchers for each memory access, then dynamically allocates demand requests to identified prefetchers.
(a)),要么像 Bandit 那样只在最后关头控制输出(见
Fig. 3. Comparison of prefetcher selection algorithms. (a) DOL selects prefetchers in the allocation stage. It sequentially passes the demand request through all prefetchers. (b) IPCP selects prefetchers in the prefetch stage. It statically prioritizes the prefetching requests from different prefetchers. (c) RL-based schemes select prefetchers in the prefetch stage. It controls the outputs of prefetchers and applies identical rules for all memory accesses. (d) Alecto selects prefetchers in the allocation stage. It identifies suitable prefetchers for each memory access, then dynamically allocates demand requests to identified prefetchers.
(c))。它们都没能解决“错误的输入导致错误的内部状态”这个根本问题。
通俗比方 (The Analogy)
- 想象一个由三位专家(Stream、Stride、Spatial Prefetcher)组成的顾问团,他们的任务是预测老板(CPU)下一步要问什么问题。
- 旧方法是,老板每次提问(Demand Request),秘书就把这个问题同时发给三位专家,并且要求他们都必须记在自己的笔记本(prefetcher table)上,然后各自给出预测。
- 结果就是,擅长回答“连续数字”的专家,笔记本里记满了“地图坐标”;擅长回答“地图坐标”的专家,笔记本里又全是“斐波那契数列”。大家的笔记本都乱成一锅粥,效率极低。
- DDRA 的做法完全不同:它在秘书和专家之间加了一个智能分诊员(Alecto)。这个分诊员会先看一眼老板的问题,然后精准地判断:“这个问题应该交给空间专家处理”,于是就只把这个问题发给空间专家,其他两位专家的笔记本完全不受干扰。这样,每位专家都能在自己最擅长的领域里,用最干净的数据进行训练。
关键一招 (The "How")
- 作者并没有去重新发明每个预取器,而是巧妙地在训练数据流入预取器之前,插入了一个动态的“分配关卡”。
- 这个关卡的核心是一个 Allocation Table(见
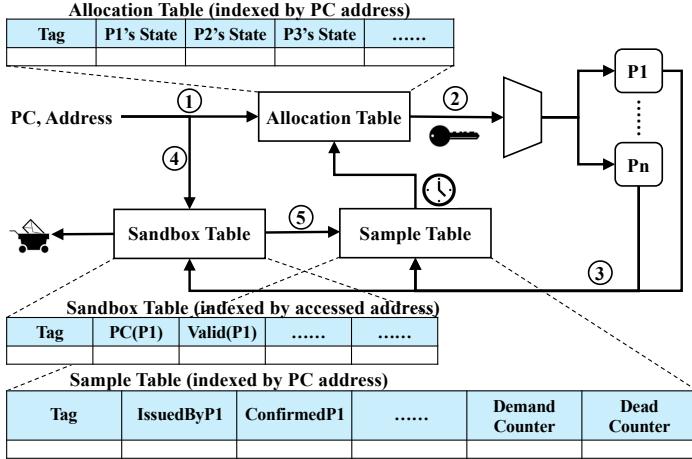
Fig. 4. The overall framework of Alecto. It consists of an Allocation Table, which enables fine-grained prefetcher identification and dynamic request allocation. It also includes a Sample Table and Sandbox Table for information collection. Additionally, the Sandbox Table functions as a prefetch filter.
),它以程序计数器(PC)为索引,为每个内存访问指令记录其关联的各个预取器的“状态”。
- 这个“状态”机(见
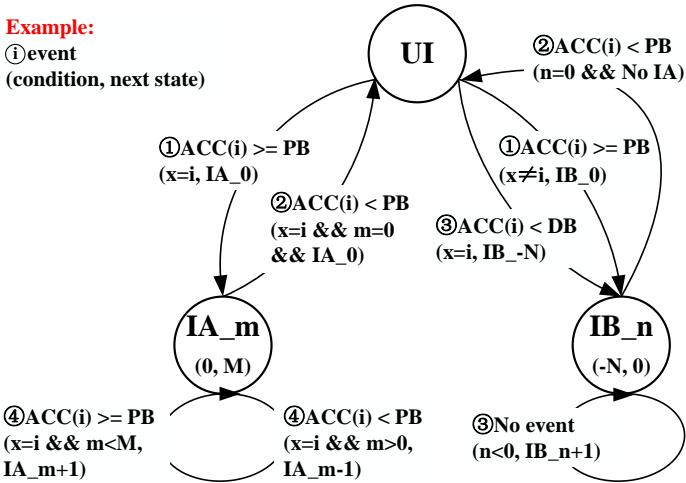
Fig. 5. The state machine of Allocation Table. For every memory access instruction, each prefetcher has three states: Un-Identified (UI) indicates the suitability of this prefetcher is unidentified; Identified and Aggressive (IA) means the prefetcher is efficient and its prefetching degree should be promoted; Identified and Blocked (IB) applies when a prefetcher is deemed unsuitable for processing the memory access instructions.
)只有三个核心状态:
- Un-Identified (UI): 还不知道谁行,先让大家都试试,但限制力度。
- Identified and Aggressive (IA): 这个预取器被证明很准,不仅把活全给它,还让它更激进地预取。
- Identified and Blocked (IB): 这个预取器被证明不行,直接切断它的数据源,让它“冷静”一段时间。
- 通过 Sample Table 和 Sandbox Table 在运行时不断收集每个预取器在每个 PC 上的准确率反馈,这个 Allocation Table 能够动态地更新状态,从而实现对每个需求请求的精准路由。这从根本上解决了训练污染和资源冲突的问题。
2. 细粒度预取器识别 (Fine-grained Prefetcher Identification)¶
痛点直击 (The "Why")
- 传统的预取器选择策略(如 DOL, IPCP, Bandit)都是“一刀切”的。它们要么给所有内存访问指令(PC)用同一个静态优先级,要么只在全局层面动态调整预取器的开关或激进度。
- 这导致了一个非常难受的局面:一个 PC 可能产生的是 stream pattern,而另一个 PC 产生的是 spatial pattern,但选择器却用同一套规则去处理它们。结果就是,适合处理 stream 的预取器被错误地用来处理 spatial 访问,不仅自己学不会(浪费了宝贵的预取器表项),还可能发出错误的预取请求,污染缓存。
- 更糟糕的是,即使某个预取器对某个 PC 完全不适用,现有的方案也无法阻止这个 PC 的需求请求(demand request)去“污染”该预取器的内部状态表,导致有用的表项被替换掉,这就是论文中提到的 prefetcher table conflict。
Fig. 1. Comparison of prefetcher table misses in the same composite prefetchers without dynamic demand request allocation (DDRA) and Alecto that utilizes DDRA. With efficient demand request allocation, Alecto proves to significantly reduce conflicts that occur within the prefetchers’ table.
通俗比方 (The Analogy)
- 想象你是一个工厂的调度经理,手下有三位专家:张师傅(擅长处理流水线任务)、李博士(擅长处理步长规律任务)和王工(擅长处理空间局部性任务)。
- 以前的做法是:
- DOL:来了一个新任务,先给张师傅看,他搞不定再给李博士,最后才轮到王工。但如果这个任务其实最适合王工,那前面两位专家已经白忙活了,还占用了他们的工作台。
- IPCP/Bandit:任务同时发给三个人,让他们各自出方案,最后你按固定优先级(张>李>王)或者根据工厂总产量(IPC)来决定采纳谁的方案。但问题是,每个专家的工作台上都堆满了所有任务的草稿,真正属于他们专长的任务反而没地方放了。
- Alecto 的做法就像是给每位专家配了一个智能助理。这个助理认识工厂里的每一个任务单(对应每个 PC),并且记录了历史数据:对于任务单 #123,张师傅的成功率是90%,李博士是10%。那么下次任务单 #123 再来时,助理会直接把它交给张师傅,并且告诉李博士和王工:“这个活你们别碰,专心干自己的”。这就实现了 为每个任务单(PC)定制专属的专家分配方案。
关键一招 (The "How")
- 作者并没有去修改预取器本身,而是在需求请求(demand request)到达预取器之前,巧妙地插入了一个 Allocation Table(分配表)。
- 这个分配表的核心创新在于其索引和内容:
- 索引:以 PC(程序计数器) 为键。这意味着它为程序中的每一个内存访问指令都维护了一套独立的决策逻辑。
- 内容:为该 PC 记录每一个预取器的当前 状态(State),即 UI (Un-Identified)、IA (Identified and Aggressive) 或 IB (Identified and Blocked)。
- 这个状态机是如何工作的?
- 当一个新的 PC 出现时,所有预取器初始状态都是 UI,意味着“还不知道谁行谁不行”,所以大家都可以试试,但要保守(低激进度)。
- 系统通过 Sample Table 和 Sandbox Table 收集该 PC 下各个预取器的历史 准确率(accuracy)。
- 如果某个预取器的准确率超过了 Proficiency Boundary (PB),它的状态就升级为 IA,以后这个 PC 的请求就主要交给它,并且可以更激进地预取。
- 如果准确率低于 Deficiency Boundary (DB),状态就降为 IB,系统会暂时“屏蔽”这个预取器,不让它再看到这个 PC 的请求,从而保护其内部表项不被污染。
- 通过这种 Per-PC、Per-Prefetcher 的精细化管理,Alecto 在源头上就完成了最合适的匹配,从根本上解决了资源冲突和训练污染的问题。
Fig. 5. The state machine of Allocation Table. For every memory access instruction, each prefetcher has three states: Un-Identified (UI) indicates the suitability of this prefetcher is unidentified; Identified and Aggressive (IA) means the prefetcher is efficient and its prefetching degree should be promoted; Identified and Blocked (IB) applies when a prefetcher is deemed unsuitable for processing the memory access instructions.
Fig. 5. The state machine of Allocation Table. For every memory access instruction, each prefetcher has three states: Un-Identified (UI) indicates the suitability of this prefetcher is unidentified; Identified and Aggressive (IA) means the prefetcher is efficient and its prefetching degree should be promoted; Identified and Blocked (IB) applies when a prefetcher is deemed unsuitable for processing the memory access instructions.
3. 三态状态机与自适应 aggressiveness¶
痛点直击
- 传统的预取器协同方案(比如 Bandit、IPCP)就像一个“一刀切”的经理。它要么给所有预取器开绿灯,让它们都去处理同一个内存访问请求(PC),要么用一个全局的开关来控制整体激进程度。
- 这种做法在混合工作负载下非常难受:
- 资源浪费:一个只擅长处理stream模式的预取器,被迫去学习一个spatial模式的 PC,不仅学不会,还会污染自己的内部表项(prefetcher table),把有用的条目挤出去。
- 顾此失彼:为了追求高覆盖率而让所有预取器都激进工作,会产生大量无效预取(over-prefetching),浪费带宽和缓存空间;反之,如果整体保守,又会错过很多可以提前加载的机会,导致覆盖率不足。
- 缺乏个性化:每个 PC 的访问模式是独特的,但旧方法对所有 PC 使用同一套规则,无法做到“因材施教”。
通俗比方
- 想象你是一个学校的校长(Alecto),手下有几位各有所长的老师(预取器):一位是数学专家(Stream Prefetcher),一位是语文大师(Stride Prefetcher),还有一位是艺术天才(Spatial/Temporal Prefetcher)。
- 以前的做法(如 IPCP)是,无论来一个什么样的学生(PC),都把他同时交给三位老师去教。结果是,数学老师在学生的作文本上乱画公式,语文老师在画板上写古诗,不仅没教会学生,还把自己的教案搞得一团糟。
- Alecto 的做法完全不同。它为每一位学生-老师组合建立了一个个人成长档案(Allocation Table)。这个档案只有三个状态:
- 未识别 (UI): “还不知道这位老师能不能教好这个学生,先让他试试看,但别太用力。”
- 已识别且激进 (IA): “实验证明这位老师教这个学生效果很好!给他更多课时(更高的 aggressiveness),让他多布置点作业(预取更多行)。”
- 已识别且阻塞 (IB): “这位老师完全不适合这个学生,让他休息一段时间,别来添乱了。”
- 校长会根据每次考试成绩(准确率)来动态更新这个档案。考得好(> PB),就升到 IA 并增加课时;考得太差(< DB),就打入 IB 冷宫一阵子。
Fig. 5. The state machine of Allocation Table. For every memory access instruction, each prefetcher has three states: Un-Identified (UI) indicates the suitability of this prefetcher is unidentified; Identified and Aggressive (IA) means the prefetcher is efficient and its prefetching degree should be promoted; Identified and Blocked (IB) applies when a prefetcher is deemed unsuitable for processing the memory access instructions.
关键一招
- 作者并没有设计一个复杂的中央控制器,而是巧妙地将预取器选择和需求请求分配这两个问题,融合到一个基于 PC 索引的三态状态机中。
- 具体来说,他们在原有的预取流程里插入了一个核心逻辑单元——Allocation Table。这个表的每一项对应一个 PC,并为每个预取器维护一个状态(UI/IA/IB)。
- 最关键的扭转在于:状态的转换和 aggressiveness 的调整,完全由该 PC 上各个预取器的历史准确率驱动,并通过两个阈值 Proficiency Boundary (PB) 和 Deficiency Boundary (DB) 来实现自适应。
- 当一个预取器在一个新 PC 上表现尚可(准确率 > PB),它就被提升到 IA 状态,并获得一个基础的 aggressiveness (
c)。随着它持续表现优异,其 IA 状态的子状态 (m) 会递增,aggressiveness 也随之线性增长 (c + m + 1),从而在保证准确率的同时,逐步提升覆盖度和及时性。 - 如果一个预取器表现极差(准确率 < DB),它会被直接打入 IB 状态,并被禁止接收该 PC 的任何训练请求长达 N 个周期,彻底避免了资源浪费。
- 对于处于 UI 状态的预取器,则给予一个保守的、最低限度的训练机会,用于探索其潜力。
- 当一个预取器在一个新 PC 上表现尚可(准确率 > PB),它就被提升到 IA 状态,并获得一个基础的 aggressiveness (
- 这个设计的精妙之处在于,它用极其简单的状态机逻辑(只有三种状态和几个阈值),就实现了对每个 PC-预取器对的精细化、动态化管理,从根本上解决了资源冲突和训练污染的问题。
4. 运行时指标收集机制 (Sample Table & Sandbox Table)¶
痛点直击
- 传统的 prefetcher selection 机制(比如 Bandit)最大的问题在于,它们是“黑盒式”决策。它们能看到最终结果(比如 IPC 奖励),但看不到每个 prefetcher 在处理每一个具体的内存访问指令 (PC) 时,到底表现如何。
- 这导致了一个致命缺陷:无法进行 fine-grained 的反馈。一个 prefetcher 可能对 PC A 预测得极准,但对 PC B 却在疯狂制造垃圾请求。如果只看全局奖励,这个 prefetcher 可能会被整体关闭或调低,从而错失了它在 PC A 上的巨大价值。
- 更糟糕的是,没有精确的 per-PC、per-prefetcher 的性能数据,就无法知道一个 demand request 到底该给谁训练。这直接导致了论文中提到的两个核心问题:prefetcher table 被污染 和 selection criteria 过于 coarse-grained。
通俗比方
- 想象你是一个教练,手下有三个专项运动员:短跑(Stream)、跳远(Stride)和体操(Spatial)。你的目标是为每一场具体比赛(对应一个 PC)派出最合适的选手。
- 以前的做法(如 Bandit)就像是只看整个团队的总积分榜来决定下个月给谁发奖金。如果总分高,就认为大家都干得好;总分低,就一起扣钱。但你根本不知道是谁在哪个项目上拖了后腿,或者谁在哪个项目上其实有巨大潜力。
- Alecto 的 Sample Table & Sandbox Table 机制,相当于给每个运动员配了一个智能手环。这个手环能精确记录:
- Sandbox Table 就像比赛现场的高清录像机,记下每个运动员(prefetcher)在每次尝试(发出 prefetch request)时的具体动作(地址)和对应的项目(PC)。
- Sample Table 就像赛后数据分析员,他拿着录像(Sandbox Table)和比赛结果(demand request)进行比对。每当一个正式选手(demand request)出场,他就去录像里查:“嘿,之前是不是有我们队的运动员预测过这个位置?如果有,是哪个项目的运动员预测的?”
- 通过这种一对一的精准回溯,教练(Allocation Table)就能为每个比赛项目(PC)建立一份详细的选手能力档案,知道谁是专家,谁是门外汉。
关键一招
作者并没有依赖模糊的全局性能指标,而是巧妙地在系统中插入了一个 “请求-验证”闭环,其核心逻辑转换在于:
- 将“预取命中”的归属权精确到源头。当一个 demand request 到达时,系统不再简单地认为“缓存命中了就好”,而是要追问:“这个命中的数据块,究竟是哪个 prefetcher、为了响应哪个 PC 的历史访问而提前拿进来的?”
- Sandbox Table 是实现这一转换的关键。它作为一个临时的、带 PC 标签 的 prefetch 请求日志(
Fig. 4. The overall framework of Alecto. It consists of an Allocation Table, which enables fine-grained prefetcher identification and dynamic request allocation. It also includes a Sample Table and Sandbox Table for information collection. Additionally, the Sandbox Table functions as a prefetch filter.
),记录了近期所有 prefetcher 发出的请求及其触发的 PC。
- 当 demand request 到达并发生缓存命中时,系统会查询 Sandbox Table:
- 如果地址匹配(tag hit),就进一步检查 demand request 的 PC 是否与日志中记录的 PC 一致。
- 如果两者都匹配,就确认这是一次 “有用的预取”,并在 Sample Table 中对应 PC 和对应 prefetcher 的 “Confirmed” 计数器 上加一。
- 同时,每次 prefetcher 发出请求时,其 “Issued” 计数器 也会增加。
- 通过这两个计数器,系统可以随时计算出针对每一个 PC,每一个 prefetcher 的 准确率 (Accuracy = Confirmed / Issued)。
- 正是这个 per-PC, per-prefetcher 的准确率,成为了驱动 Allocation Table 状态机(UI/IA/IB)进行精细决策的唯一依据,从而实现了动态且精准的 demand request allocation。
5. 集成式预取请求过滤 (Integrated Prefetch Filtering)¶
痛点直击 (The "Why")
- 传统的复合预取器(hybrid prefetcher)架构里,多个预取器(比如 stream、stride、spatial)会并行工作。这看似能覆盖更多内存访问模式,但带来一个“甜蜜的烦恼”:同一个数据块,可能被好几个预取器同时预测到,并发出重复的预取请求。
- 这些重复请求不仅浪费了宝贵的 DRAM 带宽 和 prefetch queue 空间,还会挤占真正有用的预取请求,导致整体 prefetching accuracy 下降。更糟的是,它们还会污染 cache,把有用的数据挤出去。
- 之前的解决方案,比如 Bandit,主要在“输出端”做文章,通过 RL 动态开关预取器或调整其 aggressiveness(激进程度),但这是“事后诸葛亮”。它无法阻止这些预取器在内部已经产生了冗余请求,白白消耗了硬件资源。
通俗比方 (The Analogy)
- 想象一个大型图书馆(CPU Cache),有几位图书管理员(prefetchers),各自负责不同区域的书籍(内存访问模式)。当读者(CPU core)需要一本书时,所有管理员都会根据自己的经验去仓库(DRAM)找书。
- 结果,同一本畅销书(hot data block)可能被三位管理员同时找到,并各自抱了一本回来。图书馆门口的收发室(prefetch queue)瞬间堆满了三本一模一样的书,而其他真正需要的冷门书却因为通道被堵而迟迟送不进来。
- Alecto 的做法是,在收发室后面加了一个智能分拣台(Sandbox Table as Prefetch Filter)。所有管理员抱回来的书都先放到这里,分拣员快速扫一眼,如果发现是重复的,就只留下一本,其余的直接退回仓库,绝不让它们进入图书馆内部造成混乱。
关键一招 (The "How")
- 作者并没有引入一个全新的、独立的过滤模块,而是巧妙地复用并扩展了已有的 Sandbox Table 的功能。这个表原本是用来收集运行时反馈(runtime metrics)以评估预取器准确率的。
- 具体来说,Sandbox Table 会记录最近所有已发出的预取请求的地址。当任何一个预取器产生一个新的预取请求时,Alecto 会先用这个请求的地址去查询 Sandbox Table。
- 如果发生 tag hit(命中),说明这个请求已经被其他预取器发出过了,当前这个就是duplicate prefetch request,直接丢弃。
- 如果没有命中,这个请求才是“新鲜”的,才会被允许进入 prefetch queue 并最终执行。
- 这个设计的精妙之处在于,它实现了 零额外存储开销 的过滤,因为 Sandbox Table 本来就需要存在。如论文图4所示,这个过滤步骤被无缝集成到了 Alecto 的主流程中(step ⑥)。
Fig. 4. The overall framework of Alecto. It consists of an Allocation Table, which enables fine-grained prefetcher identification and dynamic request allocation. It also includes a Sample Table and Sandbox Table for information collection. Additionally, the Sandbox Table functions as a prefetch filter.
这种集成式的设计,确保了即使多个预取器都被激活(例如都处于 IA 状态),系统也能在最后关头消除冗余,从而在提升 coverage 的同时,依然能维持很高的 accuracy,完美解决了复合预取器架构的根本矛盾。