Flexible Reference-Counting-Based Hardware Acceleration for Garbage Collection 论文解析¶
0. 论文基本信息¶
作者 (Authors): José A. Joao, Onur Mutlu, Yale N. Patt
发表期刊/会议 (Journal/Conference): ISCA
发表年份 (Publication Year): 2009
研究机构 (Affiliations): ECE Department, The University of Texas at Austin, Computer Architecture Laboratory, Carnegie Mellon University
1. 摘要¶
目的
- 解决现代托管语言(如 Java)中垃圾回收(GC)带来的显著性能开销和暂停时间问题,尤其是在内存受限或对性能要求高的场景下。
- 提出一种软硬件协同的方案,在不牺牲现有软件垃圾回收器灵活性的前提下,通过硬件加速来降低 GC 的频率和总开销。
方法
- 提出 HAMM (Hardware-Assisted Automatic Memory Management) 机制,其核心是基于硬件实现的引用计数(Reference Counting)来辅助软件 GC。
- 关键硬件组件:
- 引用计数合并缓冲区 (RCCB): 在 L1 和 L2 缓存层级设置 RCCB,用于合并对同一对象的多次引用计数更新,从而大幅减少内存流量(平均过滤掉 96.3% 的更新)。
- 可用块表 (ABT): 维护一个分层的空闲内存块列表(L1 ABT, L2 ABT, 内存 ABT),以便在对象被硬件判定为死亡后,能快速将其内存块提供给分配器重用。
- 关键软件/ISA 扩展:
- 引入新的 ISA 指令,如
REALLOCMEM(查询可重用块)、ALLOCMEM(通知硬件新分配) 和FLUSHRC(在软件 GC 前刷新挂起的引用计数更新)。 - 编译器需使用特殊的“存储指针”指令来触发硬件自动的引用计数增减操作。
- 引入新的 ISA 指令,如
- 工作流程: 硬件通过 RCCB 高效地跟踪对象引用,并在引用计数归零时,将对象内存块加入 ABT。内存分配器优先从 ABT 中获取内存,从而延迟甚至避免触发完整的软件 GC。
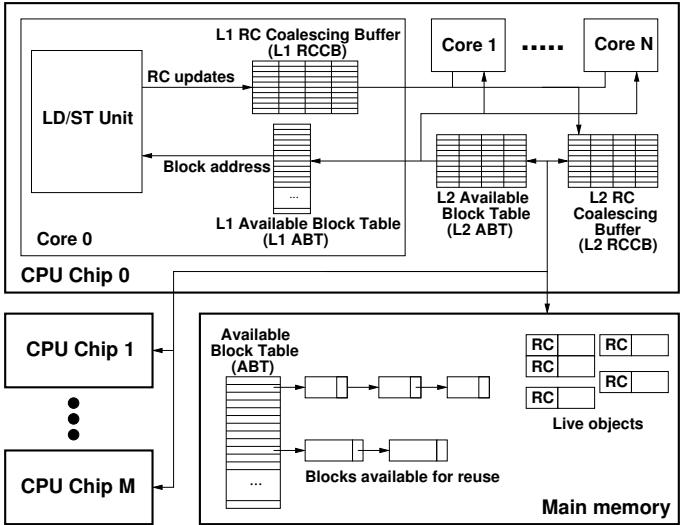 Figure 2: Overview of the major hardware structures provided by HAMM (components are not to scale)
Figure 2: Overview of the major hardware structures provided by HAMM (components are not to scale)
结果
- 在 Java DaCapo 基准测试集上,使用 Jikes RVM 的生产级分代式垃圾回收器(GenMS)进行评估。
- 垃圾回收时间: HAMM 能够平均减少 31% 的 GC 时间。对于不同堆大小(1.5x 到 3x 最小堆),GC 时间减少幅度稳定在 29%-31%。
- 具体收益来源:
- 新生代: 平均减少 52% 的新生代回收次数。
- 老年代: 平均减少 50% 的全堆回收次数,并且每次全堆回收需要处理的存活对象空间平均减少 49%。
- 对应用程序(Mutator): 对应用程序本身的性能影响微乎其微,平均仅下降 0.38%,证明了其低侵入性。
| 堆大小 (相对 minHeap) | 平均 GC 时间减少 |
|---|---|
| 1.5x | 29% |
| 2.5x | 31% |
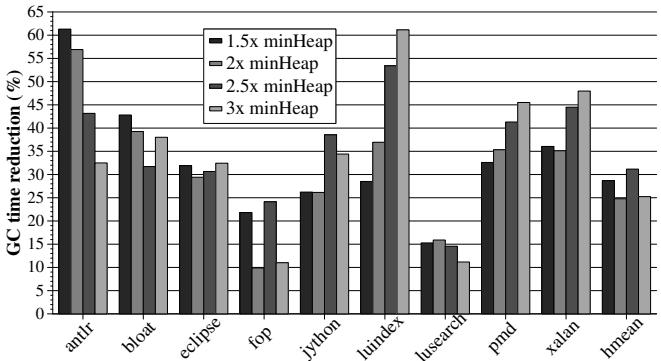 Figure 4: Reduction in GC time for different heap sizes
Figure 4: Reduction in GC time for different heap sizes
结论
- HAMM 作为一种灵活的硬件加速方案,成功地利用硬件实现了高效的引用计数,有效补充而非替代了现有的软件垃圾回收算法。
- 该方案显著降低了 GC 开销(平均 31%),同时几乎不影响应用程序的运行性能,并且保持了与现有软件生态的兼容性。
- 此工作为未来处理器设计提供了新思路,即通过专用、低成本的硬件原语来加速通用但开销巨大的运行时服务(如 GC),尤其适用于内存受限的嵌入式或移动系统。
2. 背景知识与核心贡献¶
研究背景
- 自动内存管理(garbage collection, GC)是现代managed languages(如 Java、C#)的核心特性,它通过消除手动
free操作来避免内存泄漏和悬空指针等严重安全与可靠性问题。 - 尽管GC带来了软件工程上的巨大优势,但它也引入了显著的性能开销和暂停时间(pause times),这限制了其在高性能计算和实时系统中的应用。
- 当前主流的软件垃圾回收器(如 generational collector)虽然高效,但在堆内存紧张时,GC开销会急剧上升。如图1所示,在 DaCapo 基准测试中,当堆大小仅为最小需求的1.5倍时,GC开销可高达 15%-55%。
- 引用计数(reference counting, RC)作为一种替代方案,能即时回收死对象,但其在软件中实现时存在两大致命缺陷:1) 每次指针更新都需同步修改引用计数,带来极高开销;2) 无法处理循环引用(cyclic data structures)。
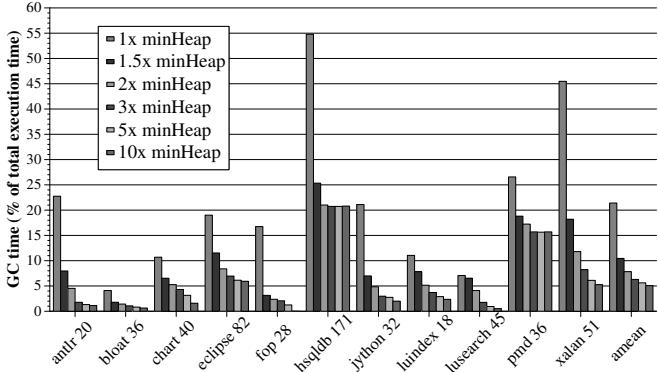 Figure 1: Garbage collection overheads for DaCapo benchmarks with different heap sizes (minHeap values in MB shown in labels)
Figure 1: Garbage collection overheads for DaCapo benchmarks with different heap sizes (minHeap values in MB shown in labels)
研究动机
- 纯硬件垃圾回收器(Hardware GC)虽能加速,但存在严重弊端:
- 缺乏灵活性:将特定GC算法硬编码到ISA和微架构中,无法适应不同应用的需求。
- 开发成本高昂:需要对处理器或内存架构进行大规模改动。
- 错失软件优化机会:无法利用软件层面的优化,如通过GC改善内存局部性(locality)。
- 随着芯片上晶体管数量的增加,业界趋势转向集成专用硬件加速器(special-purpose hardware blocks)来处理常见且开销大的任务。GC作为现代语言中日益突出的性能瓶颈,是理想的加速目标。
- 因此,亟需一种软硬件协同(cooperative hardware-software)的方案,既能利用硬件加速来降低GC频率和开销,又能保留软件GC的灵活性和高级优化能力。
核心贡献
- 提出 HAMM (Hardware-Assisted Automatic Memory Management),一种基于硬件辅助引用计数的GC加速机制。其核心思想是让硬件高效地发现并回收死对象,从而延迟甚至避免昂贵的软件GC调用。
- HAMM 的关键创新在于两个硬件组件:
- 引用计数合并缓冲区(Reference Count Coalescing Buffers, RCCBs):通过L1/L2两级缓冲区合并对同一对象的多次引用计数更新,平均过滤掉96.3% 的冗余内存写操作,从根本上解决了RC的高开销问题。
- 可用块表(Available Block Tables, ABTs):维护一个快速访问的空闲内存块列表,使内存分配器能以极低延迟重用被硬件回收的内存块。
- HAMM 是一种非侵入式(non-intrusive)的加速方案:
- 兼容性强:与现有的软件GC算法(如 generational collector)完全兼容,无需重写GC逻辑。
- 保持灵活性:内存分配器可以自由选择是从ABT中重用内存块,还是使用其默认的分配策略(如 bump-pointer),从而保留了软件层面的优化空间。
- 实验评估表明,在运行 Jikes RVM(配备先进的 generational GC)的 Java DaCapo benchmarks 上,HAMM 能够平均减少31%的垃圾回收时间,而对应用程序本身(mutator)的性能影响微乎其微(仅下降0.38%)。
3. 核心技术和实现细节¶
0. 技术架构概览¶
整体技术架构
本文提出的 HAMM (Hardware-Assisted Automatic Memory Management) 是一种软硬件协同的垃圾回收加速方案,其核心思想是利用低成本的硬件辅助引用计数 (reference counting) 来及时发现并重用死亡对象的内存空间,从而减少软件垃圾回收 (GC) 的频率和开销,同时保留软件 GC 的灵活性。
- 目标: 不是取代软件 GC,而是作为其补充,通过硬件加速来降低 GC 总体开销。
- 兼容性: 与现有的软件 GC 算法(如分代收集器)兼容,不破坏现有软件生态。
- 关键成果: 在 Java DaCapo 基准测试上,平均减少 31% 的垃圾回收时间。
核心硬件组件
HAMM 架构主要由两大硬件组件构成:引用计数跟踪和内存块重用处理。
-
引用计数跟踪 (Reference Count Tracking)
- 对象头 (Object Header): 每个对象在内存中都有一个引用计数 (RC) 字段。
- 引用计数合并缓冲区 (RCCB, Reference Count Coalescing Buffers): 采用两级缓存结构来高效处理 RC 更新,大幅减少内存流量。
- L1 RCCB: 位于每个处理器核心内,用于合并该核心产生的 RC 更新。
- L2 RCCB: 位于芯片级,用于合并来自所有核心的 RC 更新,并最终将净更新值写回主存中的对象头。
- 效果: RCCB 层级结构能过滤掉 96.3% 的 RC 更新,解决了传统引用计数开销过大的问题。
-
内存块重用处理 (Memory Block Reuse Handling)
- 可用块表 (ABT, Available Block Table): 一个硬件维护的、按大小分类的空闲内存块列表,用于快速提供可重用的内存地址。
- Memory ABT: 存储在主存中,是全局的可用块列表。
- L2 ABT: 芯片级缓存,为 L1 ABT 提供数据。
- L1 ABT: 核心级缓存,供内存分配器快速访问,避免长延迟的缓存未命中。
- 工作流程: 当硬件确认一个对象死亡(RC=0)后,将其内存块地址加入 Memory ABT;L2 和 L1 ABT 会预取这些地址,以便分配器能即时重用。
- 可用块表 (ABT, Available Block Table): 一个硬件维护的、按大小分类的空闲内存块列表,用于快速提供可重用的内存地址。
Figure 2: Overview of the major hardware structures provided by HAMM (components are not to scale)
软件-硬件交互接口
为了实现协同工作,HAMM 定义了新的 ISA 指令,作为软件(编译器、分配器、GC)与硬件之间的桥梁。
-
内存分配相关指令:
REALLOCMEM: 分配器调用此指令,向硬件查询是否有可重用的内存块。若有,则直接使用;否则,回退到默认的软件分配策略(如 bump-pointer)。ALLOCMEM: 分配器在成功分配(无论是重用还是新分配)后,通知硬件新内存块的存在。
-
垃圾回收相关指令:
FLUSHRC: 在软件 GC 开始时调用,用于确保所有待处理的 RC 更新都已应用到对象头,以保证 GC 的正确性。
对特殊场景的处理
HAMM 设计了专门的机制来处理寄存器、栈以及多应用/多内存区域等复杂情况。
- 寄存器中的引用: 通过在寄存器文件中增加一个 Reference bit 来标记寄存器是否包含指针。当寄存器被非指针值覆盖时,硬件会自动生成
decRC操作。 - 栈上的引用: 在 L1 缓存中为每个字增加一个 Reference bit。当栈帧失效(如函数返回)或栈上位置被覆盖时,硬件会惰性地处理
decRC操作。 - 多管理内存区域: 通过扩展页表项 (Page Table Entry) 和 TLB,引入 region ID 和 application ID 来区分不同应用和不同代(如 nursery 和 old generation)的内存对象,确保硬件操作的隔离性。
1. Reference Count Coalescing Buffers (RCCBs)¶
Reference Count Coalescing Buffers (RCCBs) 的核心作用
- RCCBs 是 HAMM 架构中用于解决传统 reference counting 高开销问题的关键硬件结构。其主要目标是通过合并(coalesce)和过滤(filter)冗余的引用计数更新操作,来大幅降低内存流量和多核同步开销。
- 它采用一个两级缓存层次结构:每个处理器核心拥有一个 L1 RCCB,整个芯片(CMP)共享一个 L2 RCCB。这种设计有效利用了局部性原理,并处理了跨核共享对象的更新。
实现原理与数据结构
- RCCBs 本质上是组相联(set-associative)的硬件表。
- 每个 RCCB 表项包含以下关键字段:
- Tag: 存储对象的虚拟地址,用于标识该表项对应的对象。
- Reference Count Delta (RCD): 一个有符号整数,用于累积对该对象的所有引用计数增量(incRC)和减量(decRC)操作的净变化值。
- 当一个新的 incRC 或 decRC 操作产生时,硬件会根据对象地址在 RCCB 中进行查找。如果命中,则直接更新对应表项的 RCD 字段;如果未命中,则可能需要分配一个新表项或触发驱逐。
算法流程与工作方式
- 更新生成:
- 当执行特殊的 store pointer 指令(如
STOREPTR或STOREPTROVR)时,硬件会非推测性地(non-speculatively)在指令提交(commit)阶段生成 incRC 和/或 decRC 操作。 - 对于寄存器和栈上的引用销毁,也会通过额外的硬件位(Reference bit)触发 decRC 操作。
- 当执行特殊的 store pointer 指令(如
- L1 RCCB 处理:
- 所有由核心产生的 RC 更新首先被发送到本地 L1 RCCB。
- L1 RCCB 负责合并来自同一核心的、针对同一对象的多次更新。例如,在遍历链表时,对中间节点的 incRC 和 decRC 操作会在 L1 RCCB 中相互抵消,最终净变化为零。
- L2 RCCB 处理:
- 当 L1 RCCB 的某个表项因容量限制被驱逐(evicted)时,其累积的 RCD 值会被发送到芯片级的 L2 RCCB。
- L2 RCCB 的作用是合并来自不同核心的、针对共享对象的 RC 更新。这避免了多个核心频繁地直接竞争更新主存中的同一个引用计数字段,从而极大地减少了同步开销。
- 写回主存:
- 当 L2 RCCB 的表项被驱逐时,其最终的 RCD 值才会被应用到主存中对象头(object header)里的实际引用计数字段上。
- 这个过程确保了只有净变化(net delta)才会写入主存,而不是每一次细粒度的增减操作。
参数设置与性能指标
- 论文提到,L1 RCCB 能够平均过滤掉 90.6% 的引用计数更新。
- 整个 RCCB 层次结构(L1 + L2)能够平均过滤掉 96.3% 的更新。
- 这些高效的过滤率直接证明了 RCCB 设计的有效性,它成功地中和了 reference counting 最主要的两个缺点:显著增加的内存流量和每次更新都需要同步。
输入输出关系及在 HAMM 中的整体作用
- 输入: 来自处理器流水线的各种 incRC 和 decRC 操作。这些操作由 store pointer 指令、寄存器覆盖和栈帧销毁等事件触发。
- 输出: 经过合并和过滤后的、净的引用计数变化(RCD),最终写入主存对象头。更重要的是,当一个对象的引用计数在主存中被更新为零,并且确认所有 RCCB 中都没有针对它的待处理更新时,该对象被判定为死亡(dead)。
- 整体作用:
- 降低开销: 作为 HAMM 的第一大组件(reference count tracking),RCCBs 是实现低开销硬件辅助引用计数的核心,使得在硬件中维护引用计数变得可行。
- 赋能内存重用: 通过高效、准确地检测死亡对象,RCCBs 为第二大组件(Available Block Tables, ABTs)提供了“原材料”。死亡对象的内存块被加入 ABT,供后续的
REALLOCMEM指令快速重用,从而延迟甚至避免了软件垃圾回收的执行。 - 保持灵活性: RCCBs 仅负责底层的计数跟踪和死亡检测,而将“是否重用”以及“如何管理内存布局”等高级决策权完全交给软件分配器和垃圾回收器,完美体现了 HAMM 软硬件协同(cooperative hardware-software)的设计哲学。
Figure 2: Overview of the major hardware structures provided by HAMM (components are not to scale)
RCCB 层次结构与对象死亡判定流程
- 对象死亡的判定是一个谨慎的过程,以避免因更新延迟而导致的错误回收。
- 当 L2 RCCB 驱逐一个 RCD 并将其应用于主存中的对象头后,如果该对象的引用计数变为零,系统不能立即宣布其死亡。
- 硬件必须检查系统中所有的 RCCB(包括所有核心的 L1 和芯片的 L2),以确认没有任何待处理的、针对该对象的 RC 更新(特别是 incRC 操作)。
- 只有当所有 RCCB 中都确认没有挂起的更新时,该对象才能被安全地宣告为死亡,并将其内存块地址插入 **Available Block Table **(ABT) 以供重用。
2. Available Block Tables (ABTs)¶
Available Block Tables (ABTs) 的核心设计与作用
- ABT 是一个分层的、按 size class(大小类别)组织的 free-block lists(空闲块链表)结构,其根本目标是为软件内存分配器提供一种 fast, low-latency(快速、低延迟)的机制,以重用由硬件发现的已死亡对象的内存块。
- 该结构分为三级:L1 ABT(每个核心私有)、L2 ABT(芯片级共享)和 memory ABT(主存中),共同构成了一个高效的缓存层次,将主存中的空闲块信息预取到靠近处理器的地方。
实现原理与算法流程
- 数据结构基础:
- 在主存中,memory ABT 被概念化为一个包含 64个 size class 的表。每个类别对应一个 linked list(链表),链表头指针存储在 ABT 中。
- 当一个对象被硬件确认死亡后,其内存块的起始地址会被插入到对应 size class 链表的头部。链接指针就存储在该已死亡对象原本无用的 object header(对象头)中,实现了零额外空间开销的链表维护。
- L1/L2 ABT 缓存机制:
- L1 ABT:每个处理器核心拥有一个,包含 one entry per size class(每个大小类别一个条目)。这使得分配器在请求特定大小的块时,只需进行一次本地、低延迟的访问。
- L2 ABT:每个 N 核芯片拥有一个,包含 N entries per size class(每个大小类别 N 个条目),用于服务所有核心的 L1 ABT 填充请求。
- 分配流程:
- 软件分配器通过新的 ISA 指令
REALLOCMEM请求一个可重用的内存块。 - 硬件首先检查本地 L1 ABT 中对应 size class 的条目。
- 如果条目非空,则立即返回块地址给软件,并异步地向 L2 ABT 发送一个填充请求,以补充 L1 ABT 的该条目。
- 如果 L1 ABT 为空,
REALLOCMEM返回零,软件分配器则回退到其默认的分配策略(如 bump-pointer)。
- 软件分配器通过新的 ISA 指令
- 填充流程:
- L2 ABT 的条目可以从两个来源填充:1) 由本地 L2 RCCB 发现的死亡对象;2) 从 memory ABT 的对应链表头获取。
- 所有这些通信和填充操作都被设计为 not time-critical(非关键路径),可以低优先级处理,从而避免干扰应用程序的主执行流。
Figure 2: Overview of the major hardware structures provided by HAMM (components are not to scale)
参数设置与配置细节
- Size Class 数量:系统预定义了 64 个大小类别,用于对可重用的内存块进行分类。
- L1 ABT 容量:每个核心的 L1 ABT 为每个 size class 保留 1 个条目。
- L2 ABT 容量:每个芯片的 L2 ABT 为每个 size class 保留 N 个条目(N 为芯片上的核心数)。
- Header 开销:每个对象头需要增加一个 6-bit size class field,由
ALLOCMEM指令在分配时写入,以便在对象死亡后能正确归类到 ABT 中。
输入输出关系及在 HAMM 整体中的作用
- 输入:
- 来自 **Reference Count Coalescing Buffers **(RCCBs) 的信号:当一个对象的引用计数被确认为零时,其地址和大小类别作为输入,触发该块被加入 memory ABT。
- 输出:
- 通过
REALLOCMEM指令向软件内存分配器提供可重用的内存块地址。
- 通过
- 在整体架构中的作用:
- 解耦与加速:ABT 层次结构将耗时的主存链表操作与时间敏感的内存分配器 解耦。分配器只需访问超快的 L1 ABT,从而实现了 promptly available(即时可用)的内存重用,而不会引入长延迟的缓存未命中。
- 降低 GC 频率:通过高效地提供可重用块,ABT 使得分配器能够延迟甚至避免向操作系统或 GC 运行时请求新内存,从而直接 reduces the frequency of garbage collection(降低垃圾回收频率)。
- 保持软件灵活性:该设计并未强制分配器必须使用重用块。分配器保留了最终决策权,可以选择重用块以提升性能,或选择新分配以优化 locality(局部性),完美体现了 HAMM cooperative hardware-software(软硬件协同)的设计哲学。
3. Hardware-Software Cooperative ISA Extensions¶
核心 ISA 扩展指令集
HAMM 提案通过引入一组新的 ISA instructions,在编译器、内存分配器(allocator)和垃圾回收器(garbage collector)与底层硬件加速机制之间建立了精确的交互通道。这些指令是实现 hardware-software cooperative 模式的基石。
-
REALLOCMEM
- 作用: 允许软件内存分配器向硬件查询是否有可重用的、符合指定大小类(size class)的内存块。
- 输入: 请求的内存块大小(或其对应的 size class)。
- 输出:
- 若成功,返回一个指向可用内存块的非零地址。
- 若失败(即 L1 ABT 中无合适块),返回零地址。
- 在整体中的作用: 这是指令流中分配路径的快速检查点。它使分配器能够优先利用 HAMM 硬件发现的死对象内存,从而延迟甚至避免触发软件 GC。由于它只访问本地 L1 ABT,因此不会引入显著的延迟或同步开销。
- ISA 格式:
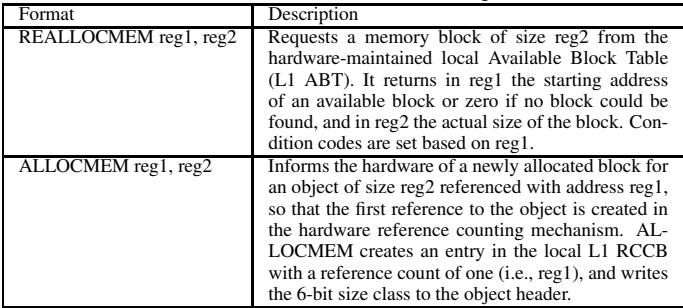 Table 1: HAMM ISA instructions for object allocation
Table 1: HAMM ISA instructions for object allocation
-
ALLOCMEM
- 作用: 在分配器成功获取一块内存(无论是通过 REALLOCMEM 重用还是通过默认策略新分配)后,通知硬件该内存块已被分配,并初始化其元数据。
- 输入: 新分配内存块的起始地址和其大小类(size class)。
- 输出: 无显式返回值,但会触发硬件操作。
- 在整体中的作用: 硬件利用此信息在对象头(object header)中写入 6-bit size class field,并可能将引用计数(RC field)初始化为 1(或根据上下文确定)。这确保了后续对该对象的指针操作能被硬件正确跟踪。
- ISA 格式:
Table 1: HAMM ISA instructions for object allocation
-
Store Pointer 指令变体 (STPTR, STPTROVR)
- 作用: 这些是指令集的核心创新,将指针存储语义与引用计数更新语义原子地结合在一起。
- 算法流程:
- 当执行
STPTR(Store Pointer) 时,硬件除了存储指针值 P 外,还会为地址 P 生成一个 incRC (increment reference count) 操作。 - 当执行
STPTROVR(Store Pointer Overwrite) 时,硬件首先读取被覆盖的旧指针值 Q,然后存储新值 P,并同时生成两个操作:为 Q 生成 decRC (decrement reference count),为 P 生成 incRC。
- 当执行
- 在整体中的作用: 这些指令由编译器在识别到指针赋值时发出。它们将原本需要软件显式处理的、高开销的 RC 更新操作,无缝地委托给硬件流水线处理。硬件利用缓存一致性协议来保证多核环境下的同步,避免了软件层面昂贵的 CAS (Compare-and-Swap) 循环。
- ISA 格式与语义:
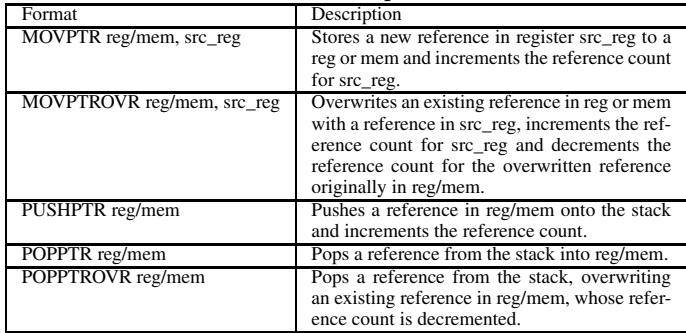 Table 2: HAMM ISA store pointer instructions
Table 2: HAMM ISA store pointer instructions
-
FLUSHRC
- 作用: 在软件垃圾回收器启动时,用于确保特定对象的所有挂起的引用计数更新都已从 RCCB 层级刷新到主存中的对象头。
- 输入: 目标对象的地址。
- 输出: 无显式返回值,但指令会阻塞直到该对象的所有 RC 更新完成。
- 在整体中的作用: 这是软硬件协同的关键安全机制。在 GC 移动(copying/compacting)对象之前,必须确认其 RC 字段是最新的,否则 RCCB 中残留的旧地址更新会丢失或写入错误位置,导致严重错误。该指令使得软件 GC 能够安全地与异步的硬件 RC 机制共存。
- ISA 格式:
 Table 3: HAMM ISA instruction for garbage collection
Table 3: HAMM ISA instruction for garbage collection
寄存器与栈的特殊处理
为了完整跟踪所有引用,提案对寄存器和栈上的指针进行了特殊处理,这也隐含了 ISA 和微架构的扩展。
-
寄存器中的引用:
- 实现原理: 在寄存器文件中为每个寄存器增加一个 Reference bit。
- 算法流程:
- 当任何 store pointer 指令将一个指针写入寄存器时,该寄存器的 Reference bit 被置位。
- 当任何非指针指令覆盖该寄存器时,Reference bit 被清除,并将原指针值作为 decRC 操作送入流水线。
- 作用: 确保寄存器中指针的生命周期被精确跟踪,避免了传统 deferred RC 需要扫描整个寄存器文件的开销。
-
栈上的引用:
- 实现原理: 在 L1 数据缓存中为每个字(word)增加一个 Reference bit。
- 算法流程:
- Store pointer 指令写入栈时,对应缓存行字的 Reference bit 被置位。
- 该 bit 在两种情况下被清除并触发 decRC:1) 其他指令覆盖该栈位置;2) 通过特殊的
POPPTR/POPPTROVR指令弹出栈顶(模拟函数返回)。 - 对于因调整栈指针而“悬空”的栈帧区域,硬件采用惰性策略:仅在缓存行被驱逐或该位置被重新写入时,才处理其中标记为引用的值并发出 decRC。
- 作用: 高效地处理了栈上大量短生命周期指针的 RC 更新,将其开销分摊到非关键路径上。
软硬件交互的整体工作流
-
分配阶段:
- 编译器生成的分配代码首先调用 REALLOCMEM。
- 若成功,则直接使用返回的地址;若失败,则走默认分配路径(如 bump-pointer)。
- 无论哪种方式,最终都会调用 ALLOCMEM 通知硬件。
-
运行阶段 (Mutator):
- 编译器将所有指针赋值操作编译为 STPTR 或 STPTROVR 指令。
- 这些指令在提交(commit)时,非推测性地(non-speculatively)生成 incRC/decRC 操作。
- 这些操作被送入 L1 RCCB 进行合并(coalescing),大幅减少内存流量。
-
死亡检测与重用:
- 当 L2 RCCB 条目被驱逐并更新主存中的对象头 RC 字段至零时,硬件会扫描该死对象(利用 ORM 表)以递归地对其内部指针发出 decRC。
- 死对象的地址被加入 ABT 层级结构(Memory ABT -> L2 ABT -> L1 ABT),等待被 REALLOCMEM 重用。
-
垃圾回收阶段 (GC):
- 软件 GC 启动时,首先重置 ABT,因为 GC 会全面掌握所有可用内存。
- 在移动任何对象前,GC 代码会为该对象调用 FLUSHRC,确保其 RC 状态一致。
- GC 完成后,系统恢复到步骤1,继续利用 HAMM 进行内存重用。
4. Object Reference Map (ORM) for Dead Object Scanning¶
实现原理与核心目的
- Object Reference Map (ORM) 是一个由 软件运行时系统 (software runtime system) 维护的、位于 主内存 (main memory) 中的查找表。
- 其核心目的是为 硬件 (hardware) 提供一种高效、无需软件干预的方式来 扫描已死亡对象 (dead objects) 的内部字段,以识别其中包含的 指针 (pointers)。
- 一旦识别出内部指针,硬件就能自动为这些被指向的对象 递归地 (recursively) 发起 decRC (decrement reference count) 操作,从而确保整个不可达对象图都能被正确回收,这是基础引用计数无法处理循环引用的关键补充机制。
数据结构与参数设置
- ORM 被实现为一个 1K-entry (1024项) 的哈希表。
- 索引与标签 (Indexing and Tagging):
- 表的索引和全相联标签均基于对象头中的 唯一类型标识符 (unique type identifier)。在 Java 等语言中,这通常是 指向运行时类型信息 (runtime type information) 的指针。
- 表项内容 (Entry Content):
- 每个 ORM 表项包含一个 1-word bitmap (32位或64位,取决于架构)。
- 该 bitmap 的每一位对应对象布局中的一个 word (字)。如果某一位被置为 1,则表示该 word 在对象中是一个 引用字段 (reference field),即包含一个指针。
算法流程
- 触发条件: 当 HAMM 硬件通过引用计数确认一个对象死亡后,会立即尝试扫描该对象。
- 查询 ORM:
- 硬件从死亡对象的 对象头 (object header) 中读取其 类型标识符 (type identifier)。
- 使用该标识符作为键,在 ORM 表中进行查找,获取对应的 reference bitmap。
- 应用 Bitmap:
- 获取到的 reference bitmap 会被 对齐 (aligned) 并 应用 (applied) 到包含该死亡对象的 L1 cache line 的 Reference bits 上。
- 这个过程将死亡对象内部哪些 word 是指针的信息“标记”到了缓存行上。
- 发起递归 Decrement:
- 硬件复用其用于处理 栈帧销毁 (discarded stack frames) 的现有逻辑(如 Section 2.3.2 所述),来遍历这些被标记的 Reference bits。
- 对于每一个被标记为引用的 word,硬件会将其值(即指向的子对象地址)作为参数,发起一个 decRC 操作。
- 这些 decRC 操作会进入 RCCB (Reference Count Coalescing Buffer) 层级结构,并最终可能导致更多对象的引用计数归零,从而形成递归回收。
输入输出关系
- 输入:
- 一个被 HAMM 硬件判定为 死亡 (dead) 的对象的 内存地址。
- 该对象头中的 类型标识符 (type identifier)。
- 输出:
- 一系列针对该死亡对象内部指针所指向的子对象的 decRC 操作,这些操作被注入到 RCCB 流水线中。
- 最终效果是,该死亡对象内部的所有直接子对象的引用计数都被正确地 减一。
在整体系统中的作用
- 解决循环引用问题: 这是 HAMM 方案能够有效工作的关键。纯引用计数无法回收循环结构,而 ORM 驱动的对象扫描机制使得 HAMM 能够像 tracing GC 一样,回收整个不可达的对象图,极大地提高了死对象检测的 覆盖率 (coverage)。
- 维持硬件加速优势: 整个扫描和递归 decrement 过程完全由 硬件自动完成,无需陷入软件 GC 例程,从而保持了低延迟和高效率。
- 与软件协同: 软件运行时负责 按需填充 ORM 表(通常只为最常用的类型),而硬件负责 高效利用 这些信息。这是一种典型的 软硬件协同设计 (hardware-software co-design)。
- 保障正确性: 论文明确指出,即使某些对象的 ORM 条目缺失或未及时更新,也不会导致 正确性 (correctness) 问题。最坏情况只是错过了提前回收的机会,这些“漏网之鱼”最终仍会被 后备的软件垃圾收集器 (default software GC) 回收。

4. 实验方法与实验结果¶
实验设置
- 基准平台:实验在 Jikes RVM 2.9.3 的生产配置上进行,该配置使用了名为 GenMS 的state-of-the-art generational garbage collector(分代垃圾回收器),其对新生代(nursery)采用 copying collector,对老年代(older generation)采用 mark-sweep collector。
- 基准测试套件:使用 Java DaCapo benchmarks (2006-10-MR2, large input set),排除了 chart 和 hsqldb 两个无法在模拟环境中运行的 benchmark。
- 模拟环境:基于 Simics 3.0.29 功能模拟器,并通过一个自定义模块实现了 HAMM 的硬件结构和新 ISA 指令。
- 性能评估方法:
- GC 时间评估:由于全周期精确模拟不可行,作者采用了一个基于 Buytaert et al. [10] 的模型,即 GC time is an approximately linear function of the surviving objects。该模型认为新生代 GC 工作量与存活对象大小成正比(需复制),老年代 GC 工作量与存活对象数量成正比(需标记)。
- Mutator 性能评估:使用一个周期精确的 x86 模拟器,对 baseline 和 HAMM 在相同算法点截取的 200M instructions slices 进行模拟,以评估 HAMM 对应用程序本身性能的影响。
- 硬件配置:模拟的基线处理器配置如
Table 7所示。
 Table 7: Baseline processor configuration
Table 7: Baseline processor configuration
结果数据
- GC 时间减少:
- 在 1.5x 到 3x minHeap 的合理堆大小范围内,HAMM 平均减少了 31% 的 GC 时间。
- 效果最好的案例是 antlr,在 1.5x minHeap 下 GC 时间减少了 61%。
- 在 fop benchmark 上,当堆大小为 4x minHeap 时,HAMM 完全消除了软件 GC 的需求。
- 最差的情况是 lusearch 在 1.2x minHeap 下,GC 时间仅 轻微增加了 0.6%。
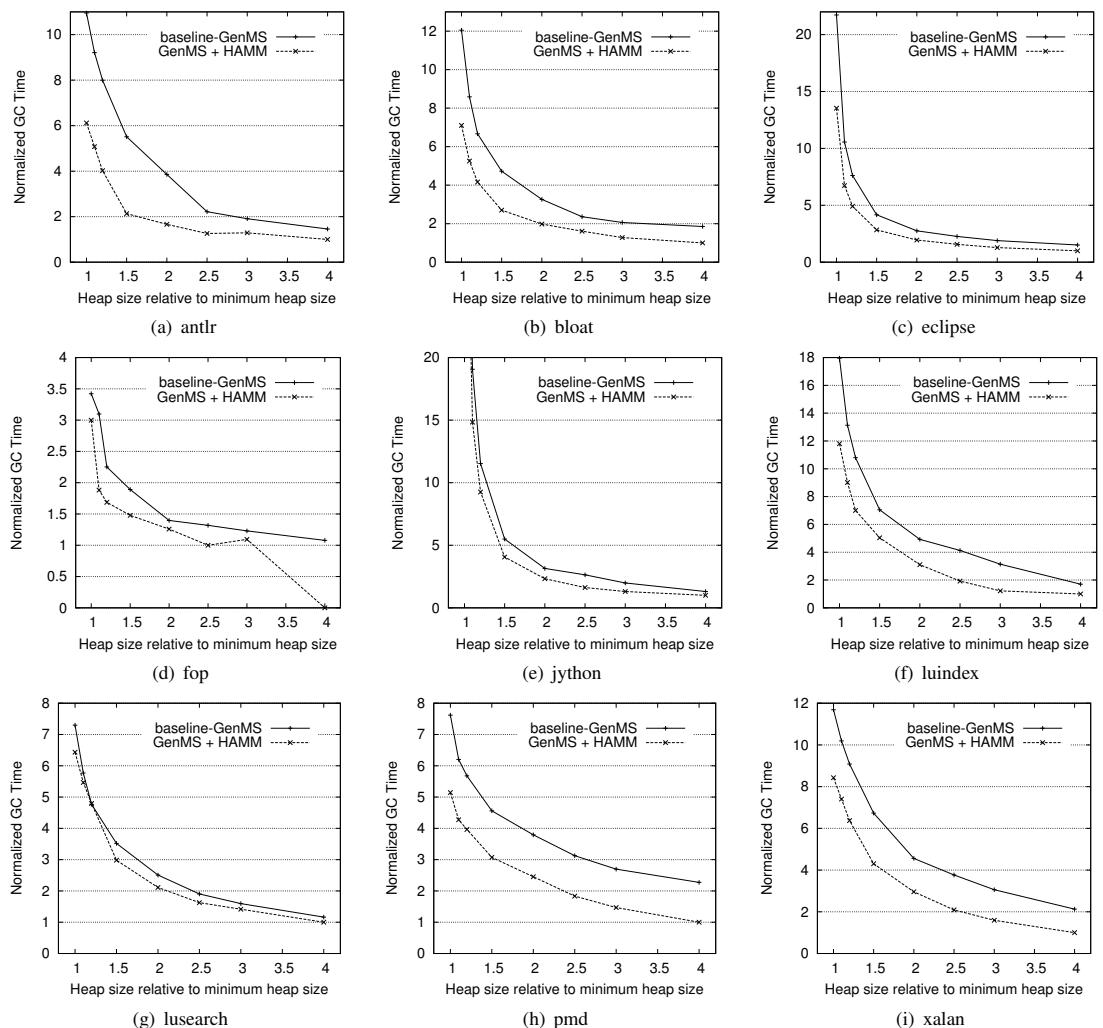 Figure 3: Estimated garbage collection time with HAMM compared to the baseline Generational Mark-Sweep collector.
Figure 4: Reduction in GC time for different heap sizes
Figure 3: Estimated garbage collection time with HAMM compared to the baseline Generational Mark-Sweep collector.
Figure 4: Reduction in GC time for different heap sizes
-
收益来源分析:
-
新生代 (Nursery):
- 平均 69% 的新对象通过 HAMM 重用了内存块。
- 新生代 GC 次数平均减少了 52%。
- 尽管每次 GC 需要复制更多存活对象,但 总复制到老年代的字节数平均减少了 21%。
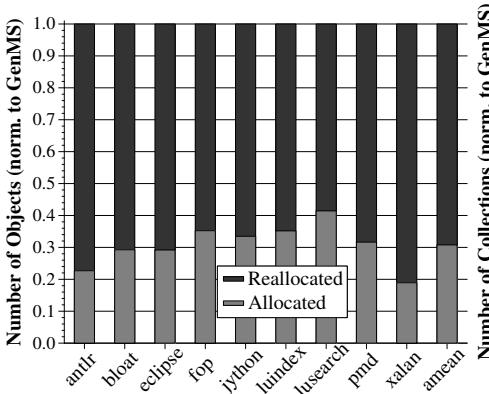 Figure 5: Objects newly allocated and reallocated in the nursery
Figure 5: Objects newly allocated and reallocated in the nursery
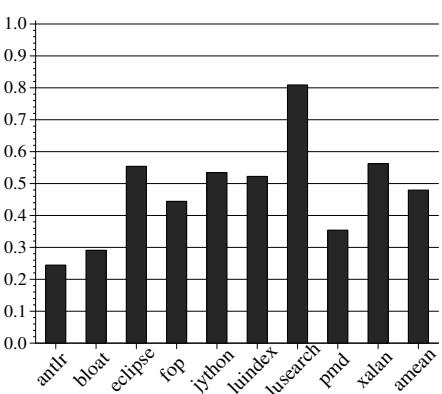 Figure 6: Number of nursery collections
Figure 6: Number of nursery collections
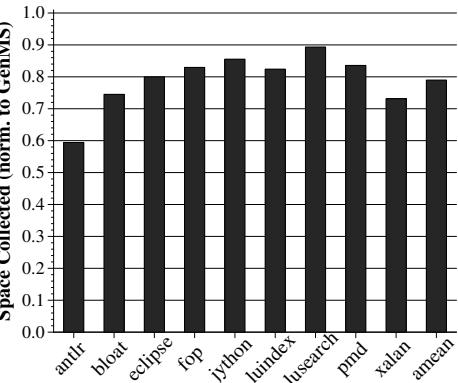 Figure 7: Total surviving space copied during nursery collections
Figure 7: Total surviving space copied during nursery collections -
老年代 (Older Generation):
- 分配到老年代的对象总数平均减少了 21%,因为延迟 GC 让更多对象在晋升前就死亡了。
- 老年代内存块的 重用率平均为 38%。
- Full-heap GC 次数平均减少了 50%。
- 每次 Full-heap GC 发现的存活空间平均减少了 49%。
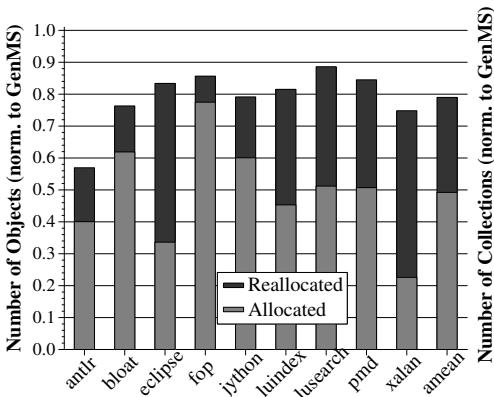 Figure 8: Objects allocated and reallocated in the older generation
Figure 8: Objects allocated and reallocated in the older generation
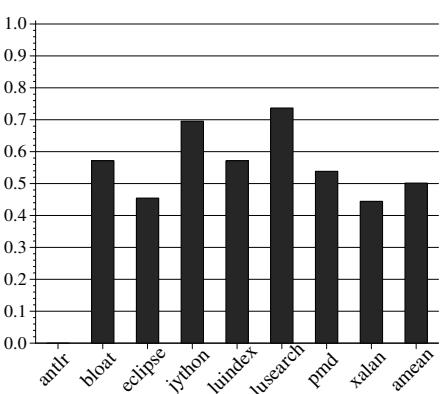 Figure 9: Number of full-heap collections
Figure 9: Number of full-heap collections
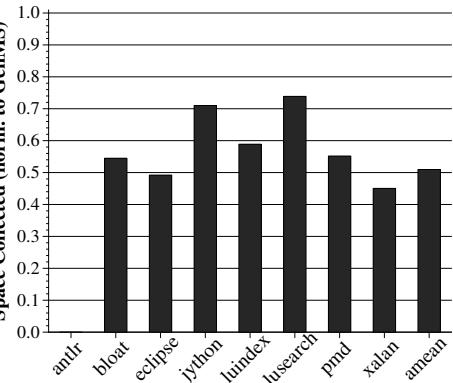 Figure 10: Total surviving space during full-heap collections
Figure 10: Total surviving space during full-heap collections
-
-
对 Mutator 性能的影响:
- HAMM 对应用程序(mutator)本身的性能影响微乎其微,平均性能下降仅为 0.38%。
- 主要副作用是略微增加了缓存压力:L1 cache misses 最多增加 4%,L2 cache misses 对所有 benchmark 都有所增加(最多 3.4%)。
- HAMM 自身产生的额外内存访问导致了 0.6% 到 6.8% 的 L2 cache misses,但由于这些操作不在关键路径上,对性能影响很小。
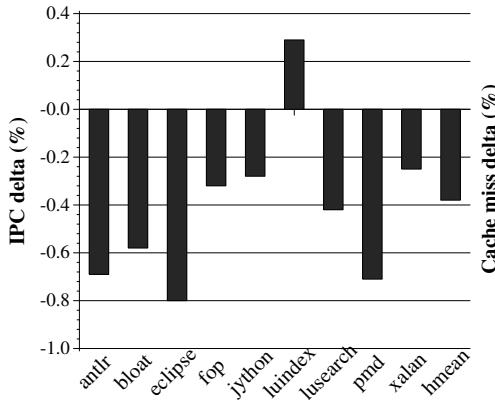 Figure 11: Mutator performance
Figure 11: Mutator performance
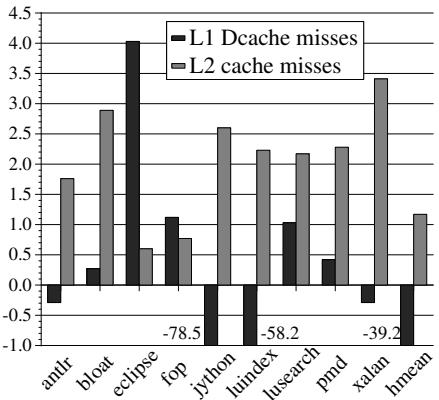 Figure 12: L1D and L2 cache misses
Figure 12: L1D and L2 cache misses
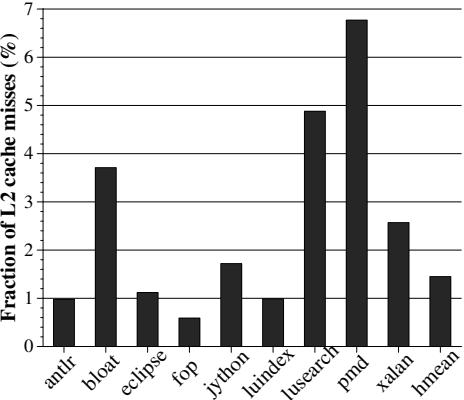 Figure 13: L2 misses due to HAMM
Figure 13: L2 misses due to HAMM
消融实验
该论文并未进行传统意义上的、系统性的消融实验(例如,逐一关闭 RCCB 或 ABT 来观察性能变化)。然而,论文通过深入的数据分析,间接地揭示了其核心组件的有效性:
-
RCCB (Reference Count Coalescing Buffers) 的有效性:
- 论文明确指出,L1 RCCB 平均过滤了 90.6% 的引用计数更新,而整个 RCCB 层次结构(L1+L2)平均过滤了 96.3% 的更新。这直接证明了 RCCB 对于缓解引用计数带来的巨大内存流量和同步开销至关重要。如果没有 RCCB,该方案将因性能开销过大而不可行。
-
ABT (Available Block Tables) 的有效性:
- 论文强调,ABT 的设计是为了让
REALLOCMEM指令能够快速、无延迟地从本地 L1 ABT 获取可用内存块,避免了在关键的内存分配路径上引入缓存未命中或同步开销。虽然没有直接对比“有无 ABT”的性能,但其设计目标和实现方式本身就论证了其必要性,以确保 mutator 性能不受影响。
- 论文强调,ABT 的设计是为了让
-
整体机制的贡献分解:
- 通过对 新生代和老年代的 GC 行为(如 GC 次数、存活对象数量、内存块重用率)进行详细拆解,论文清晰地展示了 HAMM 的收益并非来自单一因素,而是 “减少 GC 频率” 和 “减轻单次 GC 工作量” 共同作用的结果。这种分析起到了类似消融实验的作用,阐明了不同层面的优化效果。