Drishti: Do Not Forget Slicing While Designing Last-Level Cache Replacement Policies for Many-Core Systems 论文解析¶
0. 论文基本信息¶
作者 (Authors)
- Sweta
- Prerna Priyadarshini
- Biswabandan Panda
发表期刊/会议 (Journal/Conference)
- 58th IEEE/ACM International Symposium on Microarchitecture (MICRO '25)
发表年份 (Publication Year)
- 2025
1. 摘要¶
目的
- 研究发现,当前先进的 Last-level Cache (LLC) 替换策略(如 Hawkeye 和 Mockingjay)在商业多核处理器普遍采用的 sliced LLC 架构上效果不佳,主要存在两大问题:
- Myopic predictions (短视预测):每个 LLC slice 拥有独立的 reuse predictor,只能看到访问到本 slice 的数据,无法获知全局的重用行为,导致预测不准确。
- Under-utilized sampled cache (采样缓存利用率低):用于驱动替换决策的 sampled cache 所对应的 LLC sets 接收到的 miss 请求分布不均,部分 sets 因 miss 过少而无法有效训练 predictor。
方法
- 提出 Drishti,一种针对 sliced LLC 架构优化现有替换策略的增强框架,包含两大核心增强:
- Per-core yet global reuse predictor (每核全局重用预测器):为每个 core 配备一个全局预测器,该预测器能接收来自所有 LLC slices 的训练信息。为解决由此产生的片间通信开销,引入了一个名为 NOCSTAR 的专用低延迟互连网络,将 slice 到 predictor 的通信延迟从平均 20 cycles 降至 3 cycles。
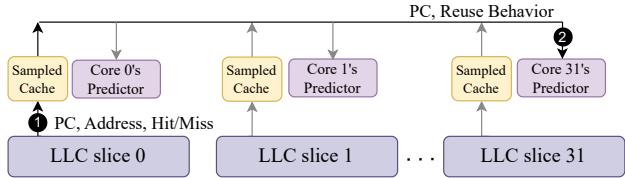
Figure 9: Drishti's enhancement: Tracking reuse behavior and training the per-core and yet global reuse predictor with local (per-slice) sampled caches.
- Per-slice dynamic sampled cache (每片动态采样缓存):摒弃随机选择采样 sets 的传统方法,改为动态监控每个 slice 内各 set 的 Misses Per Kilo Access (MPKA),并优先选择 MPKA 值高的 sets 作为采样集,以确保采样缓存能接收到足够且有代表性的 miss 事件用于训练。
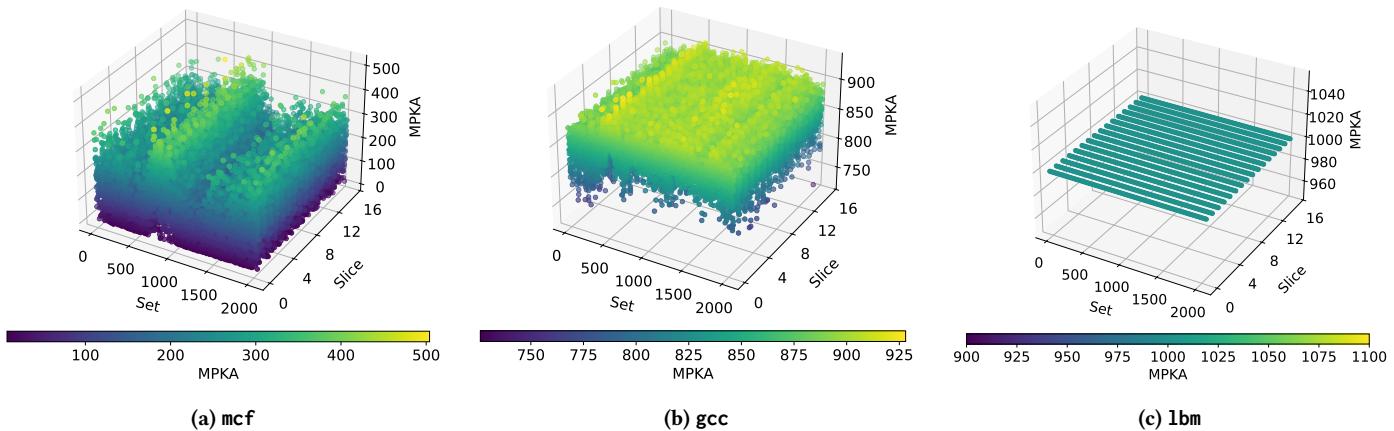
Figure 5: Miss per kilo accesses (MPKA) per LLC set with three different 16-core homogeneous workloads.
结果
- 在 32-core, 64MB sliced LLC 系统上,Drishti 显著提升了先进替换策略的性能:
- Hawkeye 的性能增益从 3.3% 提升至 5.6%。
- Mockingjay 的性能增益从 6.7% 大幅提升至 13.2%。
- Drishti 不仅提升了性能,还降低了硬件开销,实现了净存储节省:
- Hawkeye 每核节省 7.25KB。
- Mockingjay 每核节省 2.96KB。
- 详细的效能分解表明,两项增强均贡献显著,其中 per-core global predictor 主要解决了 xalan 等受短视效应严重影响的工作负载,而 dynamic sampled cache 则在 mcf 等采样集访问不均的工作负载上效果突出。
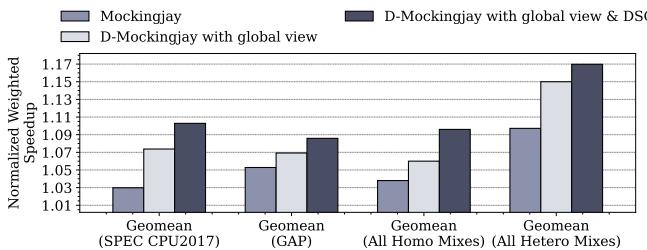
Figure 17: Performance normalized to LRU with only global view and D-Mockingjay with global view & DSC across 32- core 35 homogeneous and heterogeneous mixes.
- Drishti 的设计具有良好的可扩展性,在 64-core 和 128-core 系统上依然有效,并且对不同类型的硬件预取器和工作负载(包括数据中心 traces)都表现出鲁棒性。
结论
- 在为 many-core 系统的 sliced LLC 设计替换策略时,必须考虑 slice 架构带来的独特挑战。Drishti 通过引入 每核全局预测器 和 动态采样缓存,有效克服了现有策略的 短视预测 和 采样集利用不足 问题。
- 该工作证明,通过对现有先进策略进行针对性的、与硬件架构紧密结合的增强,可以在不改变其核心算法的前提下,显著提升其在现代处理器上的实际效能,并且还能降低硬件成本。
2. 背景知识与核心贡献¶
研究背景
- 现代高性能 Last-level Cache (LLC) 替换策略(如 Hawkeye 和 Mockingjay)在设计时普遍假设 LLC 是单体式 (monolithic) 的。
- 然而,主流的商业多核/众核处理器(如 AMD Zen3)普遍采用切片式 LLC (sliced LLC) 架构,其中 LLC 被物理分割成多个 Slice,并通过片上互连网络连接,导致非均匀缓存访问 (NUCA)。
- 现有的先进替换策略并未针对这种切片架构进行充分评估和优化,其核心组件(采样缓存 sampled cache 和 重用预测器 reuse predictor)在切片环境下的有效性存在疑问。
研究动机
- 短视预测问题 (Myopic Predictions):在切片 LLC 中,每个 Slice 维护自己的局部预测器。由于来自同一个 Program Counter (PC) 的内存请求会根据地址散列到不同的 Slice,每个局部预测器只能看到该 PC 访问模式的一个局部片段 (myopic view),无法学习到全局的重用行为,导致预测不准确。
-
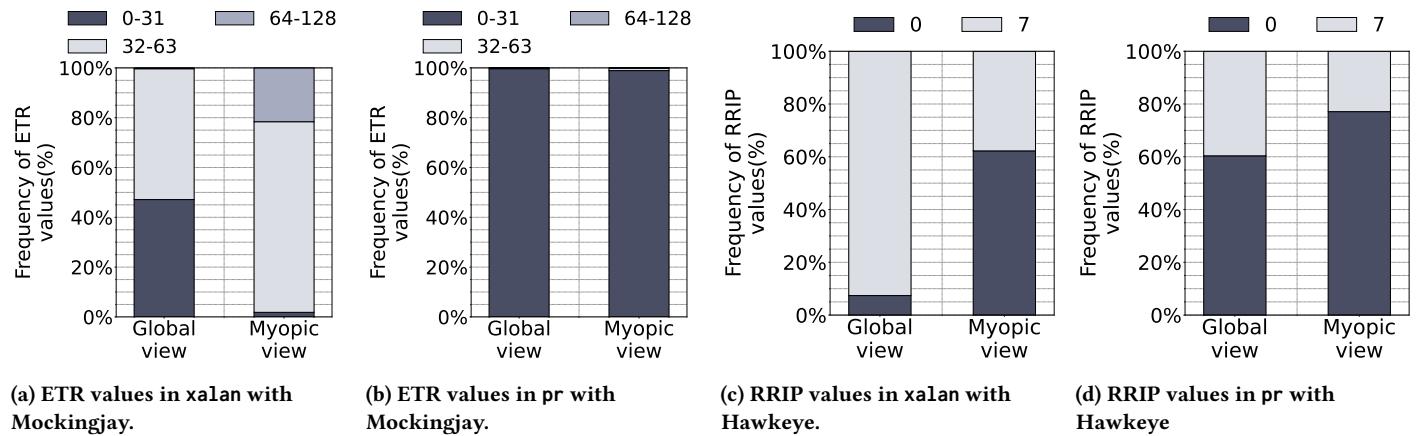
Figure 4: Frequency distributionofETRs and RRIPs in Mockingjay and Hawkeye for xalan and pr running ona16-core system
- 采样缓存利用率不足 (Under-utilized Sampled Cache):现有策略随机选择 LLC Set 作为采样集。但在实际负载下,不同 Set 的 Miss Per Kilo Access (MPKA) 差异巨大,部分采样集接收到的 LLC Misses 极少,无法为预测器提供有效的训练信号,造成资源浪费。
Figure 5: Miss per kilo accesses (MPKA) per LLC set with three different 16-core homogeneous workloads.
-

核心贡献
- 提出了 Drishti,一套用于增强现有先进 LLC 替换策略在切片 LLC 上有效性的通用框架,包含两大核心增强:
- 每核全局重用预测器 (Per-core yet Global Reuse Predictor):摒弃每 Slice 的局部预测器,转而为每个 Core 配置一个全局预测器。该预测器能聚合来自所有 Slice 的、与该 Core 相关的访问信息,从而获得全局视角。为解决由此产生的互连带宽和延迟问题,引入了专用的低延迟互连 NOCSTAR。
Figure 9: Drishti's enhancement: Tracking reuse behavior and training the per-core and yet global reuse predictor with local (per-slice) sampled caches.
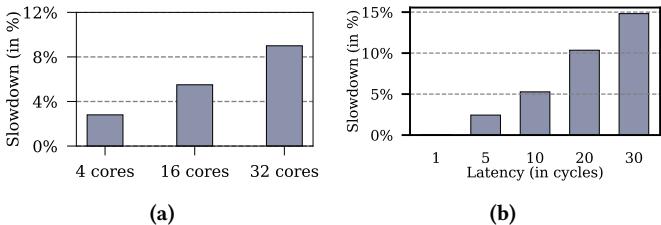
Figure 11: (a) Slowdown in Mockingjay with Drishti without a low-latency interconnect between slices and the predictors. (b)Interconnect latency sensitivity on a 32-core system across 35 homogeneous and 35 heterogeneous mixes.
-
动态采样缓存 (Dynamic Sampled Cache):不再随机选择采样集,而是通过饱和计数器动态监控每个 Slice 内各 Set 的 MPKA,并优先选择高 MPKA 的 Set 作为采样集,确保采样缓存能捕获到最具信息量的缓存缺失事件。
-
效果与优势:
- 在 32-core 系统上,Drishti 将 Hawkeye 和 Mockingjay 相对于 LRU 基线的性能提升从 3.3% 和 6.7% 显著提高到 5.6% 和 13.2%。
- 该方案不仅提升了性能,还节省了存储开销,因为动态采样允许使用更少但更有效的采样集。
- Drishti 的设计理念具有普适性,可有效应用于多种基于采样和预测的替换策略(如 SHiP++, CHROME, Glider)。
| 策略 | 32核系统上相对于LRU的性能提升 |
|---|---|
| Hawkeye | 3.3% |
| D-Hawkeye (Drishti + Hawkeye) | 5.6% |
| Mockingjay | 6.7% |
| D-Mockingjay (Drishti + Mockingjay) | 13.2% |
3. 核心技术和实现细节¶
0. 技术架构概览¶
Drishti 的整体技术架构
Drishti 并非一个全新的 LLC (Last-Level Cache) 替换策略,而是一套旨在提升现有先进替换策略(如 Hawkeye 和 Mockingjay)在多核切片式 LLC (sliced LLC) 环境下性能的增强框架。其核心架构围绕两个关键问题展开:预测器的短视性 (myopic behavior) 和 采样缓存集的利用率不足 (under-utilized sampled sets)。
- 针对预测器短视性问题:
- 传统方案在每个 LLC 切片 (slice) 中维护一个独立的、基于 PC (Program Counter) 的局部重用预测器 (local reuse predictor)。由于来自同一 PC 的内存请求会因地址散列而分布在不同切片上,每个局部预测器只能看到部分访问模式,导致短视决策。
- Drishti 提出采用 “每核全局”重用预测器 (per-core and yet global reuse predictor)。每个核心拥有一个专属的预测器,但该预测器能接收来自所有 LLC 切片的训练信息,从而获得全局视角。
- 为了解决全局预测器带来的片间互连带宽瓶颈,Drishti 保留了每切片局部采样缓存 (local per-slice sampled cache)。采样缓存负责监控其所在切片的访问,并将训练信号发送给对应核心的全局预测器。
- 为了降低预测器访问延迟,Drishti 引入了一个专用的低延迟互连 NOCSTAR,将各切片与预测器连接起来,将通信延迟从平均 20 周期降至 3 周期。
Figure 9: Drishti's enhancement: Tracking reuse behavior and training the per-core and yet global reuse predictor with local (per-slice) sampled caches.
- 针对采样缓存集利用率不足问题:
- 传统方案随机选择 LLC 集合作为采样集。但在实际负载中,不同集合的MPKA (Misses Per Kilo Access) 差异巨大,许多被选中的采样集因访问稀疏而无法有效训练预测器。
- Drishti 提出了 动态采样缓存 (Dynamic Sampled Cache, DSC) 机制。每个切片内部维护一个饱和计数器 (saturating counter) 来监控每个 LLC 集合的 MPKA。
- 在一个监控周期(例如 32K 次加载访问)后,系统会选择 MPKA 最高的 N 个集合作为新的采样集,确保用于训练预测器的数据来自高容量需求区域。
- 该机制还能检测相变 (Phase Change) 和均匀负载(如 lbm),并在必要时回退到随机采样以适应工作负载变化。
Figure 5: Miss per kilo accesses (MPKA) per LLC set with three different 16-core homogeneous workloads.
硬件开销与设计权衡
Drishti 的设计不仅提升了性能,还优化了存储开销。
| 组件 | Hawkeye (无 Drishti) | Hawkeye (有 Drishti) | Mockingjay (无 Drishti) | Mockingjay (有 Drishti) |
|---|---|---|---|---|
| 采样缓存大小 (每核) | 12 KB | 3 KB | 9.41 KB | 4.7 KB |
| 新增饱和计数器 (每核) | - | 1.7 KB | - | 1.7 KB |
| 总存储开销 (每核) | 28 KB | 20.75 KB | 31.91 KB | 28.95 KB |
- 通过动态选择高 MPKA 集合,Drishti 显著减少了所需的采样集数量(Hawkeye 从 64 减至 8,Mockingjay 从 32 减至 16),从而大幅缩小了采样缓存。
- 虽然引入了饱和计数器带来额外开销,但净效果是存储节省,分别为 7.25KB 和 2.96KB 每核。
1. Per-Core Yet Global Reuse Predictor¶
核心观点
- Per-Core Yet Global Reuse Predictor 是 Drishti 提出的关键增强之一,旨在解决在 sliced LLC 架构下,传统 per-slice local predictor 因地址散列(address hashing)导致的 myopic behavior (短视行为) 问题。
- 其核心思想是:为每个 core 维护一个独立的重用预测器,但这个预测器是 全局的 (global),即它能接收并学习来自 所有 LLC slices 的访问信息,而非仅限于其物理位置所在的 slice。
实现原理与算法流程
- 预测器实例化:系统为每个核心
i创建一个专属的重用预测器,记为Predictor_i。该预测器通常是一个哈希表或类似结构,其索引键(key)由 PC (Program Counter) 和 core ID 共同构成(例如,hash(PC, core_id)),以区分不同核心发出的相同 PC。 - 预测器部署:
Predictor_i被物理部署在核心i最邻近的 LLC slice 附近,以减少本地访问延迟。 - 训练流程 (Training):
- 当任意一个 LLC slice 的 sampled cache 捕获到一次访问(无论是命中还是未命中)时,该 slice 会提取此次访问的 PC、core ID、block address 以及 hit/miss status。
- 该 slice 随后通过一个专用的低延迟互连(NOCSTAR)将这些信息发送给 对应核心的预测器(即
Predictor_{core_id})。 Predictor_{core_id}接收此信息,并根据具体的替换策略(如 Hawkeye 或 Mockingjay 的规则)更新其内部状态。例如,在 Mockingjay 中,它会更新该(PC, core_id)对应的 Estimated Time of Arrival (ETA) 或 Estimated Time Remaining (ETR) 值。
- 预测流程 (Prediction):
- 当发生 LLC fill(即需要将一个新块插入 LLC)时,请求方核心的 ID 和触发此次 fill 的 load 指令的 PC 已知。
- 系统使用
(PC, core_id)作为键,通过 NOCSTAR 互连查询对应的Predictor_{core_id}。 Predictor_{core_id}返回一个预测值(如 RRIP 值或 ETR 值),该值被用于指导当前 LLC set 的替换决策(例如,决定新块的初始优先级或选择哪个块进行驱逐)。
Figure 9: Drishti's enhancement: Tracking reuse behavior and training the per-core and yet global reuse predictor with local (per-slice) sampled caches.
关键设计考量与参数
- 专用互连 NOCSTAR:这是实现该方案可行性的关键。普通的片上网络(NoC)延迟过高(文中提到平均 20 cycles),会完全抵消预测精度提升带来的性能增益,甚至导致性能下降(见 Figure 11a)。
- NOCSTAR 是一个 side-band, latchless circuit-switched interconnect,专为 slice-to-predictor 通信设计。
- 它提供了极低的固定延迟(3 cycles),足以支撑预测器的高效访问。
- 其带宽需求较低,因为预测器仅在 sampled cache 被访问时才需要通信,频率远低于常规数据流量。
- 流量对比:与一个集中式的全局预测器相比,per-core 设计极大地降低了互连压力。Figure 10 显示,集中式预测器平均每千条指令有 65+ 次访问,而 per-core 设计仅为 2.46 次。
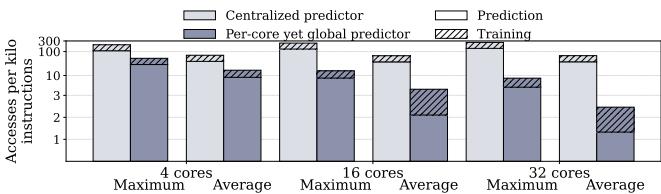
Figure 10: Accesses per kilo instructions to the centralized and per-core global predictors in Mockingjay,averaged across 35 homogeneous and 35 heterogeneous mixes. Each bar shows the training and prediction lookups to the predictor.
输入输出关系及在整体中的作用
- 输入:
- 训练阶段: 来自任意 LLC slice 的 sampled cache 的
(PC, core_id, hit/miss, block_address)元组。 - 预测阶段:
(PC, core_id)对。
- 训练阶段: 来自任意 LLC slice 的 sampled cache 的
- 输出:
- 训练阶段: 无显式输出,内部状态(如 ETR 表或 RRIP 表)被更新。
- 预测阶段: 一个标量预测值(如 RRIP value 或 ETR),用于替换决策。
- 在整体中的作用:
- 解决短视问题: 通过聚合所有 slices 的访问信息,
Predictor_i能够看到核心i发出的所有 loads 的完整访问模式,无论这些 loads 被散列到哪个 slice。这使其预测更接近 global view,显著优于 myopic view(见 Figure 3 和 Figure 4)。 - 提升预测准确性: 更准确的预测直接转化为更优的缓存管理决策,减少了不必要的驱逐和后续的缓存未命中。
- 与 Dynamic Sampled Cache 协同: 该预测器与 Drishti 的第二项增强——Dynamic Sampled Cache(动态选择高 MPKA 的 sets 作为 sampled sets)协同工作。高质量的 sampled sets 为预测器提供了更“干净”、信息量更大的训练数据,进一步提升了预测效果(见 Figure 17)。
- 解决短视问题: 通过聚合所有 slices 的访问信息,
2. Local Per-Slice Sampled Cache¶
Local Per-Slice Sampled Cache 的实现原理与作用
- 基本定义与目的:Local Per-Slice Sampled Cache 是指在 sliced LLC 架构下,每个物理切片(slice)都维护一个独立的、小型的采样缓存。其核心目的是监控并记录流经该切片内特定 sampled sets 的缓存行访问行为(如命中/缺失、重用距离等),为更高层的 reuse predictor 提供训练数据。
- 与全局预测器的协同:该设计的关键在于,虽然采样缓存是本地化的(per-slice),但它所收集的信息并非用于训练本地的、视野狭窄的预测器,而是用于训练一个全局性的 reuse predictor。在 Drishti 中,这个全局预测器被实现为 per-core yet global 的形式,即每个核心拥有一个专属的预测器,但该预测器能接收来自所有 LLC 切片的采样信息,从而获得全局视野。
Figure 9: Drishti's enhancement: Tracking reuse behavior and training the per-core and yet global reuse predictor with local (per-slice) sampled caches.
- 动态采样机制 (Dynamic Sampled Cache):Drishti 对传统的随机选择采样集合的方法进行了革新,提出了 dynamic sampled cache。
- 问题驱动:传统方法随机选择采样集合,但在实际运行中,不同 LLC 集合的 Misses Per Kilo Access (MPKA) 差异巨大(如 Figure 5 所示)。一些集合访问稀疏,无法提供有效的训练信号,导致预测器训练不足。
- 解决方案:Drishti 在每个切片内部,使用一个 k-bit saturating counter 来监控每个 LLC 集合的 MPKA 行为。
- 计数器在 LLC miss 时递增,在 LLC hit 时递减。
- 监控周期为 L = 32K 次加载访问。
- 周期结束后,选择 N 个计数器值最高的集合作为新的采样集合。
- 参数设置:论文通过实验确定,对于 Hawkeye 和 Mockingjay,所需的采样集合数量 N 可以从原来的 64/32 减少到 8/16 per slice,因为动态选择确保了每个采样集合都具有高信息量。
Figure 5: Miss per kilo accesses (MPKA) per LLC set with three different 16-core homogeneous workloads.
- 输入输出关系:
- 输入:来自处理器核心的内存请求(包含 Program Counter (PC)、块地址、请求类型等),这些请求根据地址哈希被路由到特定的 LLC 切片。
- 处理:当一个请求访问到某个切片,并且该请求命中的集合恰好是该切片当前的 sampled set 之一时,该切片的本地采样缓存会记录此次访问的详细信息(PC, hit/miss status, block address, timestamp 等)。
- 输出:采样缓存将处理后的信息(例如,计算出的重用距离或 Belady's 策略下的模拟结果)通过一个专用的低延迟互连 (NOCSTAR) 发送给对应核心的 global reuse predictor,用于更新预测器的状态。
在整体架构中的关键作用
- 解决“Under-utilized Sampled Sets”问题:通过动态选择高 MPKA 的集合,确保了采样缓存接收到足够多的有效缺失事件,从而为预测器提供了高质量、低噪声的训练数据。Table 1 的实验数据证明,仅使用高 MPKA 集合作为采样集,性能可提升 16%,远高于使用低 MPKA 集合的 8.3%。
- 支撑全局预测器的有效性:本地采样缓存是全局预测器的“眼睛”。它负责在数据产生的源头(即各个分散的 LLC 切片)进行初步的数据采集和过滤,使得全局预测器无需直接监控整个庞大的 LLC,从而在保持全局视野的同时,避免了巨大的带宽开销。
- 实现存储效率:由于动态采样机制的高效性,Drishti 能够显著减少每个切片所需的采样缓存大小。如 Table 3 所示,Hawkeye 的采样缓存从 12KB/core 减少到 3KB/core,Mockingjay 从 9.41KB/core 减少到 4.7KB/core。这部分节省的存储空间甚至超过了为实现动态采样而增加的 1.7KB/core 的计数器开销,最终实现了净存储节省。
| Policy | Sampled Cache Size (per core) | Saturating Counters (per core) | Net Storage Change (per core) |
|---|---|---|---|
| Hawkeye (Baseline) | 12 KB | 0 KB | Baseline |
| D-Hawkeye (Drishti) | 3 KB | 1.7 KB | -7.25 KB |
| Mockingjay (Baseline) | 9.41 KB | 0 KB | Baseline |
| D-Mockingjay (Drishti) | 4.7 KB | 1.7 KB | -2.96 KB |
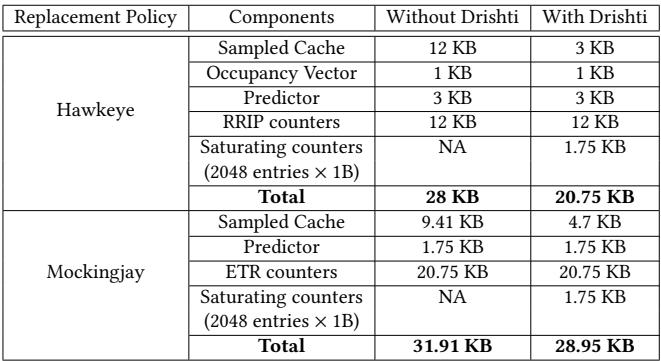
Table 3: Per-core hardware budget with and without Drishti for a 16-way 2MB LLC slice.
3. Dynamic Sampled Cache¶
实现原理与核心思想
- Dynamic Sampled Cache 的核心目标是解决在 sliced LLC 架构下,传统 randomly selected sampled sets 效用不均的问题。由于工作负载的访问模式差异,部分 LLC 集合会经历极高的 Misses Per Kilo Access (MPKA),而另一些则几乎闲置。
- 该机制通过动态监控每个 LLC slice 内所有集合的 capacity demand(以 MPKA 为代理指标),并智能地选择那些高需求的集合作为 sampled cache 的一部分,从而确保采样缓存能捕获到最具信息量的访问行为,用于训练 reuse predictor。
算法流程与关键参数
- 监控阶段 (Monitoring Phase):
- 为 LLC slice 中的每个集合配备一个 k-bit saturating counter。
- 在一个固定的监控周期内(长度为 L = 32K 次 load 访问),每当发生一次 LLC miss 时,对应集合的计数器就递增;当发生一次 LLC hit 时,计数器就递减。这使得计数器的值能够反映该集合的 净失效率。
- 选择阶段 (Selection Phase):
- 监控周期结束后,系统从该 slice 中选择 N 个具有最高饱和计数器值的集合作为新的 sampled sets。
- 对于 Hawkeye,N 被设为 8;对于 Mockingjay,N 被设为 16。这远低于基线策略中使用的 64 和 32,体现了其高效性。
- 自适应与相变处理 (Adaptation & Phase Change Handling):
- 为了适应应用运行时的相变 (Phase Change),整个监控-选择过程每 128K 次 load 访问(即 4 * L)就会重置一次,重新评估并选择新的 sampled sets。
- 系统会检测是否存在 uniform capacity demand 的情况(例如 streaming workload
lbm)。通过比较 slice 内最高和最低计数器值,如果其差值小于一个阈值(100),则判定为均匀访问模式。此时,Dynamic Sampled Cache 会被关闭,退回到传统的随机采样策略,以避免不必要的开销。
输入、输出及在 Drishti 中的作用
- 输入:
- 来自 LLC 的 hit/miss 事件流。
- 每个事件关联的 cache set index。
- 内部状态:
- 每个 LLC set 对应的 k-bit saturating counter (k=8)。
- 当前的 sampled sets 列表。
- 输出:
- 一个动态更新的、由 high-MPKA sets 组成的 sampled cache。
- 这个采样缓存会将捕获到的访问信息(PC, hit/miss status, block address)发送给 per-core global reuse predictor 进行训练。
- 在整体中的作用:
- 提升预测准确性: 通过聚焦于高失效率的集合,采样缓存提供的训练数据噪声更少、信息量更大,从而显著提升了 reuse predictor 的准确性。如 Table 1 所示,在
mcf工作负载上,仅使用高 MPKA 集合就能带来 16% 的性能提升,远超使用低 MPKA 集合(8.3%)。 - 降低硬件开销: 由于采样效率的提高,所需的 sampled sets 数量大幅减少,直接导致 sampled cache 的存储开销下降。如 Table 3 所示,Hawkeye 的采样缓存从 12KB/core 减少到 3KB/core,Mockingjay 从 9.41KB/core 减少到 4.7KB/core。
- 与全局预测器协同: 它与 per-core global reuse predictor 形成完美互补。全局预测器解决了 myopic view 问题,而动态采样缓存则确保了提供给这个全局预测器的数据是最优质的。
- 提升预测准确性: 通过聚焦于高失效率的集合,采样缓存提供的训练数据噪声更少、信息量更大,从而显著提升了 reuse predictor 的准确性。如 Table 1 所示,在
Figure 5: Miss per kilo accesses (MPKA) per LLC set with three different 16-core homogeneous workloads.
硬件开销与参数总结
| 组件 | 参数 | 值 | 说明 |
|---|---|---|---|
| Saturating Counter | 位宽 (k) | 8 bits | 用于记录每个 LLC set 的 MPKA 趋势 |
| 监控窗口 | 长度 (L) | 32K load accesses | 计数器更新的周期 |
| 重置周期 | 长度 | 128K load accesses | 重新选择 sampled sets 的周期 |
| 采样集合数 (N) | Hawkeye | 8 per slice | 动态选择的高 MPKA sets 数量 |
| Mockingjay | 16 per slice | ||
| 均匀访问阈值 | 计数器差值 | 100 | 判断是否关闭动态采样的阈值 |
4. Dedicated Low-Latency Interconnect (NOCSTAR)¶
NOCSTAR互连网络的设计原理与实现
- 核心目标:为了解决在采用per-core yet global reuse predictor(每核全局预测器)架构时,由本地采样缓存(local sampled cache)跨切片访问远端预测器所引入的高延迟和带宽瓶颈问题。
- 根本挑战:在传统的Mesh等片上互连网络中,随着核心数增加(如32核),跨切片通信的平均延迟高达20 cycles。论文图11a明确指出,若不使用低延迟互连,Drishti的性能增益会被完全抵消,甚至在32核系统上导致高达9% 的平均性能下降。
- 解决方案:引入一个名为 NOCSTAR 的专用、轻量级、旁路式(side-band)互连网络,专门用于处理切片(slice)与预测器(predictor)之间的通信。
NOCSTAR的硬件架构与工作流程
- 基础架构:
- 采用无锁存器(latchless)的电路交换(circuit-switched)设计,而非传统的分组交换。
- 在每个LLC切片和每个预测器旁边都部署一个开关(switch),该开关本质上是一个由多路复用器(muxes)组成的集合,起到信号中继的作用。
- 每个开关连接到一个仲裁器(arbiter),用于管理链路的访问请求。
- 通信流程:
- 当某个切片的采样缓存需要更新或查询一个位于远端切片的预测器时,它会通过NOCSTAR发起请求。
- NOCSTAR使用专用的控制线(control wires)来预先建立从源切片到目标预测器的完整通信路径。
- 路径建立后,数据通过该专用路径进行传输,整个过程的延迟被严格控制在3 cycles。
- 为了支持请求(request)和响应/填充(response/fill)路径的并发访问,系统配备了两条专用链路。
- 路由策略:采用简单的 XY routing 策略来确定数据包在网络中的传输路径。
Figure 11: (a) Slowdown in Mockingjay with Drishti without a low-latency interconnect between slices and the predictors. (b)Interconnect latency sensitivity on a 32-core system across 35 homogeneous and 35 heterogeneous mixes.
关键参数与开销分析
- 性能参数:
- 延迟:固定为 3 cycles,与核心数量无关,解决了传统互连延迟随规模扩展而增长的问题。
- 带宽:设计为低带宽,因为预测器的更新仅在访问采样集(sampled sets)时触发,事件频率相对较低,因此低带宽足以满足需求。
- 硬件开销(基于28nm工艺):
- 静态功耗:每个开关消耗 0.4 mW,每个仲裁器消耗 2 mW。与一个2MB LLC切片约 60 mW 的静态功耗相比,可以忽略不计。
- 面积开销:每个开关和仲裁器组合占用 0.005 mm²,远小于一个2MB LLC切片的 1.85 mm²。
- 动态能耗:每次切片到预测器的通信平均仅消耗 50 pJ(其中链路20pJ,开关10pJ,控制线20pJ),开销极低。
在Drishti整体架构中的作用与输入输出关系
- 输入:来自任意LLC切片的采样缓存的预测器访问请求。这些请求包含程序计数器(PC)、核心ID、访问是命中还是未命中等信息,用于训练或查询预测器。
- 处理:NOCSTAR作为一个透明的、低延迟的通信通道,负责将上述请求可靠且快速地路由到位于(可能)不同物理位置的、对应核心的全局预测器。
- 输出:将预测器的响应(例如,预测的重用距离ETR或RRIP值)以同样低的延迟传回发起请求的切片。
- 核心作用:NOCSTAR是Drishti能够成功实施“本地采样缓存 + 每核全局预测器”这一混合架构的关键使能技术。它在不干扰主片上互连网络的前提下,有效解耦了预测器的逻辑全局性与物理分布性之间的矛盾,使得全局预测的准确性得以实现,同时避免了因通信延迟过高而导致的性能损失。没有NOCSTAR,Drishti的性能优势将无法兑现。
4. 实验方法与实验结果¶
实验设置
- 模拟平台与基准:研究基于 ChampSim 跟踪驱动模拟器,该平台被用于 DPC-2 和 DPC-3 等权威竞赛。基线系统配置模仿 Intel Sunny Cove 微架构。
- 工作负载:
- 使用 SPEC CPU 2017 和 GAP 基准套件的公开跟踪文件。
- 精选了 70 个混合工作负载(35 个同构 + 35 个异构),所有工作负载在基线 LRU 策略下均表现出至少 1 MPKI (Misses Per Kilo Instructions) 的 LLC 缺失率,确保其内存密集型特性。
- 评估了不同核心规模:4-core、16-core 和 32-core 系统,并扩展至 64-core 和 128-core 以验证可扩展性。
- 缓存与内存层次:
- LLC 为 切片式 (sliced) 设计,大小分别为 8MB (4核)、32MB (16核) 和 64MB (32核),每个切片为 2MB。
- 使用 next-line prefetcher (L1D) 和 IP-stride prefetcher (L2) 作为基线预取器,并额外评估了 SPP+PPF、Bingo 等五种先进预取器。
- 评估指标:主要采用 归一化加权加速比 (Normalized Weighted Speedup),并辅以 调和平均加速比 (Harmonic Mean of Speedups)、最大个体减速 (Maximum Individual Slowdown) 和 不公平性 (Unfairness) 等指标。
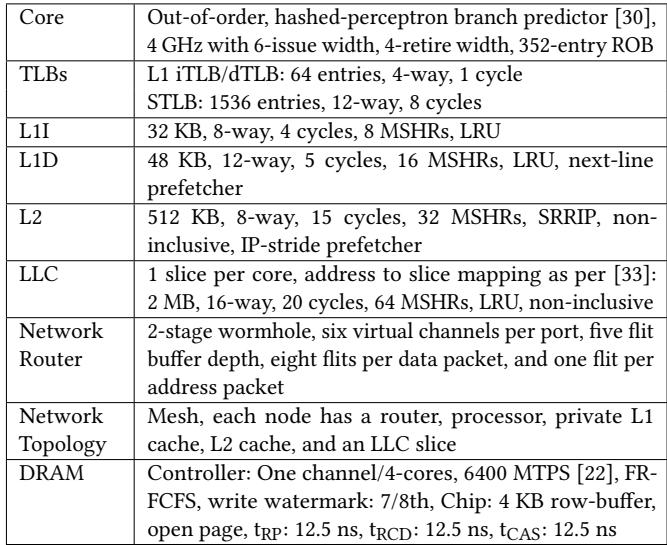
Table 4: Simulation parameters of the baseline system.
结果数据分析
- 性能提升:Drishti 的增强效果随核心数增加而显著放大。
- 在 32-core 系统上,Hawkeye 相对于 LRU 的性能增益从 3.3% 提升至 D-Hawkeye 的 5.6%。
- Mockingjay 的增益则从 6.7% 大幅跃升至 D-Mockingjay 的 13.2%。
- 对于特定工作负载(如
mcf_1554B),D-Mockingjay 的性能提升高达 77%,远超原版 Mockingjay 的 59%。
- 缺失率降低:性能提升直接源于 LLC 缺失的减少。
- 在 32 核系统上,D-Hawkeye 将平均 LLC MPKI 降低了 14.1%,优于 Hawkeye 的 10.6%。
- D-Mockingjay 将平均 LLC MPKI 降低了 24.1%,优于 Mockingjay 的 21.2%。
- 能效与写回:
- D-Mockingjay 在 32 核系统上将 Uncore (LLC, NOC, DRAM) 能量消耗 降低了 9%,优于 Mockingjay 的 5%。
- 尽管 Hawkeye/Mockingjay 系列策略因优先驱逐脏行而增加了 LLC WPKI (Writebacks Per Kilo Instructions),但 Drishti 的增强并未恶化此问题,反而通过减少总缺失间接优化了能效。
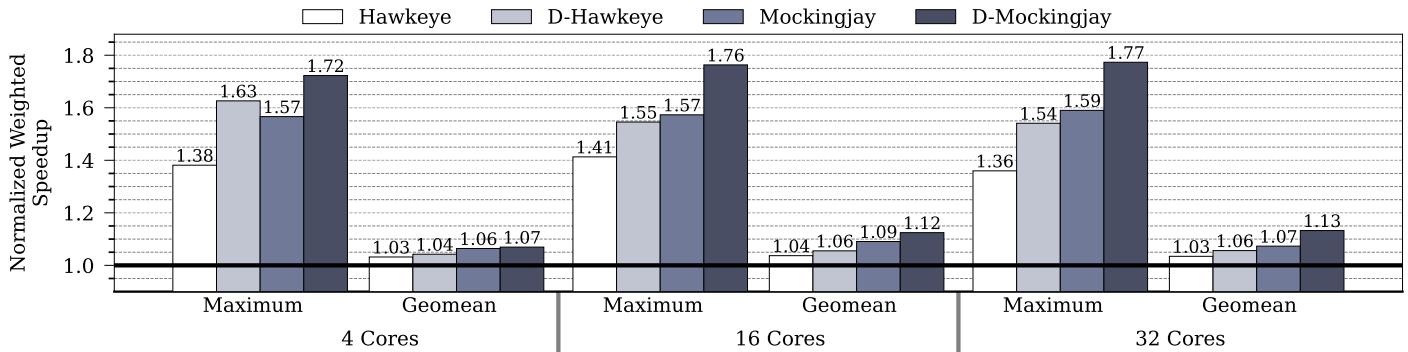
Figure13: Performance improvement with state-of-the-artLLCreplacement policies normalized toLRUon4-core,6-core, 32-core systems with 8MB,32MB,and 64MB sliced LLC across 70 mixes (35 homogeneous and 35 heterogeneous).
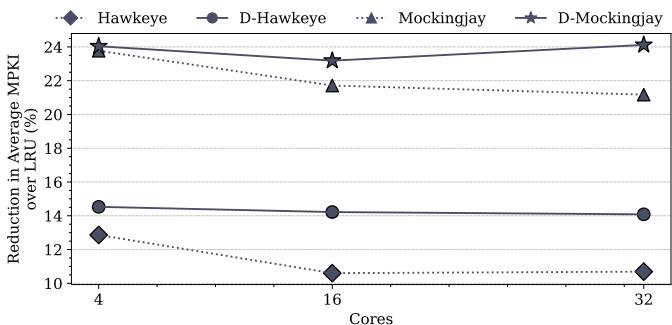
Figure 14: Miss reduction over LRU on 4, 16,and 32 cores averaged across 70 (35 homo.and 35 hetero) mixes.
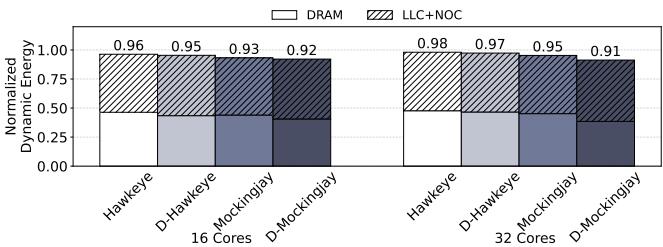
Figure 15: Uncore (LLC, NOC, and DRAM) energy consumption normalized to LRU across 70 mixes (lower the better).
消融实验 (Ablation Study)
论文通过详细的消融实验,分别验证了 Drishti 两大核心增强的有效性。
- 全局预测器 vs. 动态采样缓存:图 17 清晰地分解了两项技术的贡献。
- 仅引入 per-core global predictor(提供全局视图)时,Mockingjay 在 SPEC/GAP 工作负载上的平均加速比从 3.8%/9.7% 提升至 6.0%/15.0%。
- 在此基础上再加入 Dynamic Sampled Cache (DSC) 后,性能进一步提升至 9.7%/16.9%。
- 这表明两项技术相辅相成,共同构成了 Drishti 的核心优势。
Figure 17: Performance normalized to LRU with only global view and D-Mockingjay with global view & DSC across 32- core 35 homogeneous and heterogeneous mixes.
- 不同工作负载下的主导因素:
- 对于
xalancbmk这类受 myopic behavior 影响严重的工作负载(见 Figure 2),全局预测器 是性能提升的主要驱动力。 - 对于
mcf这类具有高度非均匀 MPKA 分布的工作负载(见 Figure 5),动态采样缓存 通过聚焦高缺失率集合,成为性能提升的关键。
- 对于
- 硬件开销与设计选择:
- 消融实验也体现在对不同设计的对比上。例如,使用 centralized global predictor 会产生巨大的互连流量(>65 次访问/千指令),而 per-core global predictor 将此流量降至约 2.46 次/千指令。
- 实验还证明了 NOCSTAR 低延迟互连的必要性。若使用常规片上互连(延迟约20周期),Drishti 的性能增益会被完全抵消,甚至导致 9% 的性能下降。
Figure 10: Accesses per kilo instructions to the centralized and per-core global predictors in Mockingjay,averaged across 35 homogeneous and 35 heterogeneous mixes. Each bar shows the training and prediction lookups to the predictor.
Figure 11: (a) Slowdown in Mockingjay with Drishti without a low-latency interconnect between slices and the predictors. (b)Interconnect latency sensitivity on a 32-core system across 35 homogeneous and 35 heterogeneous mixes.
- 存储开销:Drishti 不仅提升了性能,还节省了存储。
- 由于动态采样缓存能更高效地选择采样集合,所需采样集合数量大幅减少(Hawkeye 从 64 减至 8,Mockingjay 从 32 减至 16)。
- 最终,D-Hawkeye 和 D-Mockingjay 的每核存储开销分别减少了 7.25KB 和 2.96KB。
Table 3: Per-core hardware budget with and without Drishti for a 16-way 2MB LLC slice.