Compress Objects, Not Cache Lines: An Object-Based Compressed Memory Hierarchy 通俗讲解¶
0. 整体创新点通俗解读¶
痛点直击 (The "Why")
- 传统的内存压缩技术(比如 BDI, LCP)都是以 cache line(缓存行,通常是64B或128B的固定块)为单位进行压缩。
- 这套方法在处理科学计算这类以数组为主、数据布局规整的程序时效果很好,因为一个缓存行里的数据往往很相似,内部冗余度高。
- 但在处理面向对象(object-based)的现代应用(如数据库、图计算、Java应用)时就“很难受”了:
- 布局不规整:一个对象内部包含不同类型、不同大小的字段,一个缓存行里可能混杂着好几个不同对象的碎片,导致行内冗余度极低,传统算法压不动。
- 对齐浪费:对象大小是任意的,但压缩系统却强迫它们塞进固定大小的缓存行里,造成大量内部碎片(internal fragmentation)。
- 地址翻译开销:为了找到压缩后的数据在哪,系统需要额外的元数据(metadata)来做地址翻译,这本身又占空间、耗时间。
通俗比方 (The Analogy)
想象你要打包搬家。
- 传统方法就像规定所有东西都必须塞进标准尺寸的纸箱(cache line)里。你有一堆形状各异的物品(objects),比如一个花瓶、几本书、一个台灯。为了塞进箱子,你不得不在花瓶周围塞满泡沫(padding),结果箱子没装满但已经封箱了,非常浪费空间。而且,为了找到你的花瓶,你还得翻查一份厚厚的“物品-箱子”对照表(address translation)。
- 这篇论文的思路是:别管纸箱了,直接按物品本身来打包!花瓶用气泡膜裹好,书用绳子捆起来。每个物品(object)自己就是一个独立的压缩单元。更重要的是,既然你家有很多一模一样的马克杯(同类型的objects),那就只带一个完整的杯子,其他杯子只带和第一个不一样的部分(比如杯柄上的划痕)。这就是跨对象压缩(cross-object compression)的核心思想。
关键一招 (The "How")
作者并没有在传统的缓存/内存架构上打补丁,而是做了一个根本性的范式转换:从 “压缩缓存行” 转向 “压缩对象”。这个转换依赖于两个关键支撑:
-
第一,构建一个面向对象的内存层次结构(Zippads)。
- 它基于一个叫 Hotpads 的前期工作,该工作将内存视为一系列管理可变大小对象的“垫子”(pads),而不是传统的扁平地址空间。
- 在这个体系里,指针(pointer)是硬件可以直接操控的一等公民。当一个对象被移动或压缩时,硬件能自动更新所有指向它的指针,让它们直接指向压缩后的对象。这就彻底绕开了传统压缩方案中复杂的地址翻译问题,消除了元数据开销和间接访问延迟。
-
第二,设计一个专门为对象定制的压缩算法(COCO)。
- COCO洞察到:同一个类(type)。因此,它采用差分编码(differential encoding)策略。
- 对于某一类型的对象,系统会选一个作为基对象(base object)。后续的同类对象,只需要存储一个位图(diff bitmap)和差异字节(byte diffs),指明自己和基对象哪里不一样。
- 为了高效实现,COCO还引入了一个很小的基对象缓存(base object cache),确保解压时能快速拿到基对象,避免频繁访问主存。
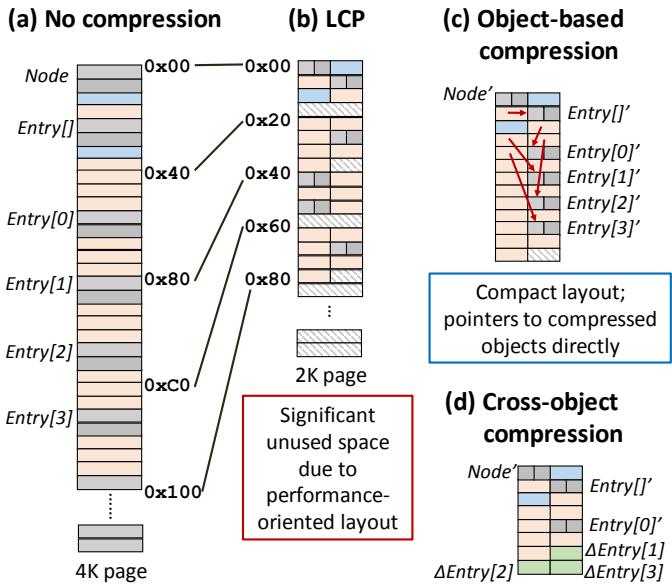 Figure 3. Different compression techniques applied to BTree.
Figure 3. Different compression techniques applied to BTree.
上图清晰地展示了这种思路的威力。传统LCP方案(b)因为对齐和固定块限制,压缩后仍有大量空白。而Zippads(c)将对象紧凑排列,并直接通过指针访问。COCO(d)更进一步,通过共享基对象,将内存占用压得更低。
最终,这套组合拳使得系统在混合负载下,相比最先进的传统压缩方案,实现了1.63倍的平均压缩率提升,56% 的内存流量降低,并带来了17% 的性能提升。
1. Zippads¶
痛点直击 (The "Why")
- 传统的内存压缩(比如 LCP 或 BDI)都是以 cache line(通常是64B)为单位进行的。这在处理科学计算这类数组密集型(array-dominated)程序时效果很好,因为数组元素类型相同、数值相近,一个 cache line 内部冗余度高。
- 但在面向对象(object-based)的程序(如 Java 应用、数据库、图计算)中,情况就完全不同了:
- 对象是可变大小的,很少能完美对齐到 cache line 边界。
- 一个 cache line 里可能混杂着不同对象的字段,这些字段类型各异、数值毫无关联,导致基于 cache line 的压缩算法几乎找不到任何冗余,压缩比极低(论文里提到只有 10% 左右)。
- 更糟的是,为了支持随机访问,传统方案必须维护一个从“逻辑地址”到“压缩后物理地址”的映射表(类似 TLB),这带来了额外的元数据开销和内部碎片(internal fragmentation),进一步侵蚀了本就不高的压缩收益。
通俗比方 (The Analogy)
- 想象你要搬家。传统方法就像是把所有东西都塞进一个个标准尺寸的纸箱(cache line)里,然后压缩每个箱子。但你的家是个杂物间:一个箱子里可能有书、锅、玩具和衣服,这些东西没法互相压缩,所以箱子还是鼓鼓囊囊的。而且你还得记下“原来放在客厅第3块地板下的东西,现在在第7号压缩箱的第2层”,这个清单本身就很占地方。
- Zippads 的做法完全不同。它说:“别管纸箱了,我们直接按‘物品’来打包”。你的书、锅、玩具各自就是一个独立的对象。我们给每件物品单独抽真空压缩,然后把它们紧密地堆在一起,不留空隙。最关键的是,所有指向这件物品的“便签条”(指针),我们直接重写成新位置的地址。这样,你就再也不需要那个又大又麻烦的“纸箱-物品”对照清单了。
关键一招 (The "How")
- Zippads 并没有发明一种新的压缩算法,而是彻底改变了压缩的“粒度”和“寻址方式”。
- 它构建在一个叫 Hotpads 的基于对象的内存层次结构之上。Hotpads 的核心思想是,硬件直接管理可变大小的对象,而不是固定大小的 cache line,并且在对象移动时(比如被垃圾回收或换出到下一级缓存),会自动重写所有指向它的指针。
- Zippads 巧妙地利用了 Hotpads 的这个特性:
- 压缩粒度:当一个对象变得“冷”(不常被访问)并被逐出到下一级(比如 LLC 或主存)时,Zippads 就在这个时机压缩整个对象,而不是等它被填满一个 cache line。
- 消除地址转换:由于 Hotpads 本来就要重写指针,Zippads 就让指针直接指向压缩后的对象。这就完全绕开了传统压缩内存中那个笨重的地址翻译层。
- 指针即元数据:Zippads 把压缩所需的元信息(比如压缩后的大小、使用的算法类型)直接编码在指针本身里(见图
 Figure 11. Zippads pointer format. Compression information is encoded in the pointer.)。因为所有内存访问都始于一个指针,所以硬件在访问时立刻就能知道如何解压,无需额外查询。
Figure 11. Zippads pointer format. Compression information is encoded in the pointer.)。因为所有内存访问都始于一个指针,所以硬件在访问时立刻就能知道如何解压,无需额外查询。
- 这个设计使得 Zippads 能够实现零内部碎片的紧凑存储(见图 Figure 3. Different compression techniques applied to BTree. 中的 c 部分),从而在对象密集型应用上获得了远超传统方案的压缩比(平均 1.63倍)。
2. COCO (Cross-Object COmpression)¶
痛点直击 (The "Why")
- 传统的内存压缩(如 BDI, FPC)都是以 cache line 为单位进行的。这在处理规整的数组(Array)时效果很好,因为一个 cache line 里的数据往往类型相同、数值相近。
- 但在 object-based 的程序(比如 Java 应用)里,情况就完全不同了。一个对象内部的字段五花八门(int, pointer, string...),彼此之间毫无相似性,导致在一个 cache line 内部几乎找不到可以压缩的冗余。
- 更要命的是,对象在内存中的布局是不规则的,经常被 cache line 边界切开。这不仅让压缩算法“巧妇难为无米之炊”,还引入了额外的地址翻译开销和内部碎片,进一步降低了压缩效率。
通俗比方 (The Analogy)
- 想象你有一大堆同款但不同配置的手机。传统压缩方法就像是把每个手机都拆成一堆零件(螺丝、屏幕、电池...),然后试图在这一堆杂乱的零件里找相同的螺丝来压缩。结果发现,每个手机的零件都混在一起,很难找到规律。
- COCO 的思路则完全不同:它先把所有手机按型号分类。对于每一类(比如 iPhone 15),它选出一台作为“base object”(基准机)。然后,对于同一型号的其他手机,它只记录它们和这台基准机的差异。比如,“你的手机比基准机多了个蓝色保护壳”、“他的手机少了根充电线”。这样一来,描述每台新手机所需的信息量就大大减少了。
- 这本质上是一种 “差分编码” (Differential Encoding) 的思想,就像 Git 版本控制系统只存储文件的 diff 而不是完整副本一样。
关键一招 (The "How")
- 作者没有去优化如何压缩单个对象内部的数据,而是巧妙地将压缩的粒度从“对象内部”转移到了“对象之间”。
- 具体来说,COCO 在压缩一个对象时,会执行以下几步:
- 识别类型:通过对象头(通常是第一个 word)获取其 type id。
- 查找基准:根据 type id 找到该类型对应的 base object。论文中采用了一个非常简单有效的策略:第一个被压缩的该类型对象就作为基准。
- 计算差异:逐字节比较当前对象和 base object,生成一个 diff bitmap(一个 bit 代表一个 byte 是否不同)和一个 byte diffs(所有不同的字节值组成的序列)。
- 存储差异:最终,压缩后的对象只包含三部分:base object id、diff bitmap 和 byte diffs。
- 为了高效实现,COCO 还设计了一个小型的 base object cache(8KB),用来缓存最常用的基准对象,避免每次压缩/解压都要去主存读取基准,从而保证了低延迟。
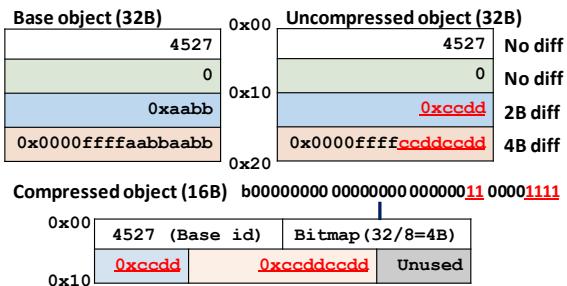 Figure 13. Example COCO-compressed object. 展示了这个压缩格式的直观例子。
Figure 13. Example COCO-compressed object. 展示了这个压缩格式的直观例子。
3. Hotpads 集成¶
痛点直击 (The "Why")
- 传统的内存压缩(比如 LCP、BDI)都是以 cache line 为单位进行的。这在处理科学计算这类 array-dominated 的程序时效果很好,因为数据是规整、同质的。
- 但在 object-based 程序(如 Java 应用)里,这种做法就“很难受”了:
- 布局错位:一个对象可能横跨多个 cache line,而一个 cache line 里又塞满了不同对象的字段。压缩算法只能看到“碎片”,看不到完整的对象,自然找不到规律。
- 地址翻译开销:压缩后数据大小不一,必须维护一张额外的映射表(类似 TLB),把逻辑地址翻译成物理的压缩块地址。这要么增加延迟,要么浪费空间(内部碎片)。
- 冗余利用不足:同一个类的多个对象,内容高度相似(比如数据库里的很多 Entry 对象),但传统算法只在单个 cache line 内找冗余,完全错过了这个“金矿”。
通俗比方 (The Analogy)
- 想象你要整理一个杂乱的仓库。传统方法是把仓库切成一个个固定大小的格子(cache line),然后对每个格子单独打包压缩。结果就是,一个完整的工具箱被切开放在了三个格子里,每个格子还混着其他杂物,根本没法有效压缩。
- Hotpads 的思路完全不同:它要求仓库管理员(硬件)知道每一件物品(object)的边界和类型。管理员直接按“物品”来管理,把整个工具箱当作一个整体搬来搬去。
- Zippads 就是在这个新式仓库里工作的压缩专家。他不仅按“物品”打包,还会发现:“嘿,仓库里有100个几乎一样的锤子!我只需要存一把‘标准锤’,其他99把只记录跟标准锤不一样的地方就行了。” 这就是 COCO 算法的精髓。
关键一招 (The "How")
-
作者并没有从零开始设计一套全新的压缩硬件,而是巧妙地将压缩功能 嫁接 到了 Hotpads 这个已有的、革命性的内存层次结构上。具体来说,他们利用了 Hotpads 的三个核心机制:
-
指针重写 (Pointer Rewriting):
- 在 Hotpads 中,当一个对象从 L1 pad 被移动到 L2 pad 时,所有指向它的指针都会被硬件自动更新,直接指向它在 L2 的新地址。
- Zippads 直接利用了这一点。当一个对象被压缩并存入主存时,它的“新地址”就是压缩后的地址。通过指针重写,所有访问都直接指向压缩数据,彻底绕开了传统压缩方案中那个麻烦的“地址翻译层”。
-
集合-驱逐 (Collection-Eviction, CE) 过程:
- Hotpads 的 CE 过程就像一个高效的垃圾回收器,它会遍历整个 pad,找出活对象、死对象,并将活对象紧凑地挪到一起。
- Zippads 将压缩操作融入了 CE 流程。当一个对象在 CE 过程中被决定要驱逐到下一级(比如主存)时,Zippads 就在此刻对其进行压缩。这使得压缩成为一个“批处理”操作,开销被完美分摊。
-
对象流 (Object Flow):
- Hotpads 的对象有一个“canonical level”(规范层级)的概念,即对象当前所在的最底层存储位置。
- Zippads 规定只有到达特定层级(如最后一级 pad 或主存)的对象才会被压缩。对象在生命周期早期(在 L1/L2)是未压缩的,保证了快速访问;只有当它们变“冷”并下沉时,才被压缩以节省空间。这种 “冷热分离” 的策略非常优雅。
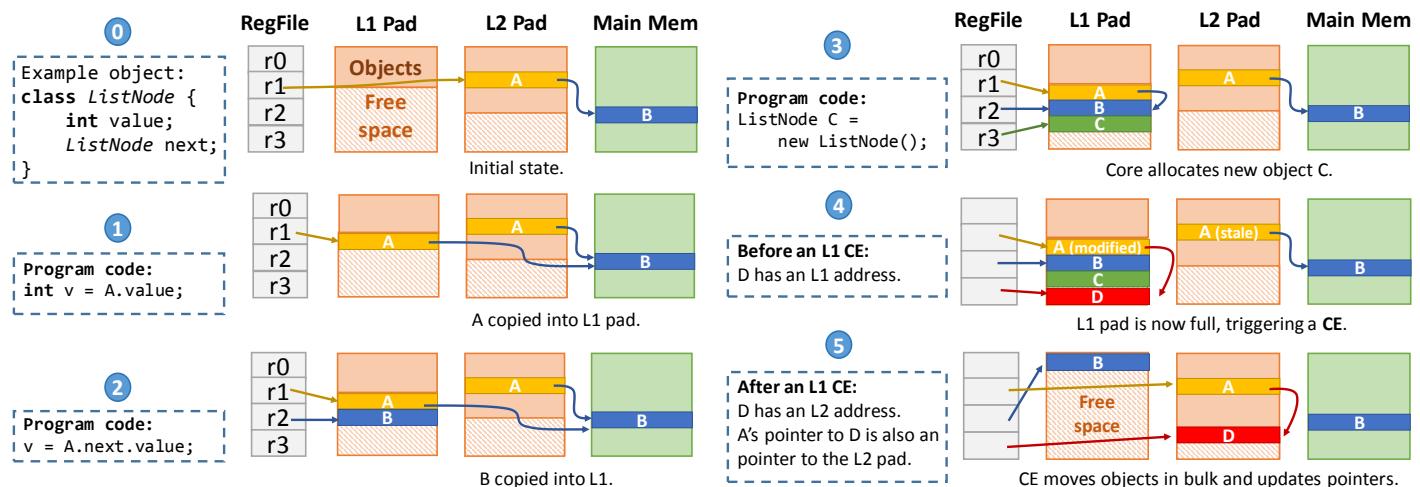 Figure 4. Example showing Hotpads’s main features.
Figure 4. Example showing Hotpads’s main features.
- 上图清晰地展示了 Hotpads 的工作流程。Zippads 的压缩逻辑就嵌入在这个流程中:在步骤
4的 CE 过程中,当对象 A 和 D 被决定要驱逐到 L2 时,Zippads 会对它们进行压缩,并在步骤5中将指针直接重写为指向 L2 中的 压缩版本。整个过程对软件完全透明,且没有额外的地址翻译开销。
4. 指针内嵌压缩元数据¶
痛点直击 (The "Why")
- 传统的压缩内存系统(比如 LCP、VSC)面临一个根本性的两难困境:硬件需要知道压缩数据的大小和用的什么算法才能正确解压,但这些元数据放哪里?
- 如果把这些信息放在独立的元数据表或缓存标签里,就会引入额外的访问开销。每次读取压缩数据前,都得先查一次元数据表,这在延迟敏感的路径上是致命的。
- 更糟糕的是,在主内存这种没有缓存标签(Tag)的地方,这个问题无解。你无法像在 Cache 里那样把元数据塞进 Tag,只能用更笨重的方案,比如为每个压缩块维护一个庞大的地址翻译表,这又带来了巨大的存储开销和内部碎片。
通俗比方 (The Analogy)
- 想象你要寄一个包裹。传统做法是,你把包裹(压缩数据)和一张单独的说明单(元数据)交给邮局。邮局必须先找到并读取这张说明单,才知道这个包裹有多重、该怎么拆封。如果说明单丢了或者找起来很麻烦,整个流程就卡住了。
- Zippads 的做法是,直接把所有关键信息——重量、尺寸、拆封方式——印在包裹的快递单上(也就是指针本身)。快递员(硬件)拿到快递单的一瞬间,就知道一切所需信息,可以立刻高效地处理包裹,完全不需要再去翻找另一张纸。
关键一招 (The "How")
- 作者敏锐地抓住了 Hotpads 架构的一个核心特性:指针对软件是不透明的(opaque)。这意味着硬件可以完全控制指针的内部格式,而不用担心破坏用户程序。
- 利用这个自由度,他们没有去设计复杂的外部元数据结构,而是直接改造了指针的二进制布局。如图 Figure 11. Zippads pointer format. Compression information is encoded in the pointer. 所示,他们在原有的指针中“偷”出几个比特位:
- 原本的 size 字段现在存储的是压缩后的对象大小。
- 新增了几个 algorithm-specific bits 来标识使用了哪种压缩算法(比如是 BDI+FPC 还是 COCO)。
- 这个改动看似微小,却完成了关键的逻辑转换:将“先查元数据再取数据”的串行操作,变成了“取指针即得元数据”的一步到位操作。因为所有内存访问都始于一个指针,所以硬件在解引用指针的瞬间,就已经拥有了执行解压所需的全部上下文信息,彻底绕开了传统方案的性能瓶颈。
5. 大对象分块处理¶
痛点直击 (The "Why")
- 传统的压缩内存系统以 cache line(通常是64B)为单位进行压缩。这在处理小对象时问题不大,但当程序分配一个大对象(比如1KB的数组或复杂结构体)时,这套机制就“很难受”了。
- 最核心的痛点是:访问局部性与解压开销的矛盾。程序很可能只需要读写这个大对象里的某一个字段或元素,但为了拿到这8个字节,系统却不得不把整个1KB的对象从主存中取出、解压,再丢进缓存。这个高延迟和带宽浪费在性能敏感的场景下是不可接受的。
- 此外,如果大对象被频繁修改,每次写回都可能因为压缩后大小变化而触发昂贵的重定位(relocation)和指针更新操作,进一步拖慢系统。
通俗比方 (The Analogy)
- 想象你要从一个巨大的、被真空压缩袋封起来的羽绒被里拿一个小枕头。传统做法是,你必须把整个压缩袋拆开,让整床被子恢复原状,然后才能找到并拿出那个小枕头。这显然效率极低。
- Zippads的做法更像是,一开始就没把整床被子塞进一个袋子,而是把它拆成了几个独立的小被子(子对象),每个都用自己独立的压缩袋装好,并且有一个目录索引(index array)告诉你哪个小被子在哪个袋子里。现在,你只需要根据目录找到对应的小袋子,拆开它,就能立刻拿到你的小枕头,完全不用管其他部分。
关键一招 (The "How")
- 作者并没有沿用“整个对象一体压缩”的思路,而是巧妙地在对象分配和访问的流程中,插入了一个分块抽象层。
- 具体来说,当分配一个超过阈值(128B)的大对象时:
- 系统不会立即为其分配完整的物理空间,而是先创建一个轻量级的 index array(索引数组)。
- 这个索引数组的每个条目都是一个指针,初始状态为 null。
- 只有当程序首次访问该大对象的某个特定区域(比如偏移72字节处)时,系统才会:
- 动态分配一个标准大小(64B)的 subobject(子对象)。
- 将该子对象的地址填入索引数组对应的槽位。
- 后续对该区域的所有访问,都会通过索引数组间接路由到这个独立的子对象上。
- 这样一来,压缩、解压、移动的操作粒度就从“整个大对象”降级到了“64B的子对象”。访问局部性得到了完美保留,避免了为访问少量数据而付出全局解压的高昂代价。同时,由于子对象是独立管理的,单个子对象的溢出(overflow)也不会影响整个大对象的稳定性。
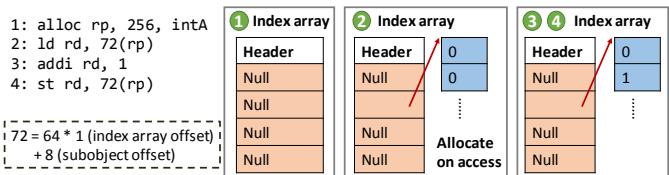 Figure 12. Zippads breaks large objects into subobjects.
Figure 12. Zippads breaks large objects into subobjects.