Charon: Specialized Near-Memory Processing Architecture for Clearing Dead Objects in Memory 通俗讲解¶
0. 整体创新点通俗解读¶
痛点直击 (The "Why")
- 传统的 **Garbage Collection **(GC) 是个“吃力不讨好”的活儿。它对程序员很友好,能自动回收内存,但在处理 big data analytics 这类内存密集型应用时,性能开销巨大。
- 核心问题在于,GC 的工作模式(比如遍历对象图、大量拷贝内存)与 通用CPU 的设计哲学完全相悖。CPU 擅长计算密集、有良好局部性的任务,而 GC 是典型的 memory-intensive 且 locality-poor 的工作负载。
- 即便你用多核并行,最终也会被 off-chip memory bandwidth bottleneck 卡住脖子。论文数据显示,在某些场景下,GC 耗时甚至超过实际计算时间的 365%,这简直是灾难。
- 过去的硬件加速方案要么太死板(hard-wired 算法),要么改动太大(侵入式修改CPU),要么只解决了部分问题,没触及带宽这个根本瓶颈。
通俗比方 (The Analogy)
想象一下,你要清理一个巨大仓库(内存)里的垃圾。传统做法是,派几个工人(CPU核心)进去,他们需要不断地跑回办公室(CPU缓存)拿清单、记笔记,然后再跑回仓库深处找东西。仓库太大,他们大部分时间都在路上奔波(等待内存数据),效率极低。
Charon 的思路是:别让工人来回跑了!直接在仓库的每个分区里(3D-stacked DRAM 的 logic layer)设立一个小型、专业的清理站。当总部(Host CPU)发现某个区域需要清理时,它只需发个指令:“3号仓库区,执行‘Copy’操作,从A货架搬到B货架”。3号区的清理站就地取材,利用仓库内部超宽的通道(abundant internal bandwidth of HMC/TSV),瞬间完成大批量搬运,效率自然飙升。
关键一招 (The "How")
作者没有试图用硬件重写整个复杂的 GC 算法,而是做了一件非常聪明的事:精准外科手术式地识别并卸载最关键的几个“Primitive”(原语)。
- 第一步:精准定位。通过对 HotSpot JVM 的深度剖析,他们发现无论 MinorGC 还是 MajorGC,超过 75% 的时间都花在 Copy, Search, Scan&Push, Bitmap Count 这几个简单操作上。这些操作逻辑简单,但数据搬运量巨大。
- 第二步:近内存部署。他们将针对这几个原语的专用硬件单元(Specialized Processing Unit)直接部署在 **3D-stacked DRAM **(如HMC) 的逻辑层中。这使得这些单元能绕过狭窄的 CPU-内存总线,直接享用 DRAM 内部的海量带宽。
- 第三步:极致并行。这些专用单元被设计成能**最大化 Memory-Level Parallelism **(MLP)。例如,
Copy单元可以一次性发出大量 256B 的读请求,几乎打满内部带宽;Bitmap Count单元则用一个巧妙的位运算算法(CountSetBits(begMap-endMap) + CountSetBits(begMap))替代了原始软件中逐 bit 扫描的低效循环。
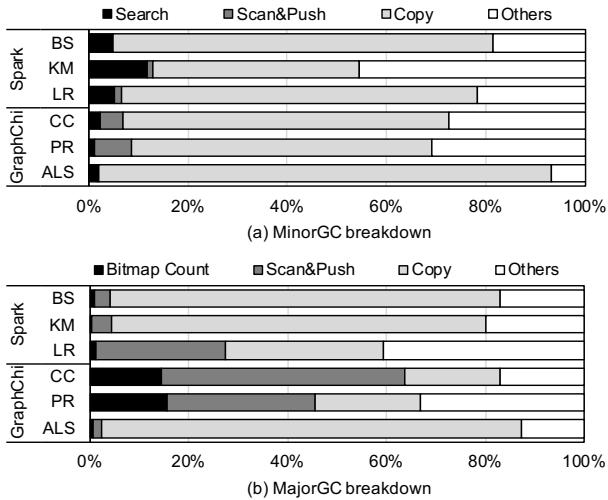 Figure 4: Runtime breakdown of GC
Figure 4: Runtime breakdown of GC
最终,这种“识别热点原语 + 近内存专用硬件加速”的组合拳,以极小的硬件代价(仅占 HMC 逻辑层 0.49% 的面积),换来了 3.29倍的 GC 速度提升 和 60.7% 的能耗节省,完美地解决了困扰 GC 数十年的带宽瓶颈问题。
1. 关键GC原语识别¶
痛点直击
- 以前的硬件GC加速器总想“一口吃成胖子”,要么为特定语言(如Lisp)定制,要么试图把整个GC流程都搬到硬件上。这导致它们灵活性极差,面对像HotSpot JVM里复杂多变的Generational GC(分代垃圾回收)就束手无策。
- 更根本的问题是,GC的本质是一场内存带宽消耗战。它要做大量的、几乎没有局部性的内存读写(比如遍历散落在各处的对象、拷贝大块数据)。通用CPU的Memory-Level Parallelism (MLP) 有限,且被off-chip memory bandwidth bottleneck(片外内存带宽瓶颈)死死卡住,导致其运行GC时IPC(每周期指令数),效率极低。
- 因此,之前的方案要么覆盖场景太窄,要么成本太高,要么没解决带宽这个核心瓶颈,最终都难以落地。
通俗比方
- 想象一个大型废品回收站(堆内存),每天要处理海量垃圾(对象)。传统做法是派一群工人(CPU核心)开着小货车(有限的内存带宽)在巨大的场地里跑来跑去,先检查哪些是可回收的(标记),再把它们搬到指定区域(拷贝/整理)。
- 这个过程最耗时的不是“判断”本身,而是来回搬运和地毯式搜索。Charon的做法很聪明:它不在中央办公室(CPU)指挥,而是在废品站的每个大型仓库(3D堆叠DRAM的逻辑层)里直接部署了几个高度专业化的机器人。
- 这些机器人只干几件最累、最重复的活:Copy(大力搬运工)、Search(快速扫描仪)、Scan&Push(智能分拣员)和Bitmap Count(精算师)。中央办公室只需要下个简单指令,剩下的脏活累活就由本地机器人利用仓库内部的超宽通道(TSV高带宽)高效完成。
关键一招
- 作者没有试图重新发明GC算法,也没有构建一个全能的硬件GC引擎。他们的核心洞察在于:通过细致剖析真实世界(HotSpot JVM)。这意味着,只需用很小的硬件代价,就能撬动最大的性能收益。
- 具体来说,他们将GC流程拆解,并通过Profiling发现,无论是Minor GC还是Major GC,超过75%的时间都花在了Copy、Search、Scan&Push和Bitmap Count这几个原语上(见图4)。
Figure 4: Runtime breakdown of GC
- 于是,Charon的设计策略就是“精准打击”:为这四个原语分别设计专用的、能极致压榨3D DRAM内部带宽的硬件单元。
- 对于Copy和Search这种“尴尬并行”的任务,硬件单元以256B(HMC最大粒度)疯狂发起读请求,最大化MLP。
- 对于Bitmap Count,他们甚至重新设计了算法,将其转化为高效的位计数操作(CountSetBits),并辅以专用的bitmap cache来加速。
- 对于Scan&Push这种有间接访存依赖的操作,硬件单元会预取所有待扫描的引用,然后批量处理,避免了CPU因长延迟依赖而停顿。
- 这种“卸载关键原语而非整个GC”的思路,使得Charon既能获得接近专用硬件的性能,又保持了对不同GC算法的良好兼容性和低侵入性(仅需修改JVM约37行代码)。
2. 近内存专用处理单元¶
痛点直击
- 传统的垃圾回收(GC)跑在通用CPU上,效率极低。根本原因在于GC的核心操作(比如拷贝大对象、扫描引用链)是极度内存密集型的,但通用CPU的设计哲学是“计算密集”,它有两大短板:
- 内存级并行度(MLP)严重不足:CPU的Load/Store Queue和指令窗口大小有限,无法同时发出足够多的内存请求来喂饱内存总线。
- 被外部内存带宽扼住咽喉:即使CPU能发出很多请求,数据还是要通过狭窄的内存通道(如DDR4)从远处的DRAM芯片搬过来,这成了无法逾越的瓶颈。
- 结果就是,现代CPU在执行GC时,IPC(每周期指令数)常常低于0.5,大部分时间都在干等内存数据,算力被严重浪费。
通俗比方
- 想象一下,你要清理一个巨大的仓库(堆内存)。传统做法是,你(CPU)站在办公室(处理器核心)里,不停地打电话(发内存请求)给仓库管理员(内存控制器),让他把一个个箱子(缓存行)从仓库深处搬出来给你检查。这个过程慢得要死,因为:
- 你一次只能打几个电话(MLP低)。
- 仓库和办公室之间只有一条窄路(内存带宽低),管理员搬箱子的速度远远跟不上你打电话的速度。
- Charon的做法完全不同:它直接在仓库内部(3D堆叠DRAM的逻辑层)雇佣了一支专业的、高度自动化的清洁小队(专用处理单元)。这支小队就驻扎在货物(数据)旁边,他们之间有超宽的内部通道(TSV高带宽),可以瞬间搬运大量货物,并且能同时处理成百上千个箱子(超高MLP)。你只需要在办公室下个指令(offload request),剩下的脏活累活就全交给这支高效的小队了。
关键一招
- 作者没有试图用硬件去实现整个复杂的GC算法(那样会非常僵化且成本高昂),而是做了一件极其聪明的事:精准识别并剥离出最耗时的几个“原语”(Primitives),然后为每个原语量身定制一个微型加速器。
- 具体来说,他们在HMC的逻辑层里塞进了三种专用处理单元,每种都针对其任务做了极致优化:
- Copy/Search单元:对付大块内存拷贝和区域搜索。它一接到任务,就以256B(HMC最大粒度)为单位,像机关枪一样疯狂地向本地DRAM发起读请求,最大化利用内部带宽。
- Bitmap Count单元:用于计算存活对象大小。它没有傻乎乎地逐位扫描,而是采用了一个巧妙的位运算算法(
CountSetBits(begMap-endMap) + CountSetBits(begMap)),将复杂的遍历问题转化为高效的批量位操作,并辅以一个专用的bitmap cache来消除冗余读取。 - Scan&Push单元:负责图遍历。它预先知道一个对象里有多少个引用,于是一次性把所有引用地址的读请求全部发出去(Batching),而不是像CPU那样一个接一个地等。这极大地隐藏了内存延迟,提升了MLP。
- 这套组合拳的核心思想就是:在哪里产生数据,就在哪里处理数据。通过将计算单元下沉到数据所在的3D堆叠内存内部,彻底绕开了传统冯·诺依曼架构的“内存墙”问题。最终,这套方案仅用1.95mm²的微小面积开销,就换来了3.29倍的GC速度提升和**60.7%**的能耗节省。
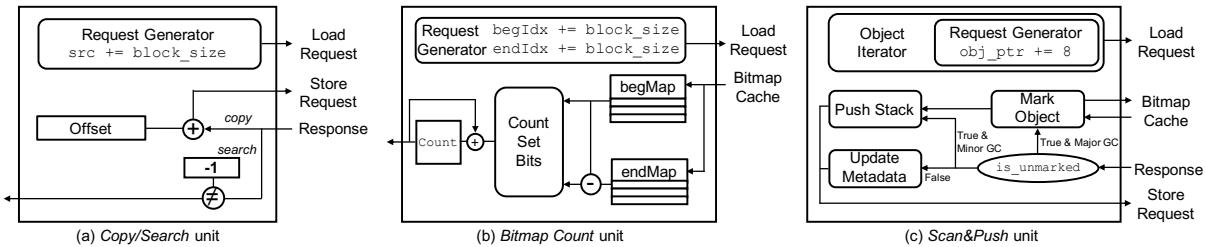 Figure 5: Charon overview Figure 6: Hardware block diagram of each processing unit
Figure 5: Charon overview Figure 6: Hardware block diagram of each processing unit
3. 位图缓存(Bitmap Cache)¶
痛点直击 (The "Why")
- 传统的垃圾回收(GC)在处理 Bitmap Count 和 mark_obj 操作时,会频繁地从主存中读取位图(bitmap)数据。
- 这些操作有两个致命问题:
- 时间局部性好但被浪费了:GC 在压缩(compaction)阶段会反复扫描相邻或重叠的位图区域,但每次访问都直接穿透缓存去主存拿,白白浪费了这种重复访问的特性。
- 过度取数据(overfetching):位图操作(如
mark_obj)通常只需要修改一个 bit,但内存系统的最小访问粒度是 64B 或 128B。这意味着为了改一个 bit,要先读回一整块数据,造成巨大的带宽浪费和延迟。
通俗比方 (The Analogy)
- 想象你是一个图书管理员(GC),需要在一排超长的书架(堆内存)上给书贴标签(标记存活对象)。你的记录本(位图)非常大,摊在地上。
- 以前的做法是:每当你需要查或改一个标签,你都必须跑回档案室(主存)把包含那个标签的整整一页记录(cache line)拿回来。即使你接下来马上要处理旁边几个标签,你也得一次次来回跑。
- 位图缓存 就相当于你在手边放了一个小夹子(8KB cache),把最近正在处理的那几页记录本夹在上面。这样,你处理完这个区域前,就再也不用跑档案室了,效率自然飙升。
关键一招 (The "How")
- 作者并没有改变 GC 算法本身,而是在近内存处理器(Charon)的逻辑层里,为位图访问专门开辟了一块私有、小型的写回缓存。
- 这个设计的精妙之处在于它精准地抓住了两个操作的互补性:
- Bitmap Count 发生在 MajorGC 的 compacting phase,是只读操作。
- mark_obj(属于 Scan&Push 单元)发生在 MajorGC 的 marking phase,是读-改-写操作。
- 因为这两个阶段不会同时发生,所以这块缓存可以被它们安全地复用,无需复杂的并发控制。
- 具体流程被扭转为:
- 当 Bitmap Count 单元需要读取位图时,先查这个专用缓存。由于其访问具有极强的时间局部性(论文提到 hit rate 高达 90%),绝大多数请求都能在缓存中命中,从而隐藏了主存访问的长延迟。
- 当 Scan&Push 单元执行
mark_obj时,它不再直接发起一个会导致 overfetching 的主存 RMW(Read-Modify-Write)请求,而是先将所需的数据块加载到这个缓存中,在缓存里完成修改,最后再以完整的 cache line 粒度写回。这从根本上解决了 overfetching 问题。
- 为了保证与主机 CPU 的一致性,系统会在每个 GC 阶段(marking 或 compacting)结束后主动 flush 这个缓存,确保数据最终落盘。 Figure 5: Charon overview Figure 6: Hardware block diagram of each processing unit
4. 位图计数优化算法¶
痛点直击
- 传统的 Bitmap Count 原语在软件里干的是个“苦力活”:它需要从头到尾,一个比特一个比特地扫描两个巨大的位图(
begMap和endMap),来计算某个内存范围内所有存活对象的总大小。 - 这种逐位迭代的方式,在硬件上执行起来效率极低。想象一下,你要数清一整片森林里有多少棵树,却只能一棵一棵地走过去点名,这在处理 16GB 甚至更大的堆内存时,会成为 MajorGC 阶段的一个巨大瓶颈。
通俗比方
- 这就像你有一长串由
0和1组成的密码锁(begMap表示对象开始,endMap表示对象结束)。传统方法是,你从第一个数字开始,一直拨到最后一个,记录下每一对1之间的距离。 - 而 Charon 的新算法则像一个聪明的数学家。他不一个个数,而是把整个
begMap看作一个二进制大数,把endMap也看作一个二进制大数,然后直接做一次减法。这个减法的结果会神奇地“标记”出所有对象占据的区间,你只需要数一数结果里有多少个1,再稍微修正一下,就能立刻得到答案。 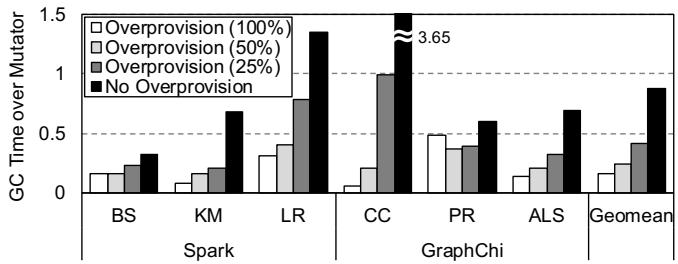 Figure 2: GC overhead normalized to mutator time (for useful work) in big data processing workloads over varying heap size
Figure 2: GC overhead normalized to mutator time (for useful work) in big data processing workloads over varying heap size Figure 10: Example of object traversal
Figure 10: Example of object traversal
关键一招
- 作者没有去优化那个缓慢的循环,而是从根本上扭转了问题的解法。他们发现,存活对象的总字数可以通过一个精妙的数学等价转换来计算:
- 核心公式:
CountSetBits(begMap - endMap) + CountSetBits(begMap)
- 核心公式:
- 这个公式的巧妙之处在于:
begMap - endMap这个操作,在二进制层面会产生一个结果,其中1的数量恰好等于所有对象内部(不含起始位)的1的总数。- 但是,每个对象的起始位(
begMap中的1)在这个减法中被“借位”消耗掉了,所以我们需要额外加上CountSetBits(begMap)来把它们补回来。
- 通过这个转换,原本需要 O(n) 次迭代(n 是位图的比特数)的复杂操作,被简化成了两次大规模并行的位计数操作(Population Count)和一次向量减法。这些操作在专用硬件上可以被极度优化,从而实现了 5.63倍 的平均加速。
5. 主机-Charon接口与系统集成¶
痛点直击
- 以前的硬件GC加速器之所以没普及,核心问题在于“侵入性太强”。它们要么要求CPU架构大改(比如加专用指令),要么要求JVM重写一大块逻辑。这在工业级软件(如HotSpot JVM)里是不可接受的,因为验证和维护成本太高。
- 另一个隐藏痛点是虚拟内存管理。近存计算单元(Charon)在DRAM侧,它看到的是物理地址,但JVM操作的是虚拟地址。如果每次访问都要通过复杂的页表遍历,性能优势就没了,而且多进程隔离也成问题。
通俗比方
- 这就像你想给家里的老式中央空调加装一个智能新风系统。最笨的办法是砸墙、重铺管道、甚至换掉主机(侵入性强)。而Charon的做法是:只在空调的出风口接一个标准化的快插接口(那两个内联函数),新风系统自己搞定内部循环,完全不用动你家原有的复杂管线。至于地址转换问题,就好比物业(操作系统)提前给你家(JVM进程)分配了一整层楼(1GB huge pages)并锁死(mlock()),这样你的房间号(虚拟地址)和实际物理位置(物理地址)就是一一对应的,新风系统查个简单的楼层平面图(小TLB)就能直达,不用每次都去问物业前台。
关键一招
- 作者没有试图让Charon接管整个GC流程,而是精准地找到了几个可以“外包”的原子化任务(Copy, Search等)。为了让这个“外包”过程丝滑,他们做了两件极其聪明的事:
- 极简的API设计:只暴露
initialize()和offload()两个内联函数。initialize()一次性告诉Charon堆和位图在哪(相当于签合同),offload()则像发快递单一样,把任务类型、源/目的地址打包扔过去。这使得集成成本极低,仅需修改37行JVM代码。 - 利用OS特性简化地址翻译:强制JVM用huge pages分配整个堆,并用mlock()将其锁定在物理内存。这样一来,虚拟地址到物理地址的映射变得极其简单且稳定,Charon侧只需要一个很小的duplicate TLB就能覆盖全部堆空间,彻底规避了传统页表遍历的开销和复杂性。这本质上是将软件的灵活性(虚拟内存)与硬件的效率(物理直访)通过系统级协作完美结合。
- 极简的API设计:只暴露
Figure 4: Runtime breakdown of GC