Branch Prediction and the Performance of Interpreters – Don’t Trust Folklore 论文解析¶
0. 论文基本信息¶
作者 (Authors): Erven Rohou, Bharath Narasimha Swamy, Andre Seznec
发表期刊/会议 (Journal/Conference): CGO
发表年份 (Publication Year): 2015
研究机构 (Affiliations): Inria, France
1. 摘要¶
目的
- 重新审视关于解释器性能的“民间传说”(folklore),即认为解释器主循环中的间接分支(indirect branch)由于高误预测率(high misprediction rate)是导致其性能低下的主要原因。
- 评估在现代处理器(特别是Intel近三代架构:Nehalem, Sandy Bridge, Haswell)和先进分支预测器(如ITTAGE)上,该间接分支对解释器性能的实际影响是否依然关键。
方法
- 实验平台:在真实的Nehalem、Sandy Bridge和Haswell处理器上,使用硬件性能计数器(PMU)收集分支预测数据。
- 模拟验证:通过Pin工具生成执行轨迹,并在TAGE/ITTAGE(当前文献中最先进的条件/间接分支预测器)上进行模拟,以对比真实硬件与理想预测器的表现。
- 研究对象:选取三种主流语言的switch-based解释器(无jump threading优化)作为基准:Python、**Javascript **(SpiderMonkey) 和 **CLI **(.NET)。
- 核心指标:主要使用**MPKI **(Mispredictions Per Kilo Instructions),即每千条指令的分支误预测次数,来衡量分支预测开销。
结果
- 分支预测准确率大幅提升:在Haswell架构上,解释器的整体分支误预测率(MPKI)已从Nehalem时代的12-20 MPKI显著下降至0.5-2 MPKI的极低水平。
- 现代硬件与先进预测器表现相当:Haswell处理器上的实测MPKI与TAGE+ITTAGE模拟器的结果处于同一数量级,表明现代硬件的间接分支预测能力已非常强大。
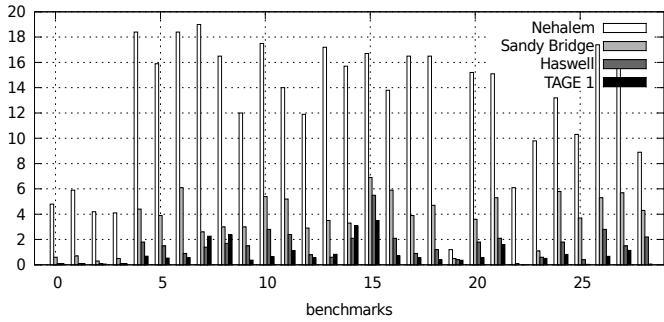 Figure 4. Python MPKI for all predictors
Figure 4. Python MPKI for all predictors
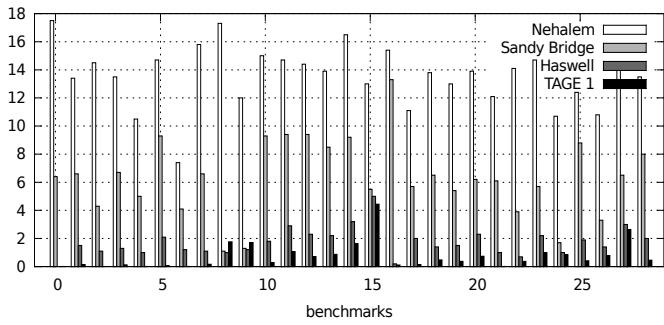 Figure 5. Javascript MPKI for all predictors
Figure 5. Javascript MPKI for all predictors
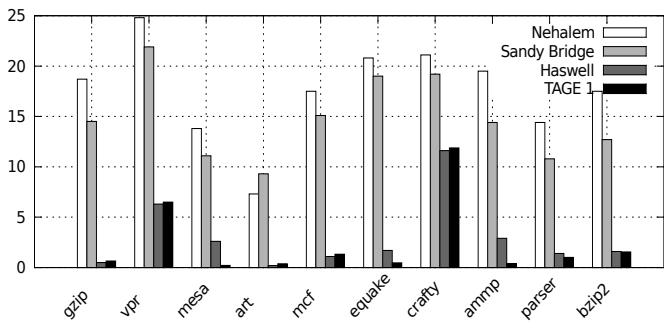 Figure 6. CLI MPKI for all predictors
Figure 6. CLI MPKI for all predictors - Jump Threading优化收益递减:在Nehalem上,jump threading能带来约10.1%的平均性能提升,但在Haswell上该收益已降至仅2.8%,证明其重要性随硬件进步而减弱。
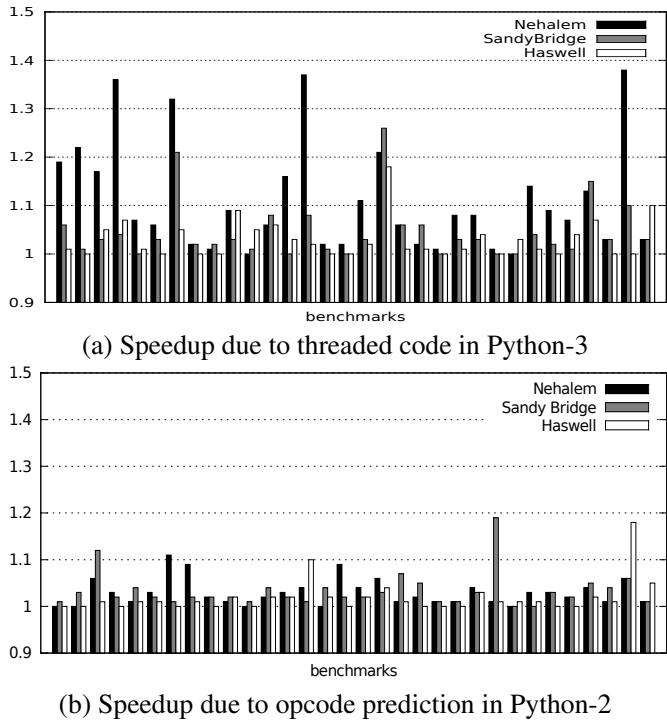 Figure 3. Speedups in Python
Figure 3. Speedups in Python - “难以预测”的分支并非固有难题:仿真结果显示,解释器主循环中的间接分支本身并非天生不可预测。当使用足够大的ITTAGE预测器(如50KB)时,其预测准确率可以变得非常高。过去预测不佳主要是因为预测器资源(footprint)不足,而非模式本身随机。
- 前端瓶颈转移:在Haswell上,由分支误预测导致的前端流水线槽浪费(wasted issue slots)平均仅为7.8%,远低于Sandy Bridge的14.5%,确认了分支预测已不再是主要性能瓶颈。
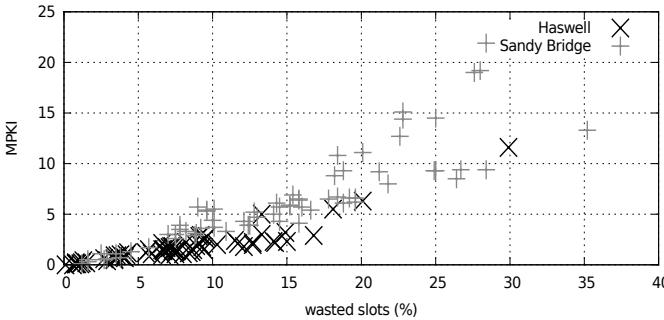 Figure 7. Correlation between MPKI and lost slots
Figure 7. Correlation between MPKI and lost slots
结论
- 推翻传统认知:对于现代处理器(如Haswell)和当前主流解释器(Python, Javascript, CLI),间接分支的预测准确率已不再是影响性能的关键因素。将解释器慢的原因主要归咎于“难以预测的间接跳转”这一民间传说已经过时。
- 硬件演进的影响:分支预测技术的巨大进步是导致这一现象的根本原因,使得软件层面为优化间接分支预测而采用的复杂技术(如jump threading)的收益大幅降低。
- 未来优化方向:解释器的性能优化工作应更多地关注其他方面,例如减少每条字节码所需的原生指令数、优化求值栈的内存访问以及改进动态类型检查等,而非过度关注分支预测问题。
2. 背景知识与核心贡献¶
研究背景
- Interpreters(解释器)因其portability(可移植性)和开发便捷性被广泛应用,尤其是在Python、Javascript和R等动态语言中,但其性能远低于JIT(Just-In-Time)编译。
- 解释器的核心是一个dispatch loop(分发循环),通常通过一个大型的
switch语句实现,该语句在底层会被编译为一个indirect branch(间接跳转)指令。 - Folklore(传统观点/业界共识)认为,这个间接跳转由于目标地址众多且难以预测,会导致high misprediction rate(高误预测率),从而在现代深度流水线处理器上造成严重的performance penalty(性能惩罚),这在过去(如Core2时代)的研究中已被证实。
研究动机
- 过去十年间,branch predictor(分支预测器)技术取得了巨大进步,尤其是Intel的Nehalem、Sandy Bridge到Haswell等微架构。
- 作者质疑:在当前最先进的处理器上,上述关于间接跳转是解释器性能瓶颈的“folklore”是否依然成立?
- 现有解释器(如Python、Javascript)普遍实现了jump threading(跳转线索化)等复杂优化来规避间接跳转,如果该问题已不复存在,则这些优化的必要性值得重新评估。
核心贡献
- 颠覆性发现:通过在Nehalem、Sandy Bridge和Haswell处理器上使用hardware performance counters(硬件性能计数器)进行实测,并结合ITTAGE(state-of-the-art indirect branch predictor)的模拟,证明了indirect branch prediction accuracy is no longer critical for interpreters。
- 关键数据:解释器执行时的global branch misprediction rate(全局分支误预测率)从Nehalem上的 12-20 MPKI(每千条指令的误预测数)大幅下降到Haswell上的 0.5-2 MPKI。
- 性能影响分析:Haswell处理器上的分支预测性能与文献中的顶级预测器ITTAGE相当,表明现代硬件已能有效处理解释器的间接跳转模式。
- 对优化策略的启示:Jump threading等旨在改善间接跳转预测的优化技术,在现代硬件上的收益已显著降低(例如,在Python上,从Nehalem的平均10.1%速度提升降至Haswell的2.8%),部分收益甚至源于减少了指令数而非改善了预测。
- 根本原因探究:现代TAGE/ITTAGE类预测器能够利用long global history(长全局历史)有效捕捉字节码序列中的repetitive patterns(重复模式),从而准确“预测”下一个opcode(操作码),使得主间接跳转变得高度可预测。
Figure 3. Speedups in Python
| 微架构 | Python-3 Jump Threading 平均加速比 | Python-2 Pair Threading 平均加速比 |
|---|---|---|
| Nehalem | 10.1% | 2.8% |
| Sandy Bridge | 4.2% | 3.2% |
| Haswell | 2.8% | 1.8% |
3. 核心技术和实现细节¶
0. 技术架构概览¶
研究目标与核心论点
- 本文旨在挑战并验证一个在解释器性能优化领域长期存在的folklore(传统观念):即,基于
switch语句实现的解释器主循环中的间接分支(indirect branch) 指令因其高误预测率(high misprediction rate) 而成为性能瓶颈。 - 核心论点是,在现代处理器(特别是 Intel Haswell 及之后的架构)和先进的分支预测器(如 ITTAGE)上,该间接分支的预测准确率已大幅提升,其对整体性能的影响已不再是关键问题。
实验方法论与技术栈
- 硬件平台:在三代 Intel 处理器上进行真实硬件测量,分别是 Nehalem、Sandy Bridge 和 Haswell。通过 PMU (Performance Monitoring Unit) 收集硬件性能计数器数据。
- 软件模拟:使用 Pin 工具生成指令执行轨迹,并在模拟器中运行最先进的分支预测器模型 TAGE/ITTAGE,以评估理论上的预测上限。
- 一致性验证:通过对比 PMU 和 Pin 的测量结果(如指令数、指令混合比例),确认两种方法的数据具有高度一致性,保证了实验结论的可靠性。
- 测试对象:选取了三种主流语言的解释器作为研究对象:
- Python (版本 3.3.2)
- Javascript (SpiderMonkey 1.8.5,禁用 JIT)
- **CLI **(Common Language Infrastructure)
关键发现与数据分析
- 误预测率(MPKI)
- 在 Nehalem 上,解释器的全局分支误预测率高达 12-20 MPKI。
- 在 Sandy Bridge 上,该指标显著下降。
- 在 Haswell 上,误预测率进一步降至 0.5-2 MPKI 的极低水平。
- ITTAGE 模拟器的结果与 Haswell 的实测结果处于同一数量级,表明 Haswell 的硬件预测器性能已接近学术界的先进水平。
| 微架构 | 典型 MPKI 范围 | 性能影响 |
|---|---|---|
| Nehalem | 12 - 20 | 重大瓶颈 |
| Sandy Bridge | 4 - 8 | 显著改善 |
| Haswell | 0.5 - 2 | 影响微小 |
- 跳转线程(Jump Threading)
- 实验复现了 jump threading(利用 GCC 的 "Labels as Values" 扩展)优化。
- 结果显示,该优化带来的性能提升随微架构代际递减:在 Nehalem 上平均提升 10.1%,在 Haswell 上仅剩 2.8%。
- 这证明了分支预测的改进是性能差距缩小的主要原因,而非其他因素。
Figure 3. Speedups in Python
- “难以预测”分支的再审视
- 通过模拟器追踪特定分支指令,发现主循环中的间接跳转本身在现代预测器下并非天生不可预测。
- 预测失败的案例(如 CLI 解释器在
vpr和crafty基准上)主要是因为解释器的巨大操作码空间(如 CLI 有 478 个 opcode)导致了预测器资源(footprint)。当使用更大容量的 ITTAGE(如 50KB)时,预测准确率得以恢复。
整体架构总结
- 本文构建了一个横跨硬件、模拟器和真实软件栈的综合性分析框架。
- 通过对比不同代际的商业处理器与前沿的学术预测器模型,系统性地证伪了关于解释器间接分支开销过大的传统观点。
- 其技术架构的核心在于利用硬件性能计数器和精确的模拟作为“显微镜”,深入剖析现代 CPU 微架构与解释器工作负载之间的真实交互,从而为解释器设计和优化提供了基于实证的新方向。
1. Indirect Branch Prediction with ITTAGE¶
ITTAGE 间接分支预测器的核心原理
- ITTAGE (Indirect TAgged GEometric history length) 是从 TAGE 条件分支预测器衍生而来的state-of-the-art间接分支预测器。
- 其核心思想是利用全局历史信息(Global History)来预测间接跳转的完整目标地址(complete target),而非仅仅预测方向。
- 它通过一组部分标记的预测表(partially tagged predictor tables)来实现,这些表的关键特性在于其索引方式:
- 每个表使用不同长度的全局分支历史进行索引。
- 这些历史长度构成一个几何级数(geometric series),例如 4, 8, 16, 32... 这样可以高效地覆盖从短到极长的相关性模式。
- 预测时,系统会并行查询所有表格。最终的预测结果由历史长度最长且命中(hitting)的表格提供。这种机制使其能够捕捉跨越数百甚至数千条指令的复杂、长距离相关性。
在解释器场景下的工作流程与作用
- 在基于 switch 的解释器中,主循环包含一个间接跳转(indirect jump),该跳转的目标地址由当前 opcode 决定。
- ITTAGE 将这个间接跳转视为一个需要预测的目标。其输入是全局历史寄存器(GHR),该寄存器记录了最近执行过的分支(包括条件和间接分支)的历史。
- 对于解释器而言,这个全局历史在很大程度上等同于最近执行的 opcode 序列。因此,一个特定的 opcode 历史序列(如
load, load, add)就构成了一个独特的“签名”。 - ITTAGE 利用这个“签名”作为索引,在其表格中查找下一个最可能的跳转目标(即下一个 opcode 的处理代码地址)。
- 输出是预测的目标地址。如果预测正确,处理器流水线可以无缝地继续取指和执行,避免了因分支误预测(misprediction)导致的流水线冲刷和性能惩罚。
- 在整体系统中,ITTAGE 的作用是极大地降低解释器主循环中关键间接跳转的误预测率,从而将原本被认为是主要性能瓶颈的因素变得不再重要。
论文中的参数设置与实验配置
论文在模拟实验中使用了两种 ITTAGE 配置,以评估不同资源预算下的性能。其参数设置如下:
| 组件 | TAGE1 配置 | TAGE2 配置 |
|---|---|---|
| TAGE (条件分支预测器) | 8 KB | 8 KB |
| ITTAGE (间接分支预测器) | 12.62 KB | 6.31 KB |
- 为了进一步验证预测器容量(footprint)对性能的影响,论文还引入了 TAGE3 配置,其 ITTAGE 大小为 50 KB。
- 实验发现,对于像 CLI 这样拥有 478 个不同 opcode 的解释器,较小的 ITTAGE(如 6.31 KB 或 12.62 KB)在某些基准测试(如
vpr,crafty)上表现不佳,误预测率较高。 - 而当使用 50 KB 的 ITTAGE 时,这些基准的误预测率显著下降,证明了预测器容量不足是导致性能不佳的原因,而非 ITTAGE 算法本身无法处理解释器的分支模式。
关键结论与数据支撑
- 论文通过硬件计数器和模拟,展示了现代处理器(特别是 Haswell)的间接分支预测精度已经非常高。
- MPKI(Mispredictions Per Kilo Instructions)是衡量预测精度的关键指标。在 Nehalem 上,解释器的 MPKI 高达 12-20,而在 Haswell 上则降至 0.5-2。
- ITTAGE 模拟的结果与 Haswell 的实测结果处于同一数量级,这表明 Haswell 内部很可能采用了类似 ITTAGE 的先进预测技术。
- Figure 4. Python MPKI for all predictors
- Figure 5. Javascript MPKI for all predictors
- Figure 6. CLI MPKI for all predictors
- 论文最终得出结论:“hard to predict” 分支的民间说法(folklore)已经过时。只要拥有足够大的高效间接跳转预测器(如 ITTAGE),解释器主循环中的间接分支实际上是高度可预测的。
2. Switch-Based Interpreter Dispatch Loop¶
核心实现原理与算法流程
- Switch-Based Interpreter 的核心是一个无限循环,其主逻辑是通过一个巨大的 C 语言 switch 语句来实现的。该循环负责 fetch(取指)、decode(译码) 和 execute(执行) 三个步骤。
- 在 fetch 阶段,解释器从 virtual program counter (vpc) 指向的内存位置读取下一个 bytecode(字节码),并递增 vpc。
- 在 decode 阶段,读取到的 opcode(操作码,即 bytecode 的数值)被用作 switch 语句的条件变量。
- 编译器(如 GCC, icc, LLVM)在处理这种大型 switch 时,通常会将其优化为一个 jump table(跳转表)。这个跳转表是一个地址数组,每个索引对应一个 opcode,存储着该 opcode 对应处理代码块(payload)的入口地址。
- 执行流程最终会通过一条 indirect jump instruction(间接跳转指令) 跳转到 jump table 中指定的地址,从而执行相应的 payload 代码。
- Payload 执行完毕后,控制流会回到循环顶部,开始下一次迭代。
 Figure 1. Main loop of naive interpreter
Figure 1. Main loop of naive interpreter
关键特性与性能开销
- 主要开销来源:整个 dispatch loop(分派循环) 是解释器性能瓶颈的主要来源。论文测量表明,仅分派循环本身在 x86 上就需要大约 10 条 native instructions(原生指令)。
- 间接跳转的“传统”问题:该间接跳转指令有数百个潜在目标(每个 opcode 对应一个),folklore(传统观点) 认为其 branch misprediction rate(分支误预测率) 极高,在旧式处理器上会带来约 20 cycle penalty(周期惩罚)。
- 次要开销:在访问 jump table 前,编译器通常会生成两条指令来检查 opcode 是否在有效范围内。但由于解释器的正确性保证了 opcode 总是有效的,这个边界检查分支很容易被预测,开销很小。
- 数据访问开销:操作数通常从内存中的 evaluation stack(求值栈) 中加载,结果也存回栈中,这比 JIT 编译代码直接使用寄存器要慢得多。
现代硬件上的性能演变
- 论文的核心发现是,随着 state-of-the-art branch predictors(先进分支预测器) 的发展,间接跳转的预测问题在现代处理器上已大大缓解。
- 通过在 Nehalem、Sandy Bridge 和 Haswell 三代 Intel 处理器上进行实验,全局分支误预测率(MPKI, Mispredictions Per Kilo Instructions)从 Nehalem 上的 12-20 MPKI 剧降至 Haswell 上的 0.5-2 MPKI。
- 这意味着分支误预测带来的性能损失已从主要因素变为次要因素。
| Microarchitecture | Avg. Python Speedup from Threading | Global Misprediction Rate (MPKI) |
|---|---|---|
| Nehalem | 10.1% | 12 - 20 |
| Sandy Bridge | 4.2% | 4 - 8 |
| Haswell | 2.8% | 0.5 - 2 |
与先进预测器 ITTAGE 的对比
- 论文还使用了文献中的 state-of-the-art indirect branch predictor ITTAGE 进行模拟。
- ITTAGE 能够利用长距离的全局历史信息来预测间接跳转的目标,在运行解释器时,其预测准确率与 Haswell 硬件实测结果处于同一量级。
- 这表明 Haswell 的硬件间接分支预测器已经非常强大,能够有效处理解释器 dispatch loop 中的模式。
- 在少数预测不佳的案例中(如 CLI 解释器的
vpr和crafty基准测试),模拟显示这是因为解释器的 footprint(足迹) 过大,超出了较小 ITTAGE 表的容量。增大 ITTAGE 的大小可以显著改善预测准确率,证明问题在于资源限制而非预测方案本身。
在整体系统中的作用
- 输入:Bytecode stream(字节码流),由前端编译器或解析器生成。
- 输出:程序的执行效果,通过操作 evaluation stack 和与外部环境交互来体现。
- 作用:作为解释器的核心引擎,它提供了一种简单、可移植的方式来执行高级语言。虽然牺牲了性能,但其实现简单、易于调试和移植的特性使其在许多场景(如科学计算、嵌入式系统、动态语言)中仍然不可或缺。该分派循环的设计直接决定了基础解释执行的效率上限。
3. Jump Threading (Token Threading)¶
核心原理与实现机制
- Jump Threading(在文中特指 Token Threading)是一种用于优化解释器 dispatch loop(分发循环)的软件技术。
- 其核心思想是绕过传统的、基于
switch语句的分发机制。传统switch会被编译器翻译成一个包含间接跳转(indirect jump)指令的跳转表,该指令因目标地址多变而难以预测。 - 该技术依赖于 GNU C 扩展 'Labels as Values',此扩展允许将代码标签(label)的地址作为值存储在变量中,并通过
goto *variable进行间接跳转。 - 在实现上,每个字节码(bytecode)操作码(opcode)的处理代码块末尾,不再无条件地跳回主循环顶部,而是直接获取并跳转到下一个待执行字节码对应的处理代码块入口。
- 如图所示,
NEXT()宏被定义为goto *next_instr++,其中next_instr是一个指向标签地址数组(oplabels)的指针。这实现了从一个 opcode 的 payload 直接“线程化”到下一个 opcode 的 payload。
 Figure 2. Token threading, using a GNU extension
Figure 2. Token threading, using a GNU extension
算法流程与输入输出关系
- 输入:一个由字节码组成的程序流。
- 初始化:
- 构建一个静态的
oplabels数组,该数组的每个元素是对应 opcode 处理代码块入口标签的地址。 - 将解释器的虚拟程序计数器(virtual program counter, vpc)或等效的指令指针初始化为程序入口。
- 构建一个静态的
- 主执行循环(已内联到各 opcode 末尾):
- Fetch(取指):从当前指令指针位置读取下一个 opcode。
- Decode & Dispatch(解码与分发):使用该 opcode 作为索引,从
oplabels数组中取出目标地址,并通过goto *address直接跳转。
- 输出:字节码程序的执行结果,其语义与传统 switch-based 解释器完全一致。
- 在整体中的作用:它重构了控制流,将一个中心化的、高扇出的间接分支,替换为一系列分布式的、通常具有更高局部性和可预测性的直接跳转,从而成为解释器性能的关键优化点。
性能优势与量化分析
- 减少分支误预测(Mispredictions):通过将一个难以预测的间接跳转分解为多个更容易预测的跳转(因为相邻字节码间存在强相关性,如
compare后常跟branch),显著降低了分支预测失败率。 - 降低指令开销(Instruction Count):直接跳转到下一个 payload 避免了每次循环迭代都需执行完整的 dispatch loop 开销(如重新加载 opcode、访问跳转表等)。论文测量表明,在 Python-3 上,该技术平均减少了 3.3% 的指令数。
- 性能提升随硬件演进而减弱:由于现代处理器(如 Haswell)的间接分支预测器(如 ITTAGE)已变得极为强大,Jump Threading 带来的性能增益已大幅缩小。论文数据显示,其在 Nehalem 上的平均加速比为 10.1%,而在 Haswell 上仅为 2.8%。
| 微架构 (Microarchitecture) | Python-3 平均加速比 | Python-2 平均加速比 |
|---|---|---|
| Nehalem | 10.1% | 2.8% |
| Sandy Bridge | 4.2% | 3.2% |
| Haswell | 2.8% | 1.8% |
Figure 3. Speedups in Python
工程实践与局限性
- 非标准 C 特性:依赖 GNU 'Labels as Values' 扩展,牺牲了 ANSI C 的可移植性。解释器(如 Python, Javascript)通常会通过
#ifdef提供两套实现(threaded 和 switch-based),根据编译器支持情况自动选择。 - 代码复杂性增加:双实现策略导致源代码臃肿,并且需要禁用某些编译器优化(如全局公共子表达式消除、cross-jumping),以防破坏精心设计的控制流。
- 收益递减:随着硬件分支预测能力的飞速发展,这项曾被视为关键的优化技术,其重要性已显著降低。论文的核心结论之一就是,在现代处理器上,间接分支预测的准确性已不再是解释器性能的瓶颈。
4. Hardware Performance Counter Analysis¶
硬件性能计数器分析的实现原理与流程
- 该研究利用 Intel 处理器内置的 PMU (Performance Monitoring Unit) 来收集真实硬件上的性能数据。
- 实验覆盖了三代 Intel 微架构:Nehalem、Sandy Bridge 和 Haswell,以追踪分支预测技术的演进对解释器性能的影响。
- 数据收集工具为 Tiptop,它能从 PMU 中读取特定的硬件事件计数器。
- 为确保测量纯净,实验在空闲工作站上进行,并且 仅收集用户态 (user-land) 事件,排除了内核活动的干扰。
关键性能指标与数据收集
- 核心度量指标是 MPKI (Mispredictions Per Kilo Instructions),即每千条已执行指令中的分支误预测次数。这是一个能直观反映分支预测惩罚的指标。
- PMU 提供了以下关键事件计数器:
- cycles: CPU 周期数。
- retired instructions: 已执行(退休)的指令数。
- retired branch instructions: 已执行的分支指令数。
- mispredicted branch instructions: 被误预测的分支指令数。
- 一个主要挑战是,Intel PMU 没有直接提供“已执行的间接跳转”计数器。研究者使用了名为 “speculative and retired indirect branches” 的计数器作为代理。
- 研究通过理论和实证确认了该代理计数器的有效性:
- 理论下限:已执行的间接分支数 ≥ 执行的字节码数 (
nbytecodes)。 - 理论上限:已执行的间接分支数 ≤ 投机性间接分支计数器的值 (
nspeculative)。 - 在绝大多数情况下,
nspeculative / nbytecodes的比值非常接近 1,证明非退休的间接分支可以忽略不计。 - 对于少数例外情况,研究者使用 Pin 工具进行动态插桩计数,验证了 PMU 计数器的准确性。
- 理论下限:已执行的间接分支数 ≥ 执行的字节码数 (
输入输出关系及在整体研究中的作用
- 输入: 运行在目标处理器(Nehalem/SB/Haswell)上的解释器程序(Python, Javascript, CLI)及其基准测试套件。
- 处理: Tiptop 工具在程序运行期间,通过 PMU 持续累加上述硬件事件。
- 输出: 一组精确的硬件事件计数,用于计算 MPKI、IPC (Instructions Per Cycle) 等关键性能指标。
- 核心作用:
- 提供真实世界基线: PMU 数据代表了在商用最新硬件上解释器的实际运行状况,是验证“传统观点”(即间接跳转难以预测)是否过时的最直接证据。
- 量化代际改进: 通过对比三代处理器的 MPKI 数据,清晰地展示了分支预测准确率的巨大提升。数据显示,MPKI 从 Nehalem 上的 12-20 范围急剧下降到 Haswell 上的 0.5-2 范围。
- 验证模拟器结果: PMU 收集的真实数据被用来与 ITTAGE 分支预测器的模拟结果进行对比,以证明模拟的有效性和结论的普适性。
与其他方法的协同与一致性验证
- 为了确保 PMU 测量结果与基于 Pin 的模拟结果具有可比性,研究者进行了严谨的一致性检查。
- 潜在的差异来源包括:PMU 的非确定性、
rep指令的计数差异、内核事件、以及 Pin 加载时的额外开销(如符号重定位)。 - 通过配置 PMU 也只统计用户态事件,并对比两者报告的指令数和指令混合比例,研究发现差异均在 1% 以内,证明了两种方法的数据是高度一致的。
- 此外,研究还利用 pmu-tools 提供的前端流水线槽浪费模型,将 MPKI 与实际的 wasted issue slots 关联起来,进一步证实了分支误预测是前端性能损失的主要原因,并且 Haswell 因其优秀的预测器,其槽浪费率(7.8%)比 Sandy Bridge(14.5%)降低了近一半。
Figure 4. Python MPKI for all predictors
Figure 5. Javascript MPKI for all predictors
Figure 6. CLI MPKI for all predictors
Figure 7. Correlation between MPKI and lost slots
5. Pin-based Trace Simulation¶
Pin-based Trace Simulation 的实现原理与流程
- 论文采用 Pin(一个动态二进制插桩框架)来生成程序执行的详细指令轨迹(execution trace)。
- 该轨迹捕获了用户态(user-mode)下所有指令的执行流,特别是所有 branch instructions(分支指令)的地址、类型(conditional/indirect)和结果(taken/not-taken, target address)。
- 这些轨迹被用作离线 simulator 的输入,该模拟器实现了 TAGE(用于条件分支预测)和 ITTAGE(用于间接分支预测)的精确模型。
- 模拟器遍历轨迹中的每条分支指令,利用其内部的预测器状态(如历史寄存器、预测表)进行预测,并将预测结果与轨迹中记录的真实结果进行比较,从而计算出 misprediction rate(误预测率)。
参数设置与配置
- 论文使用了两种不同的 (TAGE+ITTAGE) 配置来进行模拟,以评估不同硬件资源预算下的性能:
- TAGE1: 8 KB TAGE + 12.62 KB ITTAGE
- TAGE2: 8 KB TAGE + 6.31 KB ITTAGE
- 这些配置的详细参数在论文的 Table 2 中给出,包括历史长度、表项数量等关键设计指标。
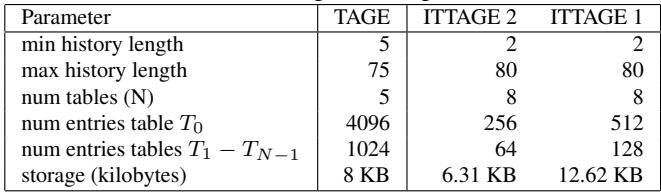 Table 2. Branch predictor parameters
Table 2. Branch predictor parameters
输入输出关系及在整体研究中的作用
- 输入: 由 Pin 工具从真实运行的 interpreter(Python, Javascript, CLI)上采集的完整用户态指令执行轨迹。
- 输出: 在给定 TAGE/ITTAGE 配置下,对每个 benchmark 的 MPKI(Mispredictions Per Kilo Instructions,每千条指令的误预测次数)等性能指标。
- 核心作用:
- 验证硬件测量: 通过将 Haswell 硬件实测的 MPKI 与 TAGE+ITTAGE 模拟结果进行对比(见 Figures 4, 5, 6),证明了现代处理器(如 Haswell)的间接分支预测器性能已经非常接近学术界最先进的 ITTAGE 设计,从而支撑了论文的核心论点——“间接跳转不再是一个主要性能瓶颈”。
- 探索理想化场景: 硬件性能计数器(PMU)无法提供对特定分支指令(如 dispatch loop 中的间接跳转)的独立分析。而基于 Pin 的模拟允许作者深入分析这些“folklore”中被认为难以预测的特定分支(见 Section 5.3 和 Table 6),揭示了其可预测性实际上取决于预测器的 footprint(资源占用)是否足够大。
- 解耦分析: 通过控制模拟器中的预测器配置(如 TAGE1 vs TAGE2 vs TAGE3 with 50KB ITTAGE),可以清晰地分离出 predictor size 对性能的影响,这在真实硬件上是无法做到的。
与硬件测量的一致性保障
- 作者在 Section 4.2.3 中专门论证了 Pin 轨迹与 PMU(Performance Monitoring Unit)硬件计数器数据的一致性。
- 他们通过多种手段确保了两种方法的可比性:
- 将 PMU 配置为仅收集 user-land events,以匹配 Pin 的行为。
- 量化了 kernel-mode 事件、non-determinism 以及 Pin 自身开销带来的影响,确认这些因素造成的指令计数差异均在 1% 以内。
- 这种严谨的校准保证了模拟结果能够有效地补充和解释硬件实验数据。
4. 实验方法与实验结果¶
实验设置
- 研究对象: 论文聚焦于三种主流的 switch-based interpreters(无 jump threading 优化),分别用于 Python (3.3.2)、Javascript (SpiderMonkey 1.8.5) 和 Common Language Infrastructure (CLI)。
- 基准测试集:
- Python: 使用 Unladen Swallow 基准套件(排除了部分不兼容项)。
- Javascript: 使用 Google Octane (2014年2月版) 和 Mozilla Kraken 套件。
- CLI: 使用 SPEC 2000 的 train 输入集子集(因编译器限制,排除了部分基准)。
- 硬件平台: 在三款真实的 Intel 处理器上进行测量:Nehalem、Sandy Bridge 和 Haswell。使用 Tiptop 工具通过 PMU (Performance Monitoring Unit) 收集性能计数器数据,包括周期、指令数、分支指令数和分支误预测(mispredicted branches)数。
- 模拟平台: 为了与硬件结果对比并探究前沿预测器的性能,使用 Pin 工具生成执行轨迹,并在模拟器中运行 TAGE(用于条件分支)和 ITTAGE(用于间接分支)预测器。论文使用了两种 ITTAGE 配置:TAGE1 (12.62 KB) 和 TAGE2 (6.31 KB),其参数详见下表。
Table 2. Branch predictor parameters
- 一致性验证: 论文专门验证了 PMU 硬件计数与 Pin 模拟轨迹在指令计数上的一致性,确认差异在 1% 以内,保证了实验数据的可比性。
结果数据分析
- 核心发现: 分支误预测率(MPKI, Mispredictions Per Kilo Instructions)在三代 Intel 处理器上呈现戏剧性下降。
- Nehalem: MPKI 范围在 12-20,意味着每千条指令因分支误预测损失约 240-400 个周期(假设平均惩罚为20周期)。
- Sandy Bridge: MPKI 显著降低至 4-8 左右。
- Haswell: MPKI 进一步降至 0.5-2 的极低水平,表明分支误预测已不再是性能瓶颈。
- 模拟器 vs 硬件: Haswell 上测得的 MPKI 与 TAGE+ITTAGE 模拟器的结果处于同一数量级,这表明 Haswell 的间接分支预测器性能已经非常接近学术界的最先进水平(SOTA)。
- 前端浪费槽位分析: 通过 Intel 的 pmu-tools 分析处理器前端的浪费指令发射槽位(wasted issue slots),发现这些浪费几乎完全由分支误预测导致。Haswell 平均仅浪费 7.8% 的槽位,而 Sandy Bridge 浪费 14.5%,再次印证了 Haswell 分支预测的巨大改进。
Figure 7. Correlation between MPKI and lost slots
- 各解释器详细表现:
- Python: 在 Haswell 上 IPC(Instructions Per Cycle)中位数达到 2.4。每个字节码平均消耗 120-150 条原生指令,主要开销来自动态类型检查。当负载(payload)简单且间接分支少时,TAGE+ITTAGE 几乎可以完美预测。
- Javascript: 其 dispatch loop 更短(16条指令),每个字节码平均消耗约 60 条指令。同样观察到从 Nehalem 到 Haswell 的 MPKI 急剧下降。
- CLI: 作为低抽象级别解释器,其 dispatch loop 极短(7条指令),每个字节码仅需 21 条指令。但在 vpr 和 crafty 等基准上,即使 Haswell 和 TAGE1 也表现出相对较高的 MPKI,论文将其归因于解释器巨大的预测器足迹(predictor footprint)——其 switch 语句有 478 个目标,对预测器容量要求极高。
Figure 4. Python MPKI for all predictors
Figure 5. Javascript MPKI for all predictors
Figure 6. CLI MPKI for all predictors
消融实验
- Jump Threading 性能增益分析: 论文通过在 Python 上启用和禁用 jump threading(利用 GNU 的 Labels as Values 扩展)来进行消融实验。
- 性能提升递减: 实验显示,jump threading 带来的性能提升在新架构上显著减弱。在 Nehalem 上平均提升 10.1%,在 Sandy Bridge 上降至 4.2%,而在 Haswell 上仅为 2.8%。
- 原因剖析: 论文指出,性能提升并非完全来自更好的分支预测。通过指令计数发现,threaded code 版本平均减少了 3.3% 的指令数,这是因为部分 dispatch loop 逻辑被绕过。这表明,在现代处理器上,jump threading 的收益更多来自于减少指令开销,而非解决分支误预测问题。
Figure 3. Speedups in Python
- “难以预测”分支的针对性分析: 论文直接挑战了关于 dispatch loop 中间接跳转“天生难以预测”的民间传说(folklore)。通过模拟器,他们单独追踪了该间接分支的误预测率。
- 结论: 该分支并非内在不可预测。在大多数情况下,即使是较小的 ITTAGE(6KB)也能很好地预测它。
- 失败案例分析: 对于少数预测不佳的案例(如 Python 的
go,CLI 的vpr和crafty),增大 ITTAGE 容量(至 12KB 或 50KB)后,预测准确率显著提升。这证明问题根源在于预测器容量不足(footprint issue),而非预测模式本身无效。 - 额外发现: Python 源码中提到的另一个“难以预测”的条件分支(
HAS_ARG宏)实际上也非常容易被 TAGE 预测准确。
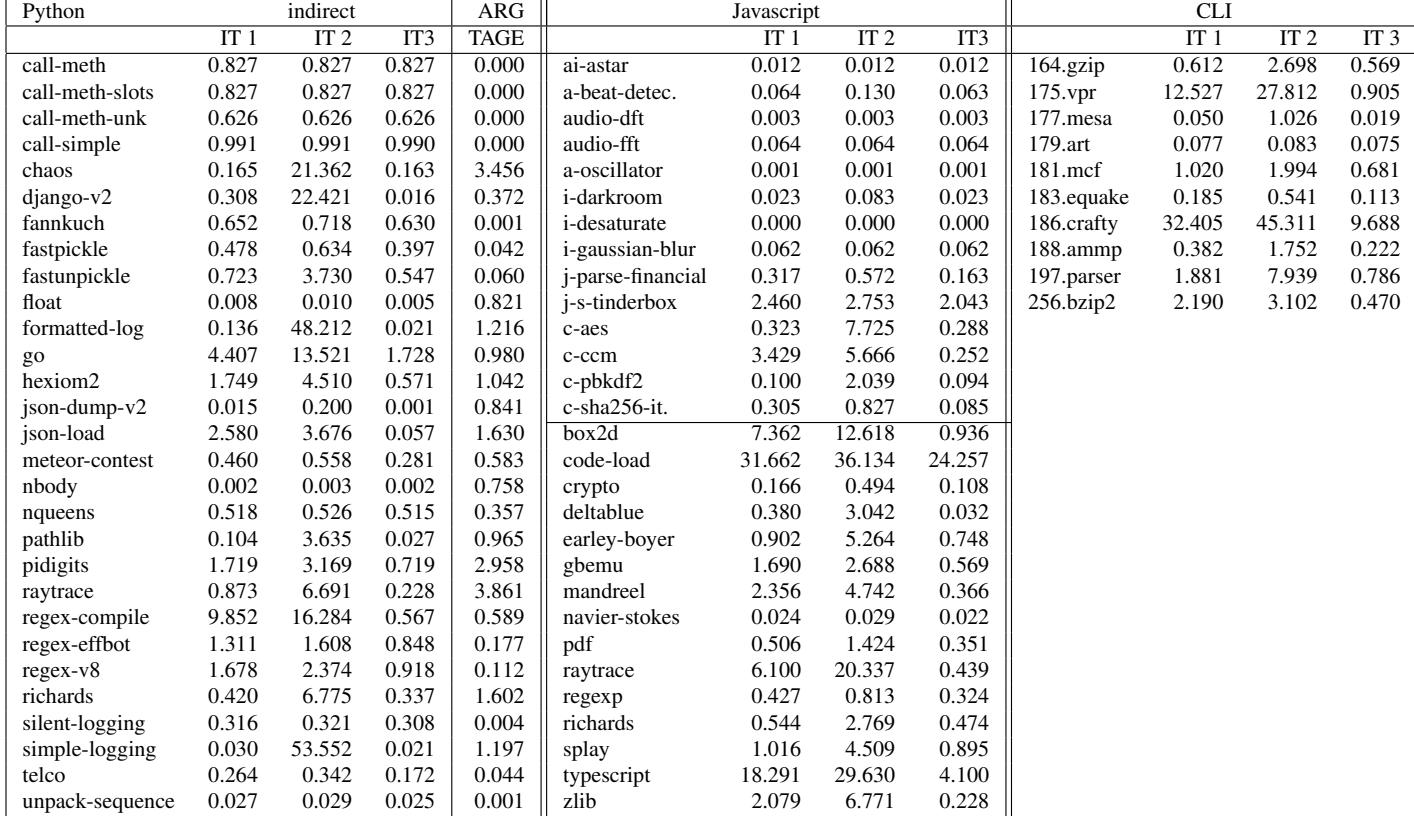 Table 6. (IT)TAGE misprediction results for “hard to predict” branch, TAGE 1, TAGE 2 and TAGE 3 (all numbers in %)
Table 6. (IT)TAGE misprediction results for “hard to predict” branch, TAGE 1, TAGE 2 and TAGE 3 (all numbers in %)