An Empirical Study on the Performance and Energy Usage of Compiled Python Code 通俗讲解¶
0. 整体创新点通俗解读¶
痛点直击 (The "Why")
- 这篇论文要解决的核心问题,不是“Python慢不慢”,而是“到底哪些编译器真正管用?在什么维度上管用?”。
- 之前的很多研究和开发者讨论都停留在模糊的印象层面,比如“PyPy快”、“Numba适合科学计算”。但这些说法缺乏严谨、可控的实证。
- 具体来说,过去的实验往往忽略了关键的混杂变量(confounding variables):
- 硬件干扰:CPU频率动态调整、多核并行调度会极大地影响执行时间和能耗的测量结果,导致数据不可比。
- 代码干扰:很多基准测试(如pyperformance)大量使用NumPy等C扩展库,这会让性能提升归功于底层C代码,而非Python编译器本身,从而高估了编译器的效果。
- 评估维度单一:大多数比较只看速度,而忽略了同样重要的能耗、内存占用,甚至像LLC缓存命中率这样能揭示性能瓶颈根源的指标。
通俗比方 (The Analogy)
- 想象你要评测不同品牌的节能灯泡。过去的做法是,把它们装在不同人家的客厅里,有的客厅大、有的小,有的主人喜欢开一整晚,有的只开一小时。然后你问:“哪个灯泡更省电?”——这种比较毫无意义。
- 这篇论文的做法是,把所有灯泡放进一个完全相同的、密封的暗室里,用同一个开关控制,点亮完全相同的时间,然后用同一个高精度电表来测量耗电量。不仅如此,它还同时记录了灯泡的发热量(类比内存) 和内部电路的稳定性(类比缓存)。
- 它本质上是在构建一个纯净的、隔离的实验室环境,只为回答一个问题:抛开一切外部因素,这些Python编译器自身的“体质”到底如何?
关键一招 (The "How")
- 作者并没有发明新的编译器,而是设计了一个极其严谨的对照实验。其巧妙之处在于对实验变量的极致控制:
- 基准选择:只选用来自Computer Language Benchmarks Game (CLBG) 的代码。这些代码是纯Python、单线程、无第三方库依赖的,确保了性能差异完全源于编译器本身。
- 硬件控制:在两台不同的机器(NUC和服务器)上,都禁用超线程、锁定CPU频率、并将所有任务绑定到单个核心上运行。这彻底消除了操作系统调度和硬件动态调频带来的噪音。
- 多维评估:不仅仅测量执行时间,还通过Intel RAPL接口精确测量能耗(KiloJoules),通过
perf工具监控LLC miss rate,并通过EnergiBridge跟踪内存占用(RSS)。
- 通过这套方法,他们得以清晰地分离出不同编译器的真实效果。例如,他们发现Codon, PyPy, 和 Numba 在速度和能耗上实现了超过90%的惊人改进,而像Nuitka则在内存优化上表现最为稳定。同时,他们也揭示了某些编译器(如Nuitka)在特定场景下(如
n_body)反而会因为糟糕的缓存行为(极高的LLC miss rate)而导致性能下降。
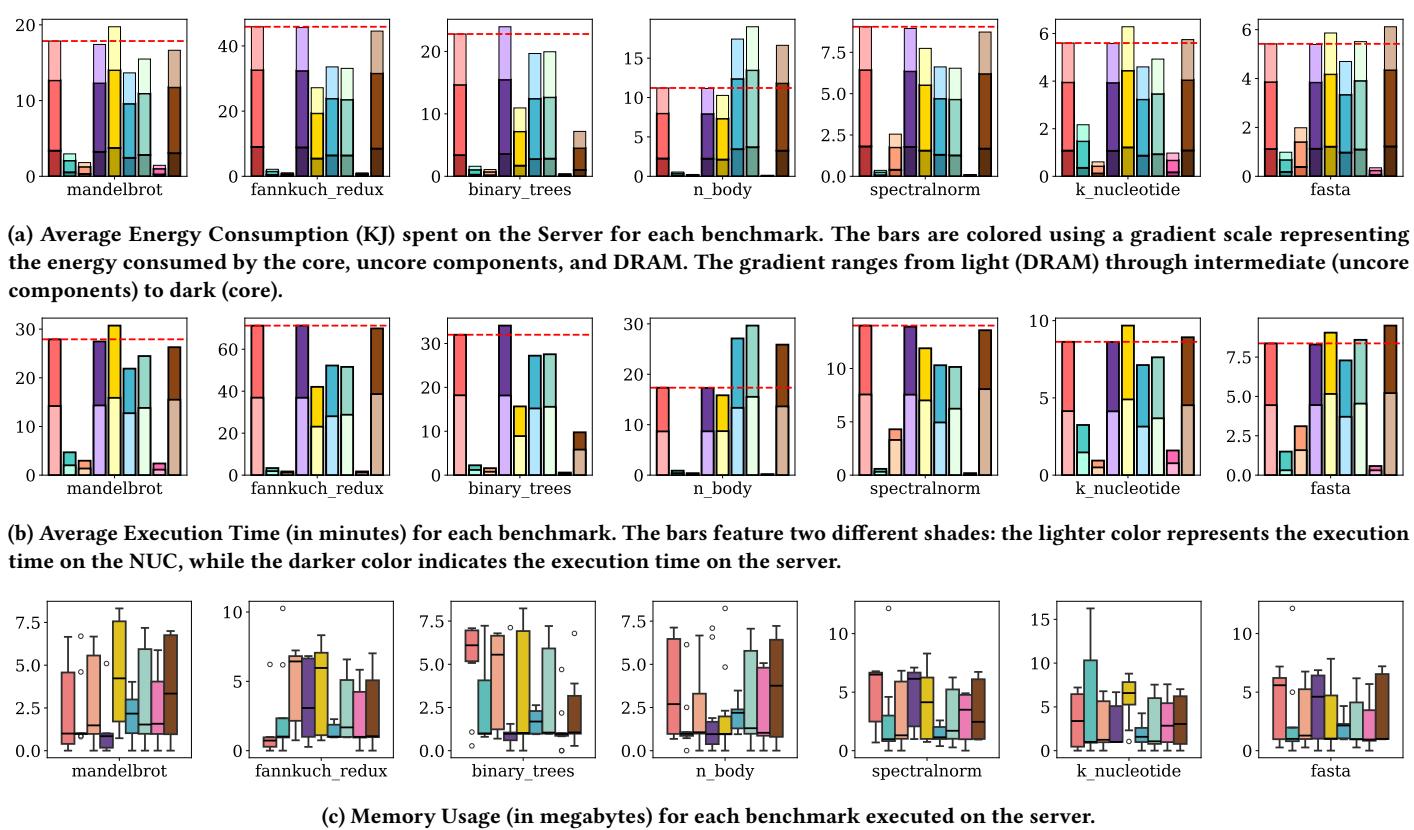 Figure 2: Average energy usage, execution time, and memory usage for each benchmark by compiler. The dashed red line represents the threshold of the CPython implementation for a given benchmark. Legend: CPython, PyPy, Numba, Pyston-lite, Python 3.13 JIT, Nuitka, Cython, Codon, MyPyc
Figure 2: Average energy usage, execution time, and memory usage for each benchmark by compiler. The dashed red line represents the threshold of the CPython implementation for a given benchmark. Legend: CPython, PyPy, Numba, Pyston-lite, Python 3.13 JIT, Nuitka, Cython, Codon, MyPyc
这张图完美地总结了他们的发现:红色虚线代表CPython基线,可以看到Codon、PyPy、Numba在几乎所有benchmark上都大幅超越了基线,而其他编译器的表现则参差不齐,甚至在某些情况下(如n_body)表现更差。这种清晰、直观、多维度的对比,正是这篇论文最核心的贡献。
1. 受控实验设计¶
痛点直击 (The "Why")
- 以前很多关于 Python 编译器性能和能耗的研究,结论其实很“虚”。为什么?因为它们的实验环境太“脏”了。
- 硬件层面:CPU 频率会动态调整(比如 Intel 的 Turbo Boost),多核调度策略也千变万化。一个程序跑得快,到底是编译器牛,还是刚好撞上了高频核心?根本分不清。
- 代码层面:很多 benchmark(比如 pyperformance)重度依赖 NumPy 这类用 C 写的库。测出来的性能提升,到底是 Python 编译器的功劳,还是底层 C 库的功劳?这就像给一辆车换了个新方向盘,却说它跑得更快了。
- 这种混杂变量导致的结果就是:不同研究之间无法公平比较,开发者也无法根据论文结果做出可靠的技术选型。
通俗比方 (The Analogy)
- 想象你要测试十种不同品牌的汽油,看哪种最省油。但你每次测试都用不同的车、在不同的路况(上坡/下坡)、由不同的司机来开。那最后省油的数据,到底反映的是汽油的好坏,还是车、路、人的差异?
- 这篇论文的做法,就相当于把所有测试都放在同一辆车上,由同一个机器人司机,在一条完全平坦、笔直、无风的封闭跑道上,以恒定的速度跑完。这样,任何油耗的差异,才能真正归因于汽油本身——也就是这里的 Python 编译器。
关键一招 (The "How")
- 作者没有去追求更复杂的模型或更大的数据集,而是反其道而行之,做了一个极致“干净”的实验。他们通过三重控制,把干扰项全部锁死:
- 控制代码特征:只选用 CLBG 中的七个基准测试。这些代码都是单线程、不依赖任何第三方库(如 NumPy, Pandas),确保性能差异纯粹来自编译器对 Python 语言本身的优化能力。
- 控制硬件执行环境:在两台不同的机器(NUC 和 Server)上,都强制将程序绑定到单个 CPU 核心上运行,并通过 Linux 的 CPU governor 将频率固定在一个值(Server: 1.6GHz, NUC: 2.1GHz)。这彻底消除了多核并行和动态频率缩放带来的噪音。
- 控制测量方法:使用 EnergiBridge (基于 RAPL)、perf 和 time 等工具,在完全相同的条件下,精确测量 能量消耗 (KJ)、执行时间 (min)、内存占用 (RSS, MB) 和 LLC miss rate (%) 这四个核心指标。
- 这个设计的精妙之处在于,它牺牲了“现实世界的复杂性”,换取了“因果关系的清晰性”。只有在这种受控环境下得出的结论——比如 Codon, PyPy, Numba 能带来超过 90% 的性能和能效提升——才具有真正的说服力和可复现性。
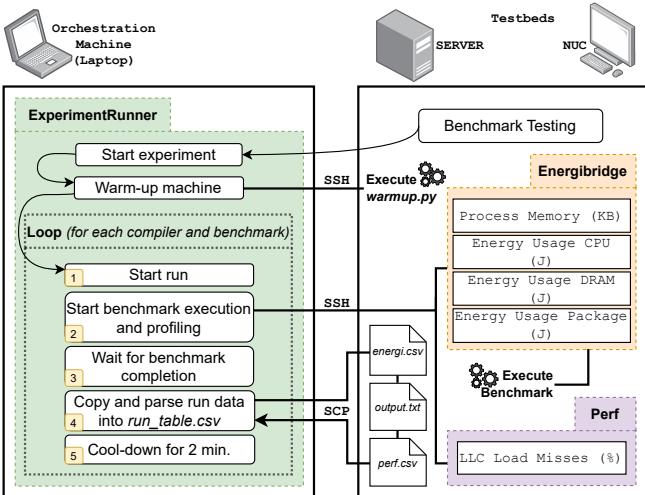 Figure 1: Experiment Execution
Figure 1: Experiment Execution
2. 多维度效能评估指标¶
痛点直击
- 以前评估 Python 编译器,往往只盯着 执行时间 这一个指标。这就像买车只看百公里加速,完全不管油耗、保养成本和乘坐空间。
- 这种单一视角会带来严重误导:
- 一个编译器可能通过疯狂占用 内存 来换取速度,这在资源受限的边缘设备上是灾难。
- 另一个编译器可能跑得快,但因为糟糕的内存访问模式导致 LLC miss rate 极高,这会让它在不同硬件上的表现极不稳定。
- 最关键的是,在当今绿色计算(Green Computing)的背景下,能量消耗 是一个无法回避的成本。一个省电但稍慢的方案,可能比一个耗电巨兽更具实际价值。
通俗比方
- 这套 多维度效能评估指标 的思路,就像是给每个编译器做一次全面的“体检”,而不是只量体温。
- 想象你是一个系统架构师,需要为公司的新项目选型。你的决策不能只基于“谁跑得最快”,而必须综合考虑:
- 执行时间:任务完成的速度(工作效率)。
- 能量消耗:运行这个任务要花多少电费(运营成本)。
- 内存使用 (RSS):它占用了多少宝贵的物理内存(资源占用)。
- LLC miss rate:它对 CPU 缓存的“友好度”如何,这直接关系到其性能的可预测性和在不同服务器上的移植性(底层效率)。
- 这四个指标合在一起,才能描绘出一个编译器真实的、立体的“能效画像”。
关键一招
- 作者的核心洞察在于,性能(Performance)和 能效(Energy Efficiency)虽然相关,但并非总是一致,必须分开测量和分析。
- 为了实现这个目标,他们在实验设计上做了几个关键扭转:
- 控制变量:他们刻意选择了 单线程、无第三方库 的基准测试,并在 固定CPU频率 和 单核 上运行。这剥离了并行计算和外部库优化的干扰,让测量结果纯粹反映编译器本身的优化能力。
- 引入硬件级监控:他们没有依赖操作系统层面的粗略估算,而是直接利用 Intel CPU 的 RAPL 接口来精确测量 能量消耗,并用 perf 工具来抓取 LLC miss rate 这种底层硬件事件。
- 跨平台验证:他们在 NUC(客户端/边缘设备代表)和 Server(服务器代表)两个截然不同的硬件平台上重复实验,以检验结论的普适性。
- 正是这套严谨的、多维度的测量方法,让他们得出了像“Codon, PyPy, and Numba achieve over 90% speed and energy improvements”这样既具体又可靠的结论,并揭示了像 Nuitka 在 内存使用 上表现优异但在 LLC miss rate 上表现极差这样的复杂权衡。
 Table 2: Descriptive Statistics from Server data. The highlighted number shows the minimum average value.
Table 2: Descriptive Statistics from Server data. The highlighted number shows the minimum average value.
上表清晰地展示了这种多维评估的价值。例如,PyPy 虽然在 Execution Time 和 Energy 上表现极佳,但其 Memory 消耗却是所有编译器中最高的。而 Nuitka 则正好相反,它的 Memory 使用最低,但 LLC miss rate 高得惊人。如果只看单一指标,我们可能会错过这些关键的取舍(trade-offs)。
3. 跨平台验证¶
痛点直击
- 以前很多关于编译器或语言性能的实验,结论往往“飘在天上”,因为它们只在一个特定的机器上跑。这带来一个致命问题:你看到的速度提升或能耗降低,到底是编译器真牛,还是恰好这个编译器和这台机器的CPU、缓存、内存控制器“八字相合”?
- 这种“单点验证”的结果非常脆弱。今天在你的工作站上快如闪电,明天换到云服务器上可能就原形毕露,甚至更慢。对于工程师来说,这种不可预测性是最难受的——我没法放心地在生产环境里用。
通俗比方
- 这就像测试一种新配方的汽油。你不能只在一辆法拉利上测试它能跑多快,就宣称它是“终极燃油”。你必须把它加到出租车、卡车甚至拖拉机里试试。如果它在各种引擎上都能稳定地省油提速,那才是真本事。
- 在这篇论文里,“Intel NUC”代表了现代高性能客户端设备(比如开发者的笔记本),而“服务器”则代表了传统的数据中心计算单元。它们的CPU微架构、缓存层次、功耗墙都不同。跨平台验证,就是看这些Python编译器是不是“通才”,而不是只会讨好某一款硬件的“偏科生”。
关键一招
- 作者并没有满足于在一个环境里跑出漂亮数据,而是把整个实验流程完整地复制到了两个差异显著的硬件平台上。
- 具体来说,他们做了两件关键的事来保证验证的有效性:
- 严格控制变量:在两个平台上,都固定CPU频率、禁用超线程、绑定到单核运行。这剥离了操作系统调度和动态频率缩放带来的噪音,让比较聚焦在编译器本身和硬件微架构的交互上。
- 交叉验证结论:他们不是简单地看两个平台的数据是否一样,而是分析优化效果的趋势是否一致。例如,论文发现Codon, PyPy, 和 Numba 在两个平台上都带来了超过90%的性能和能效提升,这就强有力地证明了它们的优势是普适的,而非平台特例。
- 这个设计直接回应了相关工作中的一个普遍缺陷:很多研究使用像
pyperformance这样的基准套件,其中包含大量依赖NumPy等C扩展的测试项,这会掩盖纯Python代码的优化效果,并且其并行特性会干扰单线程性能分析。本文选用的CLBG基准是纯Python、单线程、无第三方库的,再叠加跨平台验证,就构建了一个干净、可靠、可复现的评估框架。
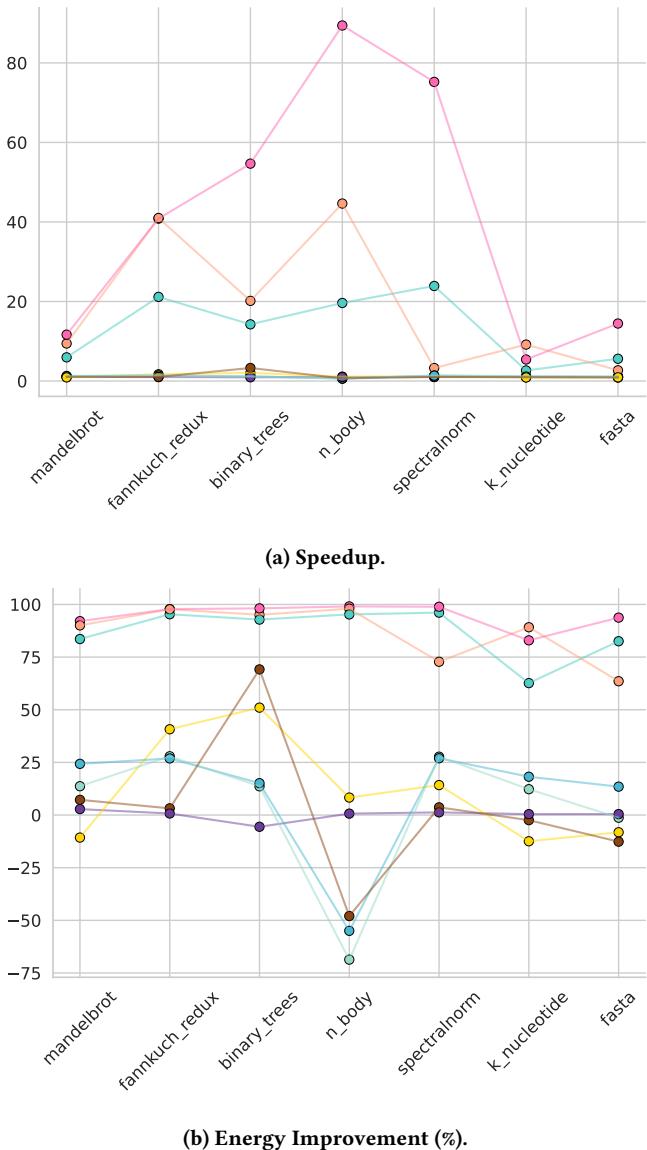 Figure 3: Speedup and Energy improvement on the server across benchmarks compared to CPython. Legend: PyPy, Numba, Pyston-lite, Python 3.13 JIT, Nuitka, Cython, Codon, MyPyc
Figure 3: Speedup and Energy improvement on the server across benchmarks compared to CPython. Legend: PyPy, Numba, Pyston-lite, Python 3.13 JIT, Nuitka, Cython, Codon, MyPyc
上图清晰地展示了跨平台验证的价值。我们可以看到,尽管NUC和服务器的绝对性能不同,但各编译器相对于CPython的speedup(加速比) 和 energy improvement(能效提升) 的相对排名和趋势在两个平台上高度一致。特别是Codon, PyPy, Numba 这三者始终处于领先地位,而Pyston-lite的效果则不明显。这种一致性,正是“跨平台验证”想要捕捉和证明的核心。
4. 广泛的Python编译器对比¶
痛点直击
- 以前大家都知道 Python 慢、耗电,也知道用编译器能提速,但具体该选哪个?这就像面对一堆“偏方”,有人说 A 好,有人说 B 强,但没人告诉你:
- 这些“神药”在不同病症(代码特征)下效果天差地别。比如,一个编译器对纯数学计算快如闪电,但对字符串处理可能毫无作用,甚至更慢。
- 很多比较实验本身就有问题:有的在多核上跑,有的让 CPU 动态调频,还有的代码里塞满了 NumPy 这种本身就高度优化的 C 库。这根本没法公平比较,因为测出来的性能提升,到底是编译器的功劳,还是底层库或硬件调度的功劳?
- 所以,开发者和研究者很“难受”:想优化代码,却不知道哪种工具投入产出比最高,甚至可能白忙活一场。
通俗比方
- 这项研究就像是给八位不同的“健身教练”(编译器)做了一场严格的体能测试。
- 之前的测试很混乱:有的教练带着学员在平地上跑,有的在山上跑;有的允许吃能量棒(NumPy),有的不让。结果自然没法比。
- 而这次,研究者把所有教练和学员都带到同一个标准跑道(单核、固定频率)上,并且规定所有人都只能用自己的身体(纯 Python 逻辑,无第三方库)来完成同一套标准化的体能动作(CLBG 基准测试)。这样,谁是真的“肌肉猛男”,谁是“花架子”,就一目了然了。
关键一招
- 作者并没有去发明新编译器,而是巧妙地设计了一个极其干净、受控的实验环境,把所有干扰变量都锁死了。
- 具体来说,他们做了三件事来“扭转”局面:
- 统一战场:强制所有代码在单核上运行,并将 CPU 频率固定,彻底排除了并行和动态频率缩放带来的噪音。
- 净化代码:精心挑选了 CLBG 中的基准程序,确保它们都是单线程且不依赖任何第三方库(如 NumPy),这样测出的性能差异才能真正归因于编译器本身。
- 全面体检:不仅看执行时间这个老指标,还同时测量了能量消耗、内存占用和 LLC (Last-Level Cache) miss rate 这三个关键维度,给出了一个全方位的健康报告。
- 正是这个严谨的设计,让他们得出了清晰、可靠的结论:Codon, PyPy, 和 Numba 是真正的“全能选手”,在速度和能效上带来了超过 90% 的巨大提升;而 Nuitka 则是“节食专家”,在内存优化上表现最为稳定。
Figure 2: Average energy usage, execution time, and memory usage for each benchmark by compiler. The dashed red line represents the threshold of the CPython implementation for a given benchmark. Legend: CPython, PyPy, Numba, Pyston-lite, Python 3.13 JIT, Nuitka, Cython, Codon, MyPyc
上图直观地展示了这一对比结果。红色虚线代表 CPython 基准,可以看到 Codon, PyPy, Numba 在绝大多数基准测试中都远低于这条线,意味着它们在执行时间、能耗和内存上都实现了显著优化。这种系统性的、多维度的对比,正是本研究最核心的价值所在。
5. 标准化的数据分析方法¶
痛点直击 (The "Why")
- 以前很多系统性能或能效的对比实验,结论往往很“飘”。作者们经常只画个柱状图,说“A比B快了20%”,就完事了。但这种说法在科学上是站不住脚的。
- 真正的痛点在于:性能数据天然具有高波动性。同一段代码跑十次,执行时间、能耗都可能不一样,这受操作系统调度、缓存状态、甚至CPU温度的影响。如果不用严格的统计方法去分析,你根本分不清观察到的“提升”是编译器真的牛,还是纯粹的随机噪音。
- 更糟糕的是,即使差异是真实的,你也不知道这个差异到底“大不大”。快1%和快90%对用户来说是天壤之别,但简单的平均值比较无法量化这种效应的强度。
通俗比方 (The Analogy)
- 这套标准化的数据分析方法,就像是给你的实验结果做一次全面的医学体检,而不是靠肉眼看看气色。
- Shapiro-Wilk检验 就像先验血,看看你的数据分布是不是“健康”的(正态分布)。如果是健康的,就可以用更精确的“处方”(ANOVA);如果不健康(非正态),就得换一套更稳健的“治疗方案”(Kruskal-Wallis)。
- 而 Cliff's Delta 则像是一个疗效评估报告。它不只告诉你新药(编译器)和安慰剂(CPython)有没有区别,还会明确告诉你,这个药的效果是“微乎其微”、“略有改善”还是“立竿见影”。
关键一招 (The "How")
- 作者没有停留在计算平均值和画图的层面,而是构建了一个严谨的统计推断流水线来支撑每一个结论。
- 核心逻辑转换在于:将“哪个编译器更好”这个工程问题,转化为了“不同编译器产生的性能指标分布之间是否存在统计学上显著且有实际意义的差异”这个科学问题。
- 具体来说,他们做了两步关键操作:
- 第一步:选择正确的检验工具。通过 Shapiro-Wilk test 对每个编译器在每个指标上的数据进行正态性检验。因为论文中的能耗、执行时间等数据跨不同benchmark尺度差异巨大(如图2a所示),几乎必然非正态,所以他们明智地选用了非参数的 Kruskal-Wallis test 来判断多组数据间是否存在任何显著差异。
- 第二步:量化差异的实际价值。仅仅知道“有差异”还不够。他们使用 Cliff's Delta 这个非参数效应量指标,将CPython作为基线,与每个编译器进行两两比较。这个指标能告诉你,从CPython随机抽取一个样本,其性能比从编译器X中随机抽取一个样本更差的概率是多少。例如,论文中提到PyPy、Numba和Codon的Cliff's Delta为1.0,这意味着在他们的实验中,CPython的每一次运行结果都比这三个编译器的任何一次运行结果要差,这是一个极其强大且清晰的结论。
- 这套方法确保了论文的核心发现——“Codon, PyPy, and Numba achieve over 90% speed and energy improvements”——不是一句模糊的营销口号,而是一个经过统计学验证的、可靠的科学论断。 Figure 2: Average energy usage, execution time, and memory usage for each benchmark by compiler. The dashed red line represents the threshold of the CPython implementation for a given benchmark. Legend: CPython, PyPy, Numba, Pyston-lite, Python 3.13 JIT, Nuitka, Cython, Codon, MyPyc