A CPU-CENTRIC PERSPECTIVE ON AGENTIC AI 通俗讲解¶
0. 整体创新点通俗解读¶
痛点直击 (The "Why")
- 过去大家优化 LLM 时,眼睛都死死盯着 GPU,疯狂压榨它的计算和显存带宽。这在纯推理场景下没问题。
- 但 Agentic AI 完全变了:它不再是“输入-输出”的简单流程,而是一个 LLM + 外部工具 的混合体。这些工具(比如 Python 执行、Web 搜索、向量检索)根本跑在 CPU 上。
- 结果就是,当你把 GPU 优化到飞起时,发现 90% 的时间 都卡在 CPU 工具调用上(见 Figure 2),GPU 只能干等着。整个系统变成了一个 CPU 瓶颈 的“瘸腿”系统,之前的 GPU 优化努力大打折扣。
通俗比方 (The Analogy)
- 想象你有一条顶级的 F1 赛车生产线(GPU),每分钟能造出一辆车。但你的 零件仓库(CPU 工具) 在城郊,每次取关键零件都要花 10 分钟开车过去。
- 无论你的生产线多快,整条线的产出速度 完全被这个 10 分钟的取件时间 给锁死了。论文要解决的,就是如何优化这个“取件”环节,或者干脆重新设计物流,让生产线和仓库能高效协同。
关键一招 (The "How")
- 这篇论文的核心贡献不是提出一个新模型,而是 首次系统性地揭示并量化了 Agentic AI 中的 CPU 瓶颈,并基于此提出了两个调度层面的优化策略。
- 核心洞察:Agentic AI 的性能瓶颈已经从 纯 GPU-bound 转移到了 CPU/GPU 协同-bound。因此,优化必须是 CPU-Centric 的。
- 具体做法:
- 第一步:精准画像。作者没有泛泛而谈,而是提出了三个维度(Orchestrator, Path, Repetitiveness)来对 Agentic Workload 进行分类(见 Figure 1),并选了 5 个典型 workload 进行深度剖析。
- 第二步:量化瓶颈。通过 profiling,他们用数据说话:Tool processing latency 占比高达 90.6%;CPU dynamic energy 在大 batch 下占总能耗的 44%(见 Figure 5)。这彻底颠覆了“GPU 是唯一瓶颈”的认知。
- 第三步:对症下药。基于上述发现,他们设计了两种调度器:
- CGAM (CPU and GPU-Aware Micro-batching):针对 同构 workload(比如全是 LangChain 请求)。它发现盲目增大 batch size 会导致 CPU 过载(core over-subscription)和 GPU 显存压力,反而拖慢 P50 延迟。于是,它聪明地设置了一个 batching cap,将大 batch 拆成 micro-batch 顺序处理。这样既能利用并行性,又避免了资源争抢,实现了 2.1x 的 P50 延迟加速(见 Figure 7)。
- MAWS (Mixed Agentic Workload Scheduling):针对 异构 workload(比如同时有 CPU-heavy 和 LLM-heavy 的请求)。它意识到,如果对所有请求都用 multi-processing,会让 LLM-heavy 的轻量请求白白占用大量 CPU 核心,挤占了真正需要 CPU 资源的 heavy 请求。所以,它 自适应地为不同请求选择并行策略:CPU-heavy 用 multi-processing,LLM-heavy 用更轻量的 multi-threading。这释放了宝贵的 CPU 资源,让混合负载下的整体性能更均衡(见 Figure 8)。
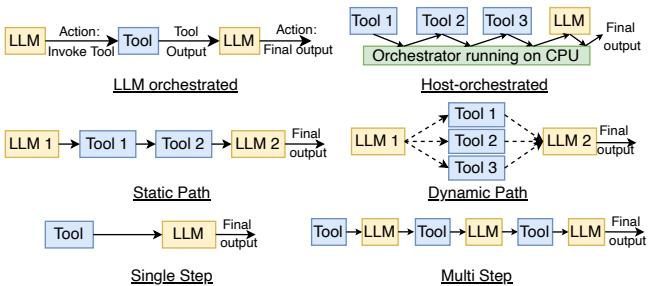 Figure 1. Characterization of agentic AI workloads on the basis of (a) Orchestrator (LLM and Host) (b) Agentic Path (Static and Dynamic) and (c) Repetitiveness (Single-step and Multi-step)
Figure 1. Characterization of agentic AI workloads on the basis of (a) Orchestrator (LLM and Host) (b) Agentic Path (Static and Dynamic) and (c) Repetitiveness (Single-step and Multi-step)
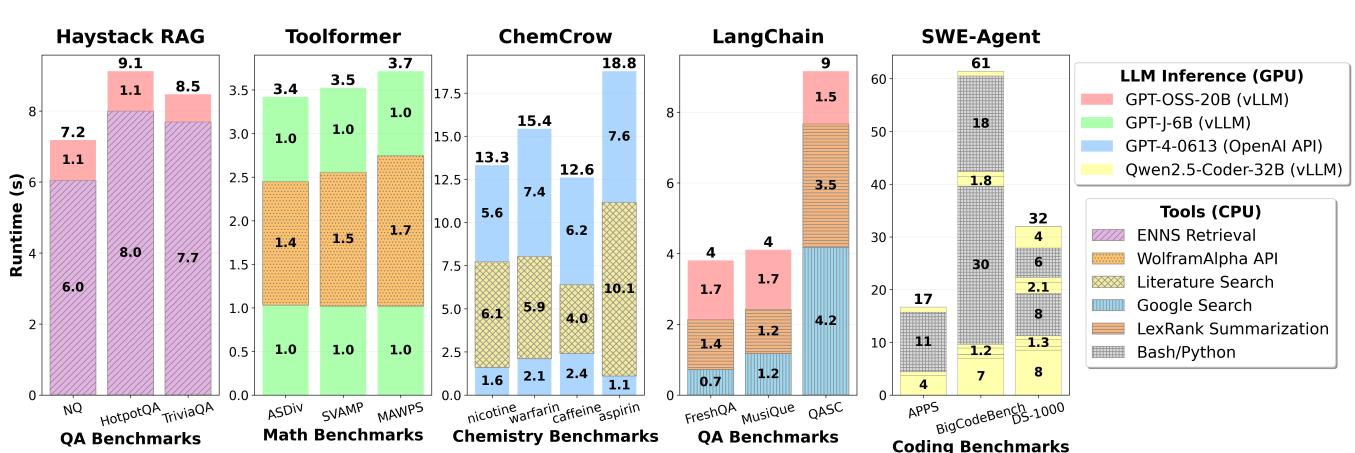 Figure 2. (a) Haystack with ENNS retrieval on QA benchmarks (b) Toolformer with WolframAlpha API on Math benchmarks (c) Chemcrow with literature (Arxiv/Pubmed) search tool on Chemistry benchmarks (d) Langchain with web search and LexRank summarization tools on QA benchmarks (e) Mini-SWE-Agent with bash/Python execution tools on coding benchmarks
Figure 2. (a) Haystack with ENNS retrieval on QA benchmarks (b) Toolformer with WolframAlpha API on Math benchmarks (c) Chemcrow with literature (Arxiv/Pubmed) search tool on Chemistry benchmarks (d) Langchain with web search and LexRank summarization tools on QA benchmarks (e) Mini-SWE-Agent with bash/Python execution tools on coding benchmarks
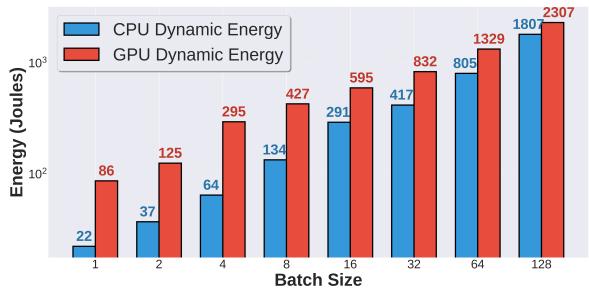 Figure 5. CPU (AMD Threadripper) and GPU (Nvidia B200) dynamic energy consumption for Langchain workload
Figure 5. CPU (AMD Threadripper) and GPU (Nvidia B200) dynamic energy consumption for Langchain workload
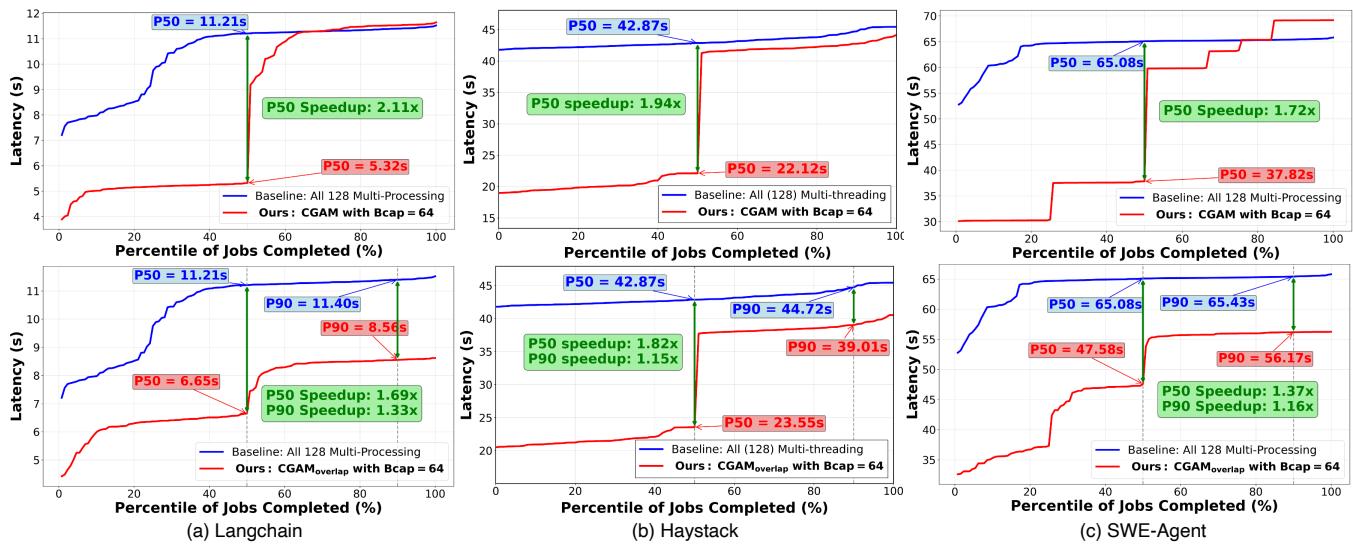 Figure 7. Comparison of CGAM and CGAMoverlap using Bcap = 64 against baseline (multi-processing or multi-threading) on (a) Langchain workload on FreshQA benchmark, (b) Haystack workload on NQ benchmark and (c) SWE-Agent on APPS benchmark
Figure 7. Comparison of CGAM and CGAMoverlap using Bcap = 64 against baseline (multi-processing or multi-threading) on (a) Langchain workload on FreshQA benchmark, (b) Haystack workload on NQ benchmark and (c) SWE-Agent on APPS benchmark
1. CPU and GPU-Aware Micro-batching (CGAM)¶
痛点直击
- 以前跑 Agentic AI,大家习惯性地把所有请求一股脑塞给系统做 batching,心想“越多越划算”。但这篇论文发现,在 Agentic 场景下,这招会“搬石头砸自己的脚”。
- 具体来说,当 batch size 大到一定程度(比如128),系统就“吃撑了”:
- CPU 端:工具执行(如 Python、Web Search)需要大量并行进程,导致 core over-subscription,线程间争抢资源、频繁 context switching,让本该快的 CPU 工具反而变慢,P50 latency 直接翻倍。
- GPU 端:巨大的 KV cache 会耗尽显存带宽甚至容量,让 LLM 推理也变慢。
- 能耗端:CPU 的动态能耗占比飙升至 44%,效率极低。
- 所以,问题的核心不是“能不能 batch”,而是“batch 到多大才刚刚好”,再大就纯属浪费甚至有害。
通俗比方
- 这就像你去一家网红餐厅吃饭。餐厅有 两个窗口:一个负责 点菜/上菜 (CPU),另一个是 后厨炒菜 (GPU)。
- 如果你一次性叫了 128 个人一起点餐,会发生什么?
- 点菜窗口会挤爆,服务员手忙脚乱,记错单、上错菜,前面的人等得不耐烦(高 P50 latency)。
- 后厨也堆满了订单,锅碗瓢盆全占满,厨师互相挡路,出菜速度反而变慢。
- CGAM 的做法是:不让128人一窝蜂涌上去,而是分成两批 micro-batch,每批64人。
- 第一批64人先去点菜、后厨开始炒。
- 等第一批的菜快上齐时,第二批64人才开始点菜。
- 这样,两个窗口都保持在 高效、不拥堵 的状态,第一批客人能更快吃到饭(降低 P50 latency),整个餐厅的翻台率和能耗也更优。
关键一招
- 作者没有去魔改 LLM 或工具本身,而是在调度层面做了一个非常聪明的 流量整形 (Traffic Shaping)。
- 核心逻辑转换在于:用 throughput gain ratio 来动态设定一个 batching cap (Bcap)。
- 他们定义了一个指标
r(B) = T(B) / T(B/2),即 batch size 翻倍后,吞吐量能提升多少。 - 一旦
r(B)低于一个阈值(比如1.1,意味着只提升了10%),就说明再增大 batch size 得不偿失,此时的 B 就是 Bcap。
- 他们定义了一个指标
- 在实际执行时:
- 面对一个大 batch(如128),系统不再一次性处理,而是将其拆成多个 micro-batch(如两个64)。
- 这些 micro-batch 顺序执行,确保任何时候系统的负载都不会超过 Bcap,从而完美避开 CPU/GPU 的饱和区。
- 这一招直接带来了三大好处:
- ~2x P50 latency speedup:第一批请求能更快完成。
- ~0.5x KV cache usage:GPU 显存压力减半。
- ~2x CPU energy reduction:避免了无谓的 core over-subscription。
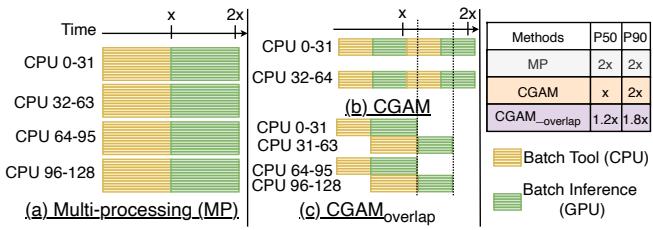 Figure 6. Timeline of batched agentic AI inference for (a) Multiprocessing, (b) CGAM, and (c) CGAMoverlap
Figure 6. Timeline of batched agentic AI inference for (a) Multiprocessing, (b) CGAM, and (c) CGAMoverlap
上图清晰地展示了 CGAM 的威力。Baseline(Multiprocessing)下,所有128个请求同时启动,导致 CPU 和 GPU 都长时间处于高负载拥堵状态。而 CGAM 将其拆成两个64的 micro-batch 顺序执行,不仅让第一批请求(前64个)的完成时间大幅提前,还让整个系统的资源曲线变得平滑高效。
2. Mixed Agentic Workload Scheduling (MAWS)¶
痛点直击 (The "Why")
- 以前的调度器,比如简单的 multi-processing,把所有任务都一视同仁地扔给独立进程处理。这在面对异构工作负载(heterogeneous workloads)时就“很难受”了。
- 具体来说,系统里同时跑着两种活:一种是 CPU-heavy 的(比如 LangChain 里要爬网页、做摘要),另一种是 LLM-heavy 的(比如一个纯文本生成请求,工具调用很少)。LLM-heavy 的任务虽然主要算力在 GPU,但它启动时依然会占用一个完整的 CPU 进程。
- 当大量 LLM-heavy 任务涌入时,它们会无谓地抢占宝贵的 CPU 核心,导致真正需要 CPU 算力的 CPU-heavy 任务反而“饿死”或者被严重拖慢。这就叫 CPU 资源过载 (over-subscription),顾头(GPU)不顾尾(CPU),整体效率大打折扣。
通俗比方 (The Analogy)
- 想象一个餐厅厨房(你的服务器),里面有两种厨师:
- 主厨 (CPU-heavy tasks):他们需要大量的案板、刀具和炉灶(CPU 核心),做一道复杂的菜(比如 Haystack 的 ENNS 检索)。
- 配菜员 (LLM-heavy tasks):他们的主要工作是把食材交给烤箱(GPU),自己只需要很小的操作台(一点点 CPU 资源)来准备食材。
- 如果你给每个配菜员都分配一个独立的、完整的操作间(multi-processing),那么很快厨房里就挤满了只占着茅坑不拉屎的配菜员,主厨们连站的地方都没有了,整个出餐速度就慢了下来。
- MAWS 的思路就是:给主厨们每人一个独立的操作间(multi-processing),但让配菜员们共享一个大的中央备餐区(multi-threading)。这样既保证了主厨有充足的空间干活,又避免了备餐区的资源浪费。
关键一招 (The "How")
- 作者并没有发明新的调度算法,而是巧妙地在任务分发前,先对任务进行类型感知 (type-aware) 的分类。
- 具体扭转点在于:将原来“一刀切”的 multi-processing 策略,替换为一个自适应的混合策略。
- 对于被识别为 CPU-heavy 的任务(如包含复杂工具调用的 LangChain pipeline),继续使用 multi-processing。这能绕过 Python 的 GIL 限制,让它们能真正并行地榨干多核 CPU 的性能。
- 对于被识别为 LLM-heavy 的任务(如简单的 guardrail + LLM inference),则改用 multi-threading。因为这类任务的 CPU 部分很轻,主要是 I/O 操作(比如调用 vLLM API),用线程池处理开销更小,不会过度消耗 CPU 核心。
- 这个简单的“分流”操作,释放了被 LLM-heavy 任务无谓占用的 CPU 资源,让 CPU-heavy 任务能跑得更快,从而提升了整个混合工作负载的 P99 延迟 和吞吐效率。
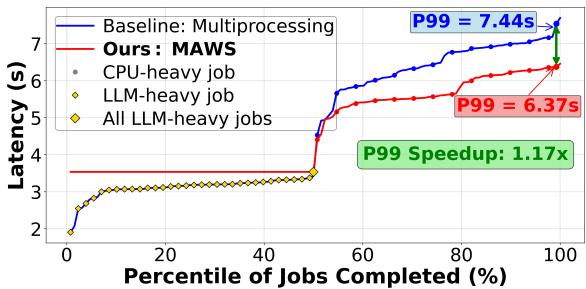 Figure 8. Comparison of MAWS against multiprocessing baseline on 128 mixed Langchain tasks (half LLM heavy, half CPU heavy)
Figure 8. Comparison of MAWS against multiprocessing baseline on 128 mixed Langchain tasks (half LLM heavy, half CPU heavy)
3. Agentic AI System Characterization Framework¶
痛点直击 (The "Why")
以前大家研究 Agentic AI,基本是从算法或应用层面看问题,比如“这个 Agent 能不能解化学题”或者“那个框架的 ReAct 逻辑好不好”。但这种视角有个致命盲区:它完全忽略了 系统层面的异构性。当你把一个 Agent 部署到真实服务器上跑起来,你会发现:
- 有些 Agent 的瓶颈在 GPU 上的 LLM 推理,而另一些的瓶颈却在 CPU 上的工具调用(比如检索、执行 Python 脚本)。
- 有些 Agent 的执行路径是固定的(比如先检索再生成),而另一些则像下棋一样,每一步都动态决定下一步做什么。
- 有些任务一锤子买卖(单步),有些则要反复试错、迭代十几次(多步)。
如果不对这些工作负载进行系统级的分类,你根本没法做有效的优化。你可能会花大力气去优化 GPU 推理,结果发现整个 pipeline 90% 的时间都卡在 CPU 上的 ENNS 检索——这就是典型的“顾头不顾尾”。所以,作者提出这个框架,就是为了把混沌的 Agentic AI 世界,用几条清晰的坐标轴划分清楚,让系统研究者能对症下药。
通俗比方 (The Analogy)
你可以把这个分类框架想象成给所有 Agentic AI 工作负载建立一个 “三维坐标系”,就像给动物分类用“脊椎/无脊椎”、“恒温/变温”、“胎生/卵生”一样。
- X 轴(Orchestrator):谁是“大脑”?是 LLM 自己在思考下一步该干嘛(比如 AutoGPT),还是由 Host(Python 代码) 在背后指挥 LLM 当一个听话的“打工人”(比如 LangChain)?
- Y 轴(Path):行动路线是 静态的(像工厂流水线,步骤固定),还是 动态的(像探险家,走到哪算哪,根据环境实时决策)?
- Z 轴(Repetitiveness):任务是一次性完成的 单步操作,还是需要多次“感知-规划-行动”循环的 多步过程?
通过这三个正交维度,任何一个复杂的 Agentic AI 系统都能被精准定位到这个立方体的某个角落,从而立刻暴露出它的计算特性和潜在瓶颈。
Figure 1. Characterization of agentic AI workloads on the basis of (a) Orchestrator (LLM and Host) (b) Agentic Path (Static and Dynamic) and (c) Repetitiveness (Single-step and Multi-step)
关键一招 (The "How")
作者并没有发明新的 Agent,而是巧妙地定义了三个正交的系统级属性,并用它们来解构现有的 Agentic AI 框架。具体来说:
- 替换了传统的、以“功能”或“领域”为中心的分类方式(比如“这是个 Web Agent”,“那是个多智能体系统”)。
- 扭转了分析视角,从“Agent 能做什么”转向了“Agent 是怎么做的”,聚焦于其底层的执行模式。
这三招组合起来,威力巨大:
- 基于编排器(Orchestrator):直接决定了 控制流是在 CPU 还是 GPU 上。LLM-orchestrated 的系统,LLM 本身要承担决策开销;而 Host-orchestrated 的系统,则把决策逻辑放在了 CPU 上,LLM 只负责纯推理。
- 基于路径(Path):静态路径的系统更容易做 Pipeline 并行和 Prefetching;而动态路径的系统则充满了 数据依赖和 分支不确定性,对调度器是巨大挑战。
- 基于重复性(Repetitiveness):单步系统可以简单批处理;而多步系统则会产生 长尾延迟和 状态管理开销,因为每个请求的迭代次数可能天差地别。
通过这个框架,作者就能有理有据地选出 Haystack, Toolformer, ChemCrow, LangChain, SWE-Agent 这五个极具代表性的 workload 进行剖析,因为它们恰好覆盖了这个三维空间的不同区域,从而保证了后续 profiling 结论的普适性和说服力。
4. Batching Cap Selection Strategy¶
痛点直击 (The "Why")
- 以前搞 Agentic AI 推理,大家习惯性地把所有请求一股脑塞进一个超大 batch(比如128),以为这样能最大化 GPU 利用率。
- 但现实很骨感:当 batch size 超过某个临界点后,吞吐量 的增长就变得极其缓慢,甚至停滞。与此同时,P50/P99 延迟 却会因为 CPU 过载(核心过订阅、上下文切换开销剧增)和 GPU 内存压力(KV Cache 膨胀导致带宽饱和或PCIe交换)而急剧恶化。
- 这种“顾此失彼”的做法,不仅浪费了宝贵的 CPU 资源 和 电力,还让一半用户的体验(P50)变得非常差。本质上,这是一种在 收益递减区 盲目堆砌资源的低效行为。
通俗比方 (The Analogy)
- 想象你在管理一个快递分拣中心。GPU 是高速分拣机,CPU 是负责把包裹从卡车上卸下来并放到传送带上的工人。
- 以前的做法是,不管工人有多少,一次性叫来128辆卡车同时卸货。结果呢?工人们挤作一团,互相挡路(CPU coherence/synchronization overhead),频繁地放下这个包裹去接那个(context switching),效率反而大打折扣。虽然分拣机一直在转,但前面的传送带却时断时续。
- Batching Cap Selection 的思路是:先做个小实验,看看每次增加一倍的卡车数量,整体处理速度能提升多少。一旦发现增加卡车带来的速度提升微乎其微(比如不到10%),就立刻停止增加。这个临界点就是 Bcap。这样,你就能用最精干的人手(CPU cores),让分拣机(GPU)保持在一个高效、稳定的节奏上工作。
关键一招 (The "How")
- 作者没有沿用“越大越好”的惯性思维,而是引入了一个量化指标——吞吐量增益比率 r(B)。
- 具体来说,他们通过实验测量不同 batch size 下的吞吐量 T(B),然后计算 r(B) = T(B) / T(B/2)。这个比率直接告诉你,把批处理大小翻倍,到底能换来多少实际的性能提升。
- 最巧妙的一步是,他们设定了一个效率阈值 λ(例如1.1)。一旦 r(B) < λ,就意味着继续增大 batch size 已经得不偿失,此时的 B 就被定为最优的 Bcap。
- 这个 Bcap 成为了后续 CGAM (CPU and GPU-Aware Micro-batching) 优化策略的基石。系统不再处理一个巨大的 batch,而是将其拆分成多个大小不超过 Bcap 的 micro-batch 来顺序或重叠处理,从而在保证高吞吐的同时,显著改善延迟和能效。
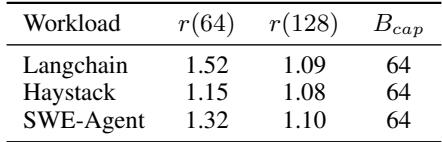 . Table 2. Throughput gain ratios r and selected Bcap values
. Table 2. Throughput gain ratios r and selected Bcap values
上表清晰地展示了这一策略的应用:对于 LangChain、Haystack 和 SWE-Agent 这三个 workload,当 batch size 从32增加到64时,r(B) 分别为1.83、1.91和1.85,收益尚可;但当从64增加到128时,r(B) 骤降至1.08、1.05和1.09,远低于阈值1.1。因此,Bcap = 64 被选为最优值,完美避开了收益递减区。
5. CGAMoverlap Execution Model¶
痛点直击 (The "Why")
- 传统的 CGAM (CPU and GPU-Aware Micro-batching) 虽然通过限制微批次大小(
Bcap)有效控制了 P50延迟 和资源消耗,但它采用的是严格的串行执行模式:必须等第一个微批次完全跑完(CPU + GPU),才开始第二个。 - 这种“等全完事再开工”的模式,在面对长尾请求时非常难受。对于第二个微批次里的请求,它们的等待时间被白白拉长了,导致 P90/P99延迟 居高不下,用户体验不均衡。
通俗比方 (The Analogy)
- 想象一个汽车装配线,有两个工位:工位A(CPU) 负责安装发动机,工位B(GPU) 负责喷漆。
- 标准CGAM 的做法是:第一辆车必须在A和B都做完,第二辆车才能进A工位。结果就是,第二辆车在A工位门口干等第一辆车喷完漆。
- CGAMoverlap 则聪明得多:只要第一辆车装完发动机(离开A工位),第二辆车立刻就能进去装自己的发动机。此时,第一辆车正在B工位喷漆,第二辆车在A工位装发动机,两个工位并行工作。虽然第二辆车最终出厂(完成全部流程)的时间可能只快了一点点(对P50影响不大),但它不用再干等,所以它的总等待时间大大缩短了,这对最慢的那几辆车(P90)是巨大的福音。
Figure 6. Timeline of batched agentic AI inference for (a) Multiprocessing, (b) CGAM, and (c) CGAMoverlap
关键一招 (The "How")
- 作者并没有改变微批次的基本结构,而是巧妙地扭转了微批次之间的调度逻辑。
- 具体来说,调度器不再等待一个微批次的 end-to-end latency 完成,而是在监控到该微批次的 CPU-bound stage 结束后,就立即触发下一个微批次的 CPU-bound stage。
- 这个操作的核心在于利用了 CPU和GPU的异构性:当GPU正忙于处理第一个微批次的推理时,CPU其实已经空闲出来,可以立刻为下一个微批次服务。通过这种流水线式的重叠,系统整体的吞吐效率和尾部延迟得到了优化。
- 当然,天下没有免费的午餐。这种重叠会带来轻微的 CPU contention(因为两个微批次的CPU阶段可能会有短暂交叠),所以 P50延迟 会比标准CGAM略差一点,但换来的是显著的 P90延迟 改善,这是一个非常务实的权衡。