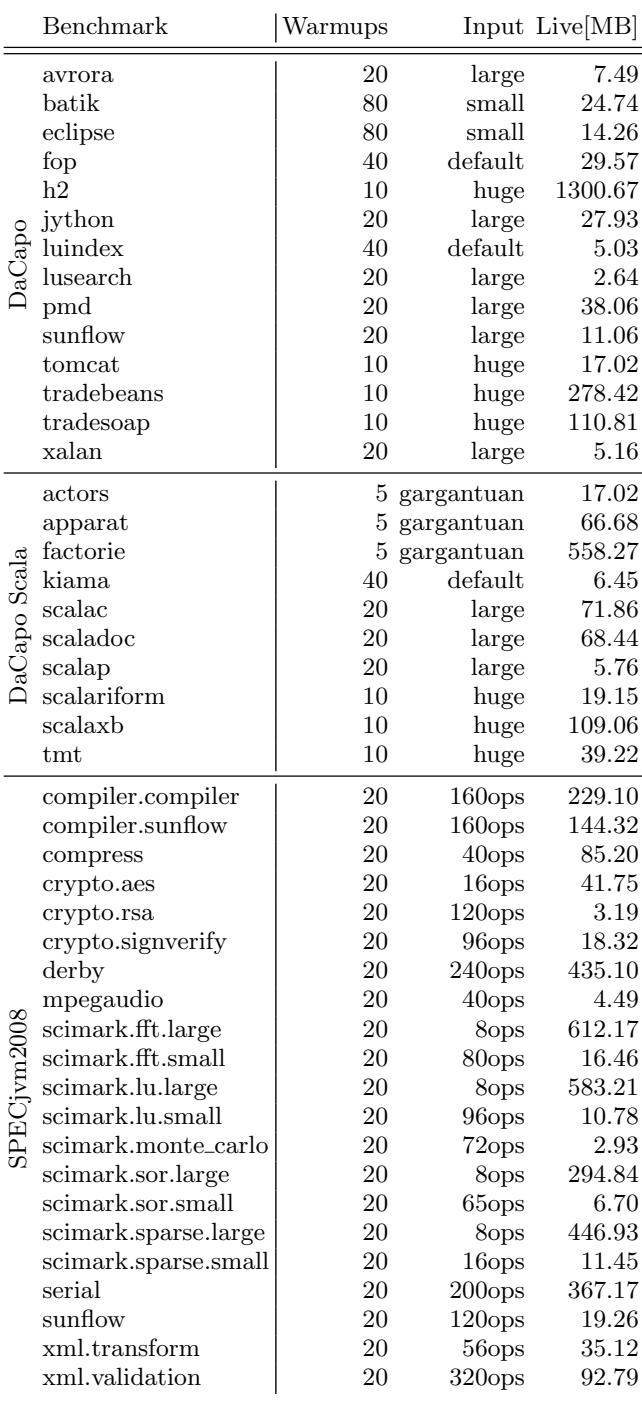
A Comprehensive Java Benchmark Study on Memory and Garbage Collection Behavior of DaCapo, DaCapo Scala, and SPECjvm2008 论文解析¶
0. 论文基本信息¶
作者 (Authors): Philipp Lengauer, Verena Bitto, Hanspeter Mössenböck, et al.
发表期刊/会议 (Journal/Conference): ICPE
发表年份 (Publication Year): 2017
研究机构 (Affiliations): Institute for System Software, Johannes Kepler University Linz, Austria, Christian Doppler Laboratory MEVSS, Johannes Kepler University Linz, Austria
1. 摘要¶
目的
- 对广泛使用的 Java 基准测试套件(DaCapo、DaCapo Scala 和 SPECjvm2008)在现代虚拟机上的 内存行为 和 **垃圾回收 **(GC) 进行全面分析。
- 为研究人员提供一份实用指南,以便根据所需的应用程序特性(如分配率、GC压力等)选择合适的基准测试,并帮助正确解读基于这些基准测试的研究结果。
- 比较 Java 当时的默认 GC(ParallelOld GC)与 G1 GC 的行为差异。
方法
- 基准测试: 使用 DaCapo (v9.12)、DaCapo Scala (v0.1.0) 和 SPECjvm2008 套件中的所有基准测试。为每个基准测试确定其 live size(最大存活对象大小),并通过二分搜索法找到能使其无
OutOfMemoryError运行的最小堆大小。 - 实验配置: 主要实验在 3倍 live size 的自适应堆限制下进行。同时也在 1GB 固定堆和无限制堆下进行了对比实验(见附录)。
- 测量工具: 采用 AntTracks,一个基于 OpenJDK 8u102 的低开销(约4%)、高精度的内存监控工具,它通过修改 VM 内部直接记录内存事件,避免了传统工具的观察者效应。
- 执行流程: 每个基准测试执行 50 次稳态运行,报告最佳(最短运行时间)结果。在每次测量前强制进行一次 GC 以清除预热阶段的残留。使用 20 次(或根据输入规模调整)预热迭代以确保 JIT 编译和 GC 参数稳定。
- 硬件环境: Intel Core i7-4770 CPU, 32GB RAM, Ubuntu 15.10。
结果
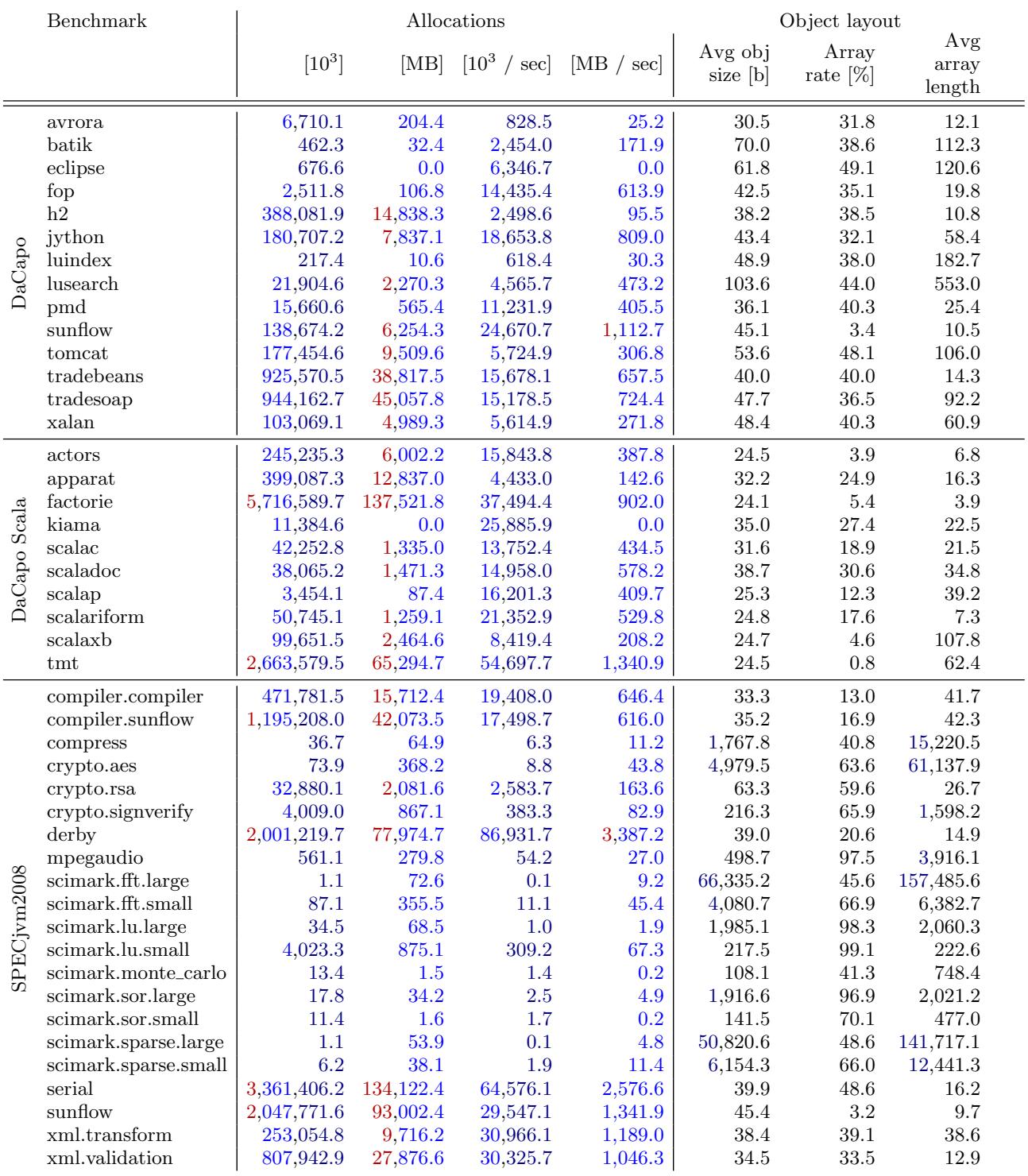
- 分配行为:
- 总分配量: factorie, serial, tmt, **sunflow **(SPECjvm2008) 和 derby 是分配最密集的基准测试,其中 factorie 和 sunflow 单次迭代可分配高达 137GB 和 134GB 的内存。
- 分配速率: derby, serial, tmt, factorie 和 xml.transform 具有最高的对象分配速率,可达 3×10⁷ 对象/秒。
- 对象布局: SPECjvm2008 基准测试倾向于创建更长的数组。数组对象比例差异巨大,从 **sunflow **(SPECjvm2008) 的 3.2% 到 mpegaudio 的 97.5%。
- 分配子系统:
- 大多数基准测试在测量阶段主要由 C2 编译代码 执行分配,表明预热充分。
- scimark.* 系列基准测试因计算密集、分配稀疏,仍有大量分配发生在 解释执行代码 中。
- lusearch 和 pmd 基准测试因在正常控制流中滥用异常,导致 VM-internal allocations(主要是
fillInStackTrace创建的栈跟踪数组)占比极高(分别达 13.7% 和 90%)。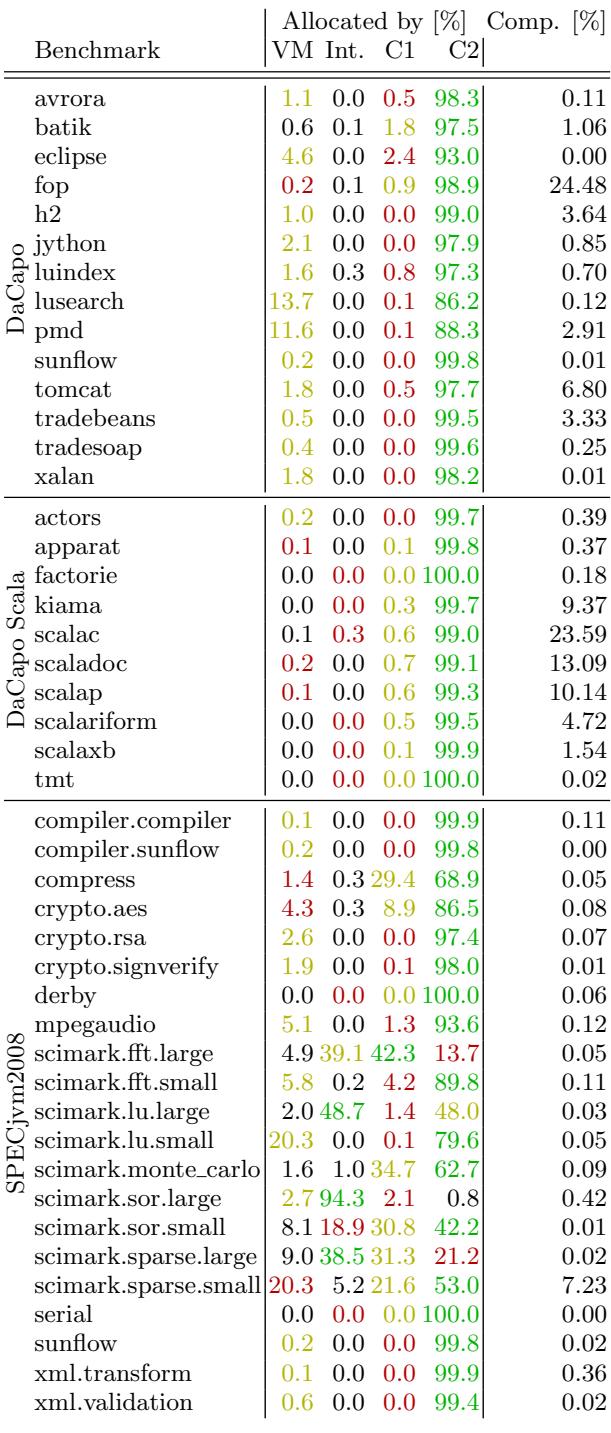 Figure 3: Objects allocated by VM-internal code, interpreted code, C1 compiled code, or by C2 compiled code respectively (green: 1st top allocator, yellow: 2nd top allocator, red: 3rd top allocator), as well as the time spent compiling in relation to the overall run time
Figure 3: Objects allocated by VM-internal code, interpreted code, C1 compiled code, or by C2 compiled code respectively (green: 1st top allocator, yellow: 2nd top allocator, red: 3rd top allocator), as well as the time spent compiling in relation to the overall run time
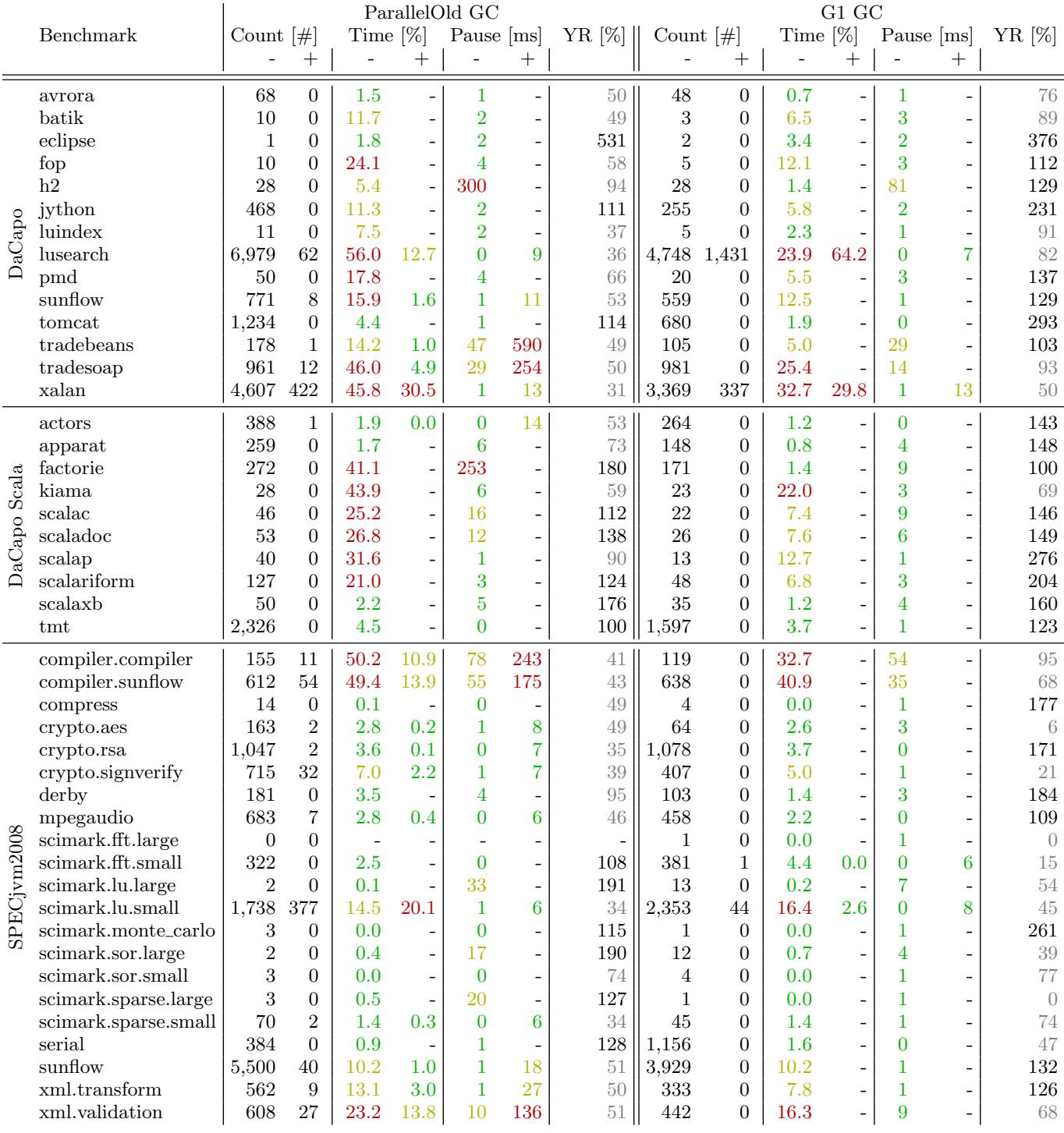
- 垃圾回收行为:
- GC 次数: 基准测试间差异巨大,从 scimark.fft.large(0次)到 lusearch(7041次)。G1 GC 通常比 ParallelOld GC 执行更少的 GC 次数。
- GC 时间: 部分基准测试(如 factorie)在 ParallelOld GC 下 GC 时间占比超过 50%,而 G1 GC 能显著降低此开销(factorie 从 41% 降至 1.4%)。
- GC 暂停: G1 GC 的 minor pause time 平均为 ParallelOld GC 的 71%,且暂停时间更稳定,峰值更低(例如 h2 基准测试:300ms vs 81ms)。
- 代际比率: G1 GC 倾向于维持更大的 young generation,与 ParallelOld GC 的策略不同。
- 对象引用: xalan, luindex, factorie, kiama 和 serial 因使用大型对象数组,表现出极高的 平均指针密度。h2 数据库基准测试因其海量指针,非常适合指针相关研究。
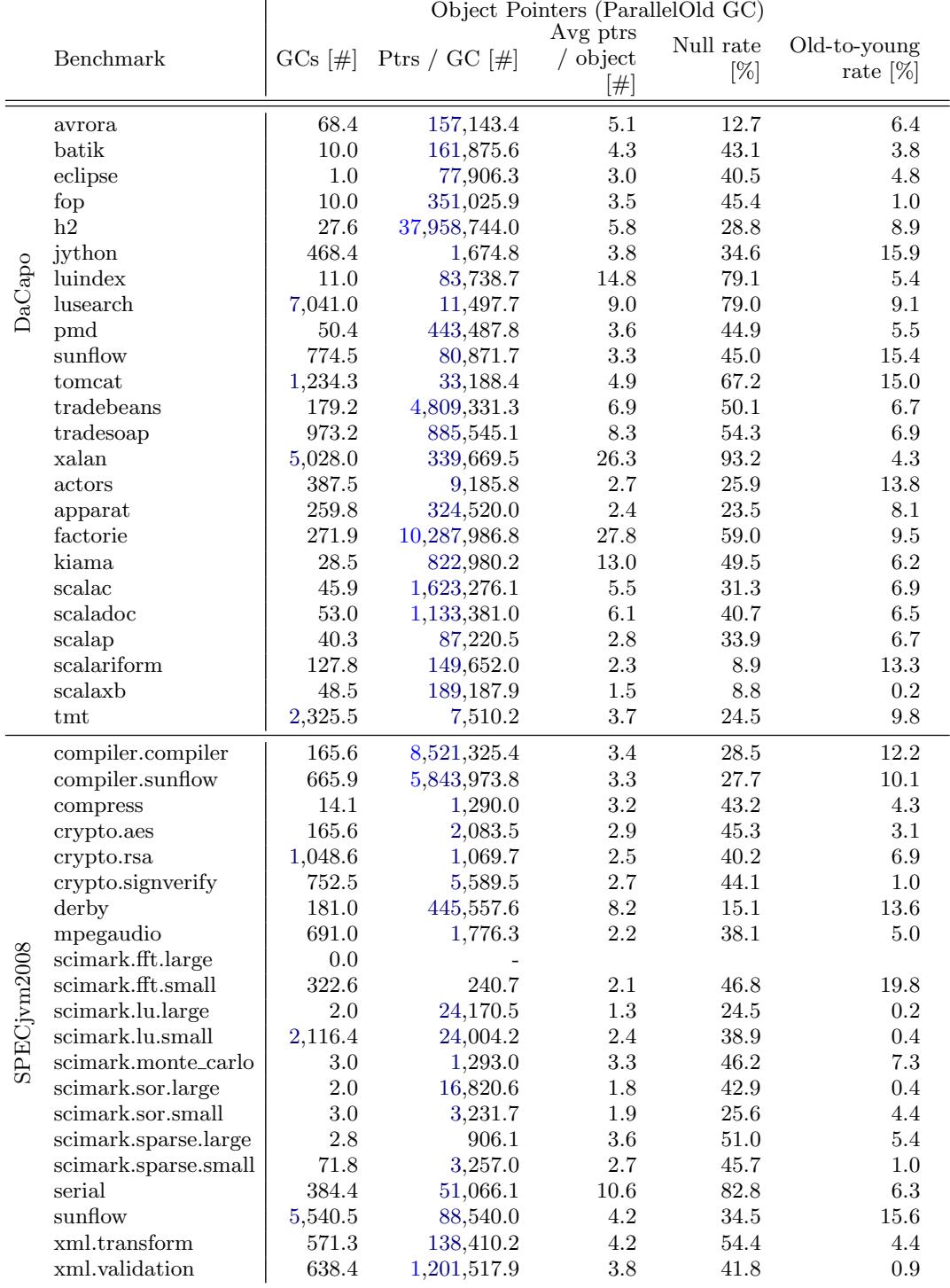 Figure 8: Object pointers per GC of all benchmarks
Figure 8: Object pointers per GC of all benchmarks
结论
- 该研究为 Java 基准测试套件提供了在现代 JVM 上的详细内存和 GC 行为画像,揭示了各基准测试的独特属性和潜在“陷阱”(如异常滥用、预热不足)。
- 研究人员可根据具体需求(如高分配率、长GC暂停、高指针密度等)精准选择最合适的基准测试,从而设计出更具说服力的实验。
- G1 GC 在处理大堆和高分配负载时,普遍优于 ParallelOld GC,表现为更低的 GC 开销和更短、更可预测的暂停时间,但其在小堆场景下可能表现不佳。
- 本工作强调了理解基准测试内在特性的重要性,以避免对实验结果的误读,并为未来 JVM、GC 算法和监控工具的开发与评估奠定了坚实基础。
2. 背景知识与核心贡献¶
研究背景
- Java benchmark suites(如 DaCapo、DaCapo Scala 和 SPECjvm2008)是评估虚拟机、编译器优化和垃圾回收(GC)算法性能的基石。
- 然而,这些套件的现有分析要么缺失,要么已过时。自其发布以来,Java 虚拟机、memory management 和 GC algorithms 已发生巨大演变,导致其在现代系统中的实际行为缺乏文档记录。
- 研究人员在选择基准测试或解释实验结果(尤其是异常值)时,常常因不了解基准程序的内在特性而陷入困境,甚至需要重复进行繁琐的特性分析。
研究动机
- 指导基准选择:为研究人员提供一份详尽的指南,使其能根据目标应用的desired application characteristics(如内存压力、对象生命周期)来选择最合适的基准测试。
- 结果解读与评估:帮助研究人员和审稿人更好地理解并评估基于这些基准测试的研究工作,避免因对基准特性无知而导致的误判。
- 揭示隐藏特性:系统性地暴露常用基准测试中不为人知的“curiosities”(如通过异常处理正常控制流),这些特性可能会严重影响性能测量结果。
核心贡献
- 对三大主流 Java 基准套件(DaCapo, DaCapo Scala, SPECjvm2008)进行了全面的memory behavior和GC behavior分析。
- 基于关键指标(如allocated memory, survivor ratios, live sizes, garbage collection times)对基准测试进行了分类,并指明了各类别最适合的研究场景。
- 采用低开销、高精度的内存监控工具 AntTracks 进行测量,有效规避了传统监控工具因observer effect而对应用行为造成的显著扭曲。
- 提供了 ParallelOld GC(当时默认)与 G1 GC(Java 9 默认)在相同基准下的详细对比,为 GC 算法的选择和调优提供了实证依据。
- 揭示了多个重要发现,例如:
lusearch和pmd基准通过异常(Exception)处理正常控制流,导致大量 VM-internal allocations。scimark系列基准由于其计算密集型特性,在标准预热后仍有大量代码未被 JIT 编译。- 不同 GC 算法(如 ParallelOld 与 G1)在young generation ratio和GC pauses上表现出显著差异。
- Figure 3: Objects allocated by VM-internal code, interpreted code, C1 compiled code, or by C2 compiled code respectively (green: 1st top allocator, yellow: 2nd top allocator, red: 3rd top allocator), as well as the time spent compiling in relation to the overall run time
3. 核心技术和实现细节¶
0. 技术架构概览¶
研究目标与核心方法
- 本文旨在对 DaCapo、DaCapo Scala 和 SPECjvm2008 这三大主流 Java 基准测试套件进行一次全面的 内存行为 (Memory Behavior) 和 垃圾回收行为 (GC Behavior) 分析。
- 核心目标是为研究人员提供一份详尽的指南,帮助他们根据所需的应用特性(如高分配率、长GC暂停等)来选择合适的基准测试,并能正确解读基于这些基准测试得出的实验结果。
- 为实现低干扰、高精度的测量,研究采用了名为 AntTracks 的专用监控工具。该工具直接集成在 HotSpot VM 内部,通过记录高效的内存事件追踪日志来获取数据,其运行时开销极低(约 4%),有效避免了传统监控工具因 observer effect 而导致的行为失真。
实验配置与执行流程
- 硬件环境: Intel Core i7-4770 CPU, 32GB RAM, Ubuntu 15.10。
- 软件环境: 基于 OpenJDK 8u102 的 AntTracks VM。
- 基准测试配置:
- 使用 自适应堆大小 (adaptive heap limit),即堆上限设为各基准测试 live size(存活对象峰值)的 3倍。
- 执行充分的 预热 (warmup) 阶段(通常为20次迭代),以确保 JIT 编译、GC 自调优和缓存均达到稳定状态。
- 最终性能数据取自 50次稳态运行 中的最佳值(最短运行时间)。
- 垃圾回收器对比: 主要分析使用 ParallelOld GC(当时 HotSpot 的默认收集器),并将结果与 G1 GC(Java 9 的默认收集器)进行对比,后者的数据主要放在附录中。
分析维度与关键指标
- 分配行为 (Allocation Behavior):
- 总分配量: 统计单次迭代中分配的 对象总数 和 字节总量。
- 分配速率: 计算每秒分配的 对象数 和 字节数。
- 对象布局: 分析 平均对象大小、数组对象占比 及 平均数组长度。
- 分配子系统 (Allocating Subsystems):
- 追踪对象是由 VM内部代码、解释执行代码、C1编译代码 还是 C2编译代码 所分配。
- 测量 JIT编译时间 占总运行时间的比例。
- 垃圾回收行为 (Garbage Collection Behavior):
- GC次数: 区分 Minor GC 和 Major GC 的触发频率。
- GC时间: 应用程序花费在 GC上的总时间占比。
- GC暂停: Minor 和 Major GC 的 平均暂停时间。
- 新生代比率 (Young Generation Ratio): 新生代与老年代在GC前的最大内存占用比。
- 对象引用 (Object References):
- 分析每个对象的 平均指针数量 (pointer density),以评估其引用复杂度。
Figure 3: Objects allocated by VM-internal code, interpreted code, C1 compiled code, or by C2 compiled code respectively (green: 1st top allocator, yellow: 2nd top allocator, red: 3rd top allocator), as well as the time spent compiling in relation to the overall run time
Figure 8: Object pointers per GC of all benchmarks
关键发现与洞见
- 不同基准测试在内存和GC特性上差异巨大。例如,factorie 和 sunflow 是 分配最密集 的基准,而 scimark 系列则分配压力很小。
- 某些基准存在特殊行为,如 lusearch 和 pmd 通过 异常 (Exceptions) 来控制正常程序流,导致大量 VM内部对象(用于填充堆栈跟踪)被分配。
- G1 GC 在大多数情况下表现优于 ParallelOld GC,尤其是在 减少GC暂停时间 和 降低总GC时间 方面。但 G1 在 小堆 场景下效率不高,会更频繁地触发 Major GC。
- scimark 基准由于其计算密集型特性,在标准预热后仍有大量代码未被 C2编译器 优化,这揭示了现有预热策略的局限性。
1. AntTracks Memory Monitoring Tool¶
AntTracks 内存监控工具的核心原理与实现
- 直接集成于 VM 内部:AntTracks 并非一个外部代理或基于 JVMTI 的重型工具,而是通过直接修改 HotSpot VM 源码(基于 OpenJDK 8u102)来实现。这种深度集成使其能够访问 VM 最底层的内存分配和垃圾回收事件。
- 高效的追踪格式 (Efficient Trace Format):工具在 VM 内部生成一个非常紧凑的事件追踪日志。为了最小化运行时开销,该日志会省略所有可以在离线后重建的信息,只记录最核心的、无法推导的原始事件。
- 完整的对象级追踪 (Complete Object-level Trace):AntTracks 能够捕获每一个对象的分配以及每一次内部 GC 操作,确保追踪数据的完整性,不会遗漏任何内存事件。
- 规避传统监控的性能陷阱:
- 无需重型插桩 (Heavy-weight Instrumentation):因为它内置于 VM,所以不需要像外部工具那样对字节码进行插桩。这避免了插桩对 Escape Analysis 等 JIT 优化的干扰。
- 无需 WeakReference 或 Finalizer:传统工具常利用
WeakReference或finalize()方法来探测对象死亡,但这会给 GC 带来巨大额外负担。AntTracks 通过直接监听 GC 内部操作来获取对象死亡信息,完全绕开了这一机制。
- 极低的运行时开销:得益于上述设计,AntTracks 引入的整体运行时开销仅为约 4%,这在对象级精度的内存监控工具中是极为出色的。
工作流程与输入输出
- 输入:目标 Java 应用程序的正常执行。
- 处理流程:
- 在 VM 修改后的执行过程中,每当发生内存事件(如对象分配、GC 回收),VM 内核会高效地生成一条紧凑的追踪记录。
- 这些记录被写入一个追踪文件 (trace file)。
- 执行结束后,一个专用的离线后处理工具 (dedicated offline tool) 会读取这个追踪文件。
- 该后处理工具利用其对 VM 内部逻辑的了解,重建出完整的、详细的内存行为视图,包括所有被省略的上下文信息。
- 输出:一个包含完整内存事件细节的数据集,可用于提取各种高级指标,例如:
- 总分配量 (Total Allocations)
- 幸存者比率 (Survivor Ratios)
- 顶级分配站点 (Top Allocation Sites)
- 对象指针关系 (Object Pointers)
在研究中的作用
- 提供高保真度的基准数据:由于其低开销和高精度,AntTracks 成为分析现代 JVM 上基准套件真实内存行为的理想工具。它能有效避免“观察者效应 (observer effect)”,即监控工具本身扭曲了被测应用的行为。
- 支撑多维度分析:论文中关于分配行为、编译代码的分配比例、GC 行为以及对象引用等所有核心结论,都依赖于 AntTracks 提供的精确数据。
- 验证方法论的基石:研究者选择 AntTracks 正是为了克服其他状态-of-the-art 工具的局限性,从而确保其对 DaCapo、DaCapo Scala 和 SPECjvm2008 基准套件的分析结果是可靠且具有说服力的。
2. Benchmark Categorization by Memory/GC Behavior¶
核心观点
该研究通过对 DaCapo、DaCapo Scala 和 SPECjvm2008 三大主流 Java 基准测试套件进行深度剖析,依据其 内存行为 (Memory Behavior) 与 垃圾回收行为 (GC Behavior) 的关键指标,对其中的各个 benchmark 进行了系统性分类。这种分类旨在为研究人员提供一份精准的“选型指南”,使其能根据特定的研究目标(如测试高分配率、长 GC 暂停或大对象分配等)选择最合适的 benchmark,从而避免因 benchmark 特性不明而导致的实验偏差或结论误判。
分类所依据的核心指标与实现原理
-
总分配量 (Total Allocations):
- 原理: 统计单次稳态迭代中分配的对象总数和字节总量。
- 作用: 识别对 GC 造成巨大压力的 benchmark。高分配量是测试新分配器、内存监控工具开销的理想场景。
- 代表 benchmark: factorie, serial, tmt, sunflow (SPECjvm2008), derby。其中 factorie 和 sunflow 单次迭代可分配高达 137GB 和 134GB 的内存。
-
分配速率 (Allocation Rate):
- 原理: 计算单位时间内(每秒)分配的对象数和字节数(
总分配量 / 运行时间)。 - 作用: 直接影响 GC 频率。高分配速率对硬件 I/O(如监控工具写盘)和 GC 算法调优至关重要。
- 代表 benchmark: derby, serial, tmt, factorie, xml.transform。最高可达 3 * 10^7 个对象/秒。
- 原理: 计算单位时间内(每秒)分配的对象数和字节数(
-
存活集大小 (Live Set Size):
- 原理: 通过二分法找到能成功运行 benchmark 的最小
-Xmx值,以此作为其最大存活对象的近似值。 - 作用: 用于设置自适应堆大小(实验中设为
3 * Live Set Size),确保所有 benchmark 在公平且有压力的内存环境下运行。
- 原理: 通过二分法找到能成功运行 benchmark 的最小
-
GC 行为指标:
- GC 次数 (GC Count):
- 原理: 统计 Minor GC 和 Major GC 的总触发次数。
- 作用: 测试依赖于 GC 事件的监控工具或算法。高 GC 次数意味着频繁的 Stop-The-World 暂停。
- 代表 benchmark: lusearch (高达 7041 次);而 scimark.fft.large 则无任何 GC。
- GC 时间占比 (GC Time):
- 原理: 计算 GC 暂停时间占总运行时间的百分比。
- 作用: 量化 GC 对应用性能的整体影响。某些 benchmark 超过 50% 的时间花在 GC 上。
- 代表 benchmark: factorie 在 ParallelOld GC 下 GC 时间占比高达 41%,而在 G1 GC 下仅为 1.4%,凸显了 GC 算法选择的重要性。
- GC 暂停时间 (GC Pauses):
- 原理: 测量每次 Minor/Major GC 的平均暂停时长。
- 作用: 对延迟敏感型应用(如 UI、服务器)至关重要。用于评估并发或低延迟 GC 算法的有效性。
- 观察: G1 GC 的平均 Minor 暂停时间仅为 ParallelOld GC 的 71%,且波动更小。例如 h2 benchmark,ParallelOld 平均暂停 300ms,而 G1 仅为 81ms。
- GC 次数 (GC Count):
Benchmark 分类与研究目标映射
| 研究目标 | 推荐的 Benchmark | 关键指标依据 |
|---|---|---|
| 测试高分配压力下的 GC/分配器 | tmt, serial, factorie, derby | 极高的 总分配量 和 分配速率 |
| 测试对象寿命短、回收快的场景 | tmt, serial | 高分配量 + 高 GC 频率,表明对象多为朝生夕死 |
| 测试老年代压缩/整理算法 | derby | 高分配量 + 对象寿命长,导致老年代压力大 |
| 测试高 GC 开销下的监控工具 | factorie, lusearch | 极高的 GC 时间占比 |
| 测试长 GC 暂停及低延迟 GC | h2, tradebeans | tradebeans 在 ParallelOld 下有 590ms 的 Major GC 暂停,而 G1 完全避免了 Major GC |
| 测试大对象/大数组分配 | scimark.fft.large, SPECjvm2008 (compress, crypto.*, mpegaudio) | scimark.fft.large 分配最大单个对象;SPECjvm2008 普遍具有高平均数组长度 |
| 测试高指针密度场景 | xalan, luindex, factorie, kiama, serial, h2 | h2 因其极高的对象指针数量,成为指针相关研究的理想选择 |
值得注意的异常行为 (Curiosities)
- 异常控制流: lusearch 和 pmd benchmark 将 Exception 用于正常控制流。这导致大量调用
java.lang.Throwable.fillInStackTrace(),产生了巨量的 VM-internal allocations(主要是栈跟踪相关的数组),严重扭曲了其真实的内存分配画像。 - 预热不足: 尽管遵循了官方预热建议,SPECjvm2008 中的 scimark.* 系列 benchmark 仍有相当一部分对象由未编译的解释执行代码分配。这是因为其计算密集、分配稀疏的特性,使得 JIT 编译器难以在预热阶段将其热点方法完全编译优化。
测量方法论保障
- 低干扰监控: 使用 AntTracks 工具进行数据采集。该工具直接集成于 HotSpot VM 内部,通过高效的追踪格式记录内存事件,仅引入约 4% 的运行时开销,有效规避了传统监控工具因重度插桩导致的 observer effect(观察者效应)。
- 稳态性能: 所有数据均基于 50 次 稳态运行,并报告最佳运行结果(最短运行时间),以排除 JIT 编译、缓存预热等因素的干扰。
- 公平的堆配置: 采用 自适应堆大小(
3 * Live Set Size),而非固定堆大小,确保不同内存需求的 benchmark 都能在有代表性的压力下运行。
3. VM-Internal Allocation Analysis¶
VM-Internal Allocation Analysis 的核心目的与原理
- 该分析旨在通过量化 VM-internal code(虚拟机内部代码)、interpreted code(解释执行代码)、C1 compiled code(客户端编译器编译的代码)和 C2 compiled code(服务端编译器编译的代码)所产生的对象分配比例,来评估基准测试(benchmark)的 warmup quality(预热质量)。
- 其基本原理是:一个充分预热的 Java 应用,其绝大部分工作负载(尤其是对象分配)应由高度优化的 C2 compiled code 执行。如果仍有大量分配发生在 interpreted code 或 C1 compiled code 中,则表明 JIT 编译尚未稳定,测量结果可能包含编译开销,不能代表 peak performance(峰值性能)。
- VM-internal allocations 是指由 JVM 本身(而非应用字节码)触发的分配,例如为维持堆结构而创建的 filler objects,或由 native methods(本地方法)触发的分配。
关键发现:异常的 VM-Internal Allocation 案例
- 研究识别出两个因 反模式编程 而导致 VM-internal allocation 异常高的基准测试:
- lusearch: 其 13.7% 的对象分配来自 VM 内部。根本原因是该程序在 normal control flow(正常控制流)中滥用 Exceptions(异常)。每次抛出
Throwable时,其构造函数会调用本地方法fillInStackTrace(),该方法会遍历调用栈并分配多个 Object, short, 和 int 数组来存储栈帧信息。- Figure 3: Objects allocated by VM-internal code, interpreted code, C1 compiled code, or by C2 compiled code respectively (green: 1st top allocator, yellow: 2nd top allocator, red: 3rd top allocator), as well as the time spent compiling in relation to the overall run time
- pmd: 情况类似,约 90% 的 VM-internal 对象分配源于填充异常的栈跟踪。其余部分则来自使用 URLClassLoader 查找类时创建的 String 及其内部的 char[] 数组。
- lusearch: 其 13.7% 的对象分配来自 VM 内部。根本原因是该程序在 normal control flow(正常控制流)中滥用 Exceptions(异常)。每次抛出
Warmup Quality 评估与 JIT 编译行为
- 除 SPECjvm2008 中的部分 scimark.* 基准测试外,所有其他基准测试均被判定为 properly warmed up(已充分预热),因为它们的分配主要由 C2 compiled code 完成。
- scimark.* 基准测试(如
scimark.fft.large)之所以例外,是因为:- 它们执行的是 long-running methods(长时间运行的方法),进行密集的数值计算(number crunching)。
- 这类方法需要较长时间才能累积足够的 execution counters(执行计数器)以触发 JIT 编译。
- 尽管如此,由于它们的 allocation rate(分配率)极低,对内存子系统压力很小,因此其预热不足的问题在内存/GC研究中影响不大。
- Compile time ratio(编译时间比率)指标进一步佐证了这一点。对于
fop,scalac,scalap等基准,尽管分配已由编译代码执行,但 compile time ratio 仍然很高,暗示若要精确测量运行时性能,可能需要更长的预热周期。
输入、输出与在整体研究中的作用
- 输入: 基准测试的执行轨迹,由 AntTracks 工具捕获。AntTracks 通过修改 HotSpot VM 内核,在对象分配和 GC 事件发生时记录详细信息,包括分配点的 code state(代码状态:VM-internal, interpreted, C1, C2)。
- 输出:
- 各 code state 下的对象分配数量及占比。
- Compile time ratio(编译时间占总CPU时间的比例)。
- 在整体研究中的作用:
- 验证实验有效性: 确保所报告的性能数据是在 steady-state(稳定状态)下测得,排除了 JIT 预热阶段的干扰。
- 揭示基准测试缺陷: 暴露了
lusearch和pmd等基准中存在的非典型行为(滥用异常),提醒研究者在解读基于这些基准的结果时需格外谨慎。 - 指导基准选择: 为需要特定 JIT 行为(例如,研究解释器性能 vs. C2 编译器性能)的研究提供了选择依据。
4. Garbage Collection Behavior Comparison¶
核心观点:ParallelOld GC 与 G1 GC 的行为差异
- 研究背景:该论文在 现代 JVM(OpenJDK 8u102) 上,使用 自适应堆大小(3倍 live size) 的配置,对 ParallelOld GC(Java 8 默认)和 G1 GC(Java 9+ 默认)进行了全面的行为对比。
- 测量工具:所有数据均基于 AntTracks 工具采集,该工具通过修改 HotSpot VM 内部实现,以极低的 ~4% 运行时开销 提供了精确到对象级别的内存事件追踪,有效避免了传统监控工具因 observer effect 导致的行为失真。
垃圾回收次数 (GC Count)
- 总体相关性:两种 GC 算法的 总回收次数(minor + major)呈现出高达 97% 的线性 Pearson 相关性,表明应用的分配压力是决定 GC 频率的主要因素。
- G1 的优势:
- 在绝大多数基准测试中,G1 GC 执行的回收次数少于 ParallelOld GC。
- 原因:G1 采用 region-based 的堆布局,其 mixed GC 阶段可以选择性地回收包含最多垃圾的 young 和 old regions,从而在单次回收中释放更多内存,减少回收频率。
- 例外情况:在
compiler.sunflow,crypto.rsa,scimark.*,serial等少数基准测试中,G1 的回收次数反而更多,这可能与其 remembered sets 维护开销或特定分配模式有关。 - Major GC 行为差异:
- ParallelOld GC:在 young generation 耗尽且无法为晋升对象找到足够空间时,会触发 stop-the-world 的 Full GC(即 major collection)。
- G1 GC:将 major collection 视为 紧急措施(emergency action),仅在并发标记无法跟上分配速度、堆即将耗尽时才会触发。因此,在实验中 G1 仅在
lusearch,xalan,scimark.fft.small,scimark.lu.small这四个 live set 极小 的基准测试中出现了 major GC,表明 G1 并非为小堆场景优化。
总垃圾回收时间 (Total GC Time)
- 关键发现:某些基准测试(如
factorie)在 ParallelOld GC 下,超过 50% 的总运行时间 花费在 GC 上,凸显了 GC 开销的重要性。 - G1 的显著优势:在高 GC 开销的场景下,G1 表现尤为出色。例如,
factorie在 ParallelOld GC 下 GC 时间占比为 41%,而在 G1 GC 下仅为 1.4%。 - 原因分析:
- 并行与并发:G1 的大部分工作(如 concurrent marking)是与应用线程并发执行的,只有 evacuation pause(相当于 minor GC)和 full GC 是 stop-the-world 的。
- 高效回收:通过优先回收高垃圾密度区域,G1 能更高效地利用 CPU 资源,减少总的暂停时间。
GC 暂停时间 (GC Pauses)
- Minor GC 暂停:G1 GC 的平均 minor 暂停时间仅为 ParallelOld GC 的 71%。例如,
h2基准测试在 ParallelOld GC 下平均暂停 300ms,而在 G1 GC 下仅为 81ms。 - Major GC 暂停:G1 通过避免 Full GC,极大地减少了长暂停。最极端的例子是
tradebeans,ParallelOld GC 有 590ms 的 major GC 暂停,而 G1 GC 则完全没有触发 major GC。 - 设计目标:G1 的核心设计目标之一就是提供 可预测的暂停时间。它通过 -XX:MaxGCPauseMillis 参数(默认 200ms)来指导其回收策略,使其非常适合对 响应延迟敏感 的应用(如 UI 或服务器应用)。
年轻代比率 (Young Generation Ratio)
- 定义:该比率指 young generation 最大容量 与 old generation 最大容量 的比值。
- 行为差异:
- G1 GC 通常维持一个 相对更大 的 young generation(比率常高于 100%)。
- ParallelOld GC 则倾向于保持一个 相对更小 的 young generation。
- 影响:更大的 young generation 意味着 G1 可以让对象在 young regions 中经历更多次的 GC 周期,从而有更多机会在晋升到 old generation 前就被回收,这有助于减少 old generation 的压力和后续的 Full GC 风险。
| 维度 | ParallelOld GC | G1 GC |
|---|---|---|
| 堆模型 | 分代(Generational),连续内存(young/old) | Region-based,逻辑分代 |
| Major GC 触发 | Young GC 后 old 区无足够空间容纳晋升对象 | Concurrent marking 失败,堆即将耗尽(紧急措施) |
| GC 次数 | 通常更高 | 通常更低(因选择性回收) |
| 总 GC 时间 | 在高分配压力下可能非常高(>50%) | 通常显著更低,尤其在高压力场景 |
| 暂停时间 | Minor 和 Major GC 均为 stop-the-world,Major GC 暂停很长 | 主要暂停来自 evacuation pause,可预测且较短;Major GC 极其罕见 |
| 适用场景 | 吞吐量优先、可接受长暂停的应用 | 延迟敏感、需要可预测暂停时间的应用 |
总结与启示
- 基准测试选择:研究者应根据目标特性选择合适的基准测试。例如,评估 高分配率 下的 GC 性能,应选用
derby,serial,tmt;评估 大对象/数组 处理能力,应关注 SPECjvm2008 中的scimark.*或compress。 - 算法选型:对于 现代 Java 应用,尤其是那些对 服务可用性 和 响应延迟 有要求的应用,G1 GC 凭借其 可预测的暂停时间 和在 大堆 上的优异表现,通常是比 ParallelOld GC 更优的选择。
- 理解异常行为:论文揭示了一些基准测试的“怪癖”,如
lusearch和pmd通过 异常(Exception) 进行正常控制流,导致大量 VM-internal allocations(主要是fillInStackTrace产生的数组)。这类行为会严重干扰 GC 和性能分析,必须在解读结果时加以考虑。
5. Object Reference and Pointer Density Measurement¶
核心观点
- 该研究通过 AntTracks 工具对 Java 应用在 Garbage Collection (GC) 过程中产生的 object pointers(对象指针) 进行了精确追踪与统计。
- 核心度量指标是 average number of pointers per object(每个对象的平均指针数),该指标直接反映了应用的 pointer density(指针密度)。
- 测量并非在整个程序运行期间持续进行,而是 仅在 GC 事件发生时 记录指针信息。因此,记录到的指针总量与 GC 次数 直接相关。
实现原理与算法流程
- AntTracks 是一个基于 HotSpot VM 的定制化虚拟机,它通过在 VM 内部直接修改 GC 算法 来高效地生成内存事件追踪日志。
- 在每次 GC 执行对象图遍历(tracing) 时,AntTracks 会记录下从存活对象出发所访问到的所有 object references(对象引用/指针)。
- 这些指针数据被编码成一种 非常紧凑的事件追踪格式,以最小化运行时开销(文中提到开销约为 4%)。
- 事后,一个专用的离线分析工具会处理这些追踪日志,重建完整的对象图,并计算出 每个对象持有的指针数量,最终得出全局的 平均指针数。
高指针密度的成因与典型基准
- 通常情况下,Java 对象的 平均指针数 是一个较小的值(文中描述为 monadic,即接近1)。
- 然而,某些特定的基准测试表现出异常高的指针密度,其根本原因在于它们大量使用了 few, but very large arrays to store objects(少量但非常大的对象数组)。
- 这些大型数组中的每一个元素都是一个指向其他对象的指针,从而导致包含该数组的对象拥有极高的出边(outgoing pointers)数量,拉高了整体平均值。
- 文中明确指出的高指针密度基准包括:
- DaCapo:
xalan,luindex - DaCapo Scala:
factorie,kiama - SPECjvm2008:
serial
- DaCapo:
- 特别地,DaCapo 的
h2基准 因其庞大的指针总量,被作者推荐为进行 所有类型指针相关测量 的理想选择。
输入输出关系及作用
- 输入: AntTracks 生成的、包含 GC 期间所有对象指针事件的原始追踪日志。
- 输出: 一个量化指标——每个对象的平均指针数,以及识别出的具有高指针密度的特定基准。
- 在整体研究中的作用:
- 该分析为研究人员提供了关于基准测试 内部数据结构复杂性 的关键洞察。
- 高指针密度的基准对于测试和评估 GC 的 tracing 效率、写屏障(write barrier)性能 以及 指针密集型应用的内存管理策略 至关重要。
- 它帮助解释了为何某些基准(如
h2)在 GC 行为上表现独特,从而避免在性能评估中产生误判。
Figure 8: Object pointers per GC of all benchmarks
4. 实验方法与实验结果¶
实验设置
- 基准测试套件: 研究聚焦于三个主流的 Java 基准测试套件:DaCapo (v9.12)、DaCapo Scala (v0.1.0-20120216.103539-3) 和 SPECjvm2008。
- 硬件环境: 实验在一台配备 Intel Core i7-4770 CPU @ 3.40GHz (8线程)、32GB RAM 和 Samsung SSD 840 PRO 的机器上进行,操作系统为 Ubuntu 15.10。
- JVM 与 GC 配置: 主要使用基于 OpenJDK 8u102 的 AntTracks VM。默认垃圾回收器(GC)为 ParallelOld GC,并与 G1 GC 进行了对比。堆大小被设置为各基准测试 live size(存活对象最大内存占用)的 三倍,以模拟一个自适应的、有压力但非受限的环境。
- 预热策略: 所有基准测试均经过充分预热,以确保 JIT 编译、GC 自调优 和 堆大小调整 达到稳定状态。预热次数通常为 20 次,根据具体基准的输入大小和稳定性进行了微调。
- 测量方法:
- 性能数据基于 50 次稳态运行 的最佳结果(最短运行时间)。
- 使用 AntTracks 工具进行细粒度内存行为分析。该工具通过直接修改 HotSpot VM 内核来记录内存事件,其 运行时开销极低(约 4%),且能保证 对象级精度 和 完整追踪,有效避免了传统监控工具的 observer effect(观察者效应)。
结果数据分析
- 分配行为 (Allocation Behavior):
- 总分配量:
factorie,serial,tmt,sunflow(SPECjvm2008) 和derby是分配最密集的基准,其中factorie和sunflow单次迭代可分配高达 137GB 和 134GB 的内存。 - 分配速率:
derby,serial,tmt,factorie和xml.transform具有最高的对象分配速率,可达 3 * 10^7 对象/秒。 - 对象布局:
scimark.fft.large分配的对象平均尺寸最大。数组对象比例差异巨大,从sunflow的 3.2% 到mpegaudio的 97.5%。SPECjvm2008 套件普遍具有更高的 平均数组长度。
- 总分配量:
- 分配子系统 (Allocating Subsystems):
- 绝大多数基准的分配都发生在 C2 编译代码 中,表明预热充分。例外是 SPECjvm2008 中的
scimark.*基准,因其计算密集、分配稀疏,仍有相当一部分分配发生在 解释执行 或 C1 编译代码 中。 lusearch和pmd基准表现出异常高的 VM-internal allocations(VM内部分配),占比分别达 13.7% 和 ~90%。其根源在于它们在 正常控制流中滥用异常 (Exceptions),导致频繁调用Throwable.fillInStackTrace(),从而触发大量内部数组分配。
- 绝大多数基准的分配都发生在 C2 编译代码 中,表明预热充分。例外是 SPECjvm2008 中的
Figure 3: Objects allocated by VM-internal code, interpreted code, C1 compiled code, or by C2 compiled code respectively (green: 1st top allocator, yellow: 2nd top allocator, red: 3rd top allocator), as well as the time spent compiling in relation to the overall run time
- 垃圾回收行为 (Garbage Collection Behavior):
- GC 次数: 基准间的 GC 次数差异极大,从
scimark.fft.large的 0 次 到lusearch的 7041 次。G1 GC 通常比 ParallelOld GC 执行更少的 GC 次数,因为它能更智能地选择回收区域。 - GC 时间: 一些基准(如
factorie)在 ParallelOld GC 下花费超过 40% 的总运行时间在 GC 上,而 G1 GC 能将其显著降低至 1.4%。 - GC 暂停: G1 GC 的平均 minor pause time 仅为 ParallelOld GC 的 71%,并且暂停时间更稳定,尖峰更少。例如,
h2基准在 ParallelOld 下的平均暂停时间为 300ms,而在 G1 下仅为 81ms。
- GC 次数: 基准间的 GC 次数差异极大,从
- 对象引用 (Object References):
- 大多数基准的 每个对象的平均指针数 接近 1。但
xalan,luindex,factorie,kiama和serial因使用少量巨型对象数组而表现出很高的 指针密度。h2数据库基准因其复杂的对象图结构,在指针相关测量中尤为突出。
- 大多数基准的 每个对象的平均指针数 接近 1。但
Figure 8: Object pointers per GC of all benchmarks
消融实验
- 本文未进行传统意义上的“消融实验”(即移除模型组件以验证其贡献)。然而,研究通过 系统性地改变实验变量 来隔离和分析不同因素的影响,这起到了类似的作用:
- GC 算法对比: 通过在 ParallelOld GC 和 G1 GC 下运行相同的基准,清晰地展示了不同 GC 策略对 GC 次数、GC 时间 和 暂停时间 的影响。
- 堆大小敏感性分析: 论文附录提供了在 固定 1GB 堆 和 无限制堆 下的 GC 行为数据,与主文中的 3倍 live size 设置形成对比,揭示了堆大小对 GC 行为的显著影响。例如,G1 GC 在小堆(如某些
scimark基准)下表现不佳,会触发紧急的 major collection。
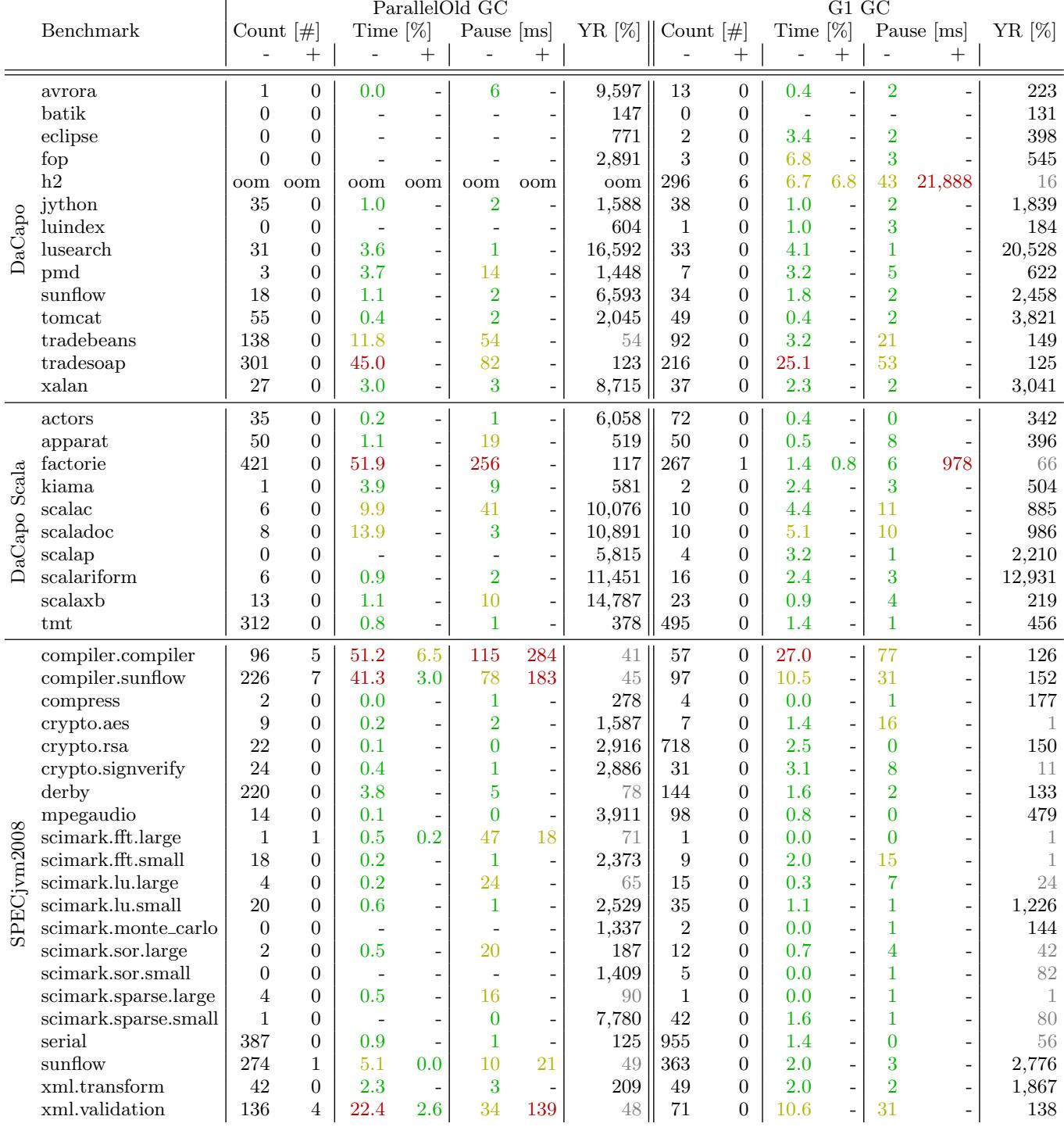
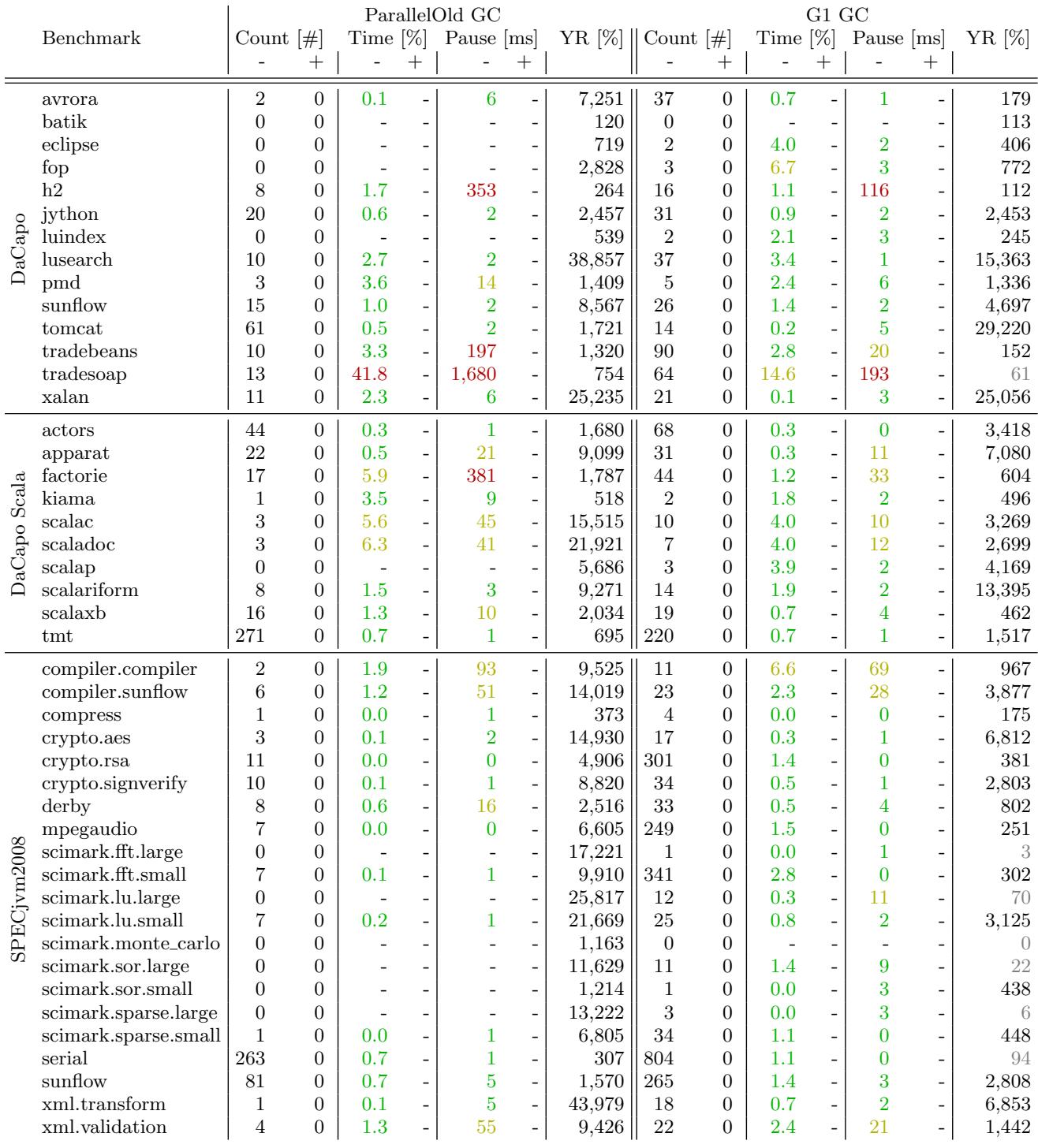 Figure 10: GC count, GC time relative to the total run time (green: less than 5%, yellow: less than 15%, red: more than 15%), and average pause time for minor (-) and major (+) GCs for the ParallelOld GC and the G1 GC respectively (green: less than 10ms, yellow: less than 100ms, red: more than 100ms) (heap unlimited)
Figure 10: GC count, GC time relative to the total run time (green: less than 5%, yellow: less than 15%, red: more than 15%), and average pause time for minor (-) and major (+) GCs for the ParallelOld GC and the G1 GC respectively (green: less than 10ms, yellow: less than 100ms, red: more than 100ms) (heap unlimited)